一、PCM文件
PCM文件:模拟音频信号经模数转换(A/D变换)直接形成的二进制序列,该文件没有附加的文件头和文件结束标志。Windows的Convert工具能够把PCM音频格式的文件转换成Microsoft的WAV格式的文件。
将音频数字化:事实上就是将声音数字化。最常见的方式是透过脉冲编码调制PCM(Pulse Code Modulation) 。
运作原理例如以下:首先我们考虑声音经过麦克风,转换成一连串电压变化的信号。例如以下图所看到的。这张图的横座标为秒。纵座标为电压大小。要将这种信号转为 PCM 格式的方法,是使用三个參数来表示声音。它们是:声道数、採样位数和採样频率。
採样频率:即取样频率,指每秒钟取得声音样本的次数。採样频率越高,声音的质量也就越好,声音的还原也就越真实,但同一时候它占的资源比較多。因为人耳的分辨率非常有限,太高的频率并不能分辨出来。在16位声卡中有22KHz、44KHz等几级,当中,22KHz相当于普通FM广播的音质,44KHz已相当于CD音质了,眼下的经常使用採样频率都不超过48KHz。
採样值或取样值(就是将採样样本幅度量化):它是用来衡量声音波动变化的一个參数。也能够说是声卡的分辨率。它的数值越大,分辨率也就越高。所发出声音的能力越强。
声道数:非常好理解,有单声道和立体声之分,单声道的声音仅仅能使用一个喇叭发声(有的也处理成两个喇叭输出同一个声道的声音)。立体声的PCM 能够使两个喇叭都发声(一般左右声道有分工) ,更能感受到空间效果。
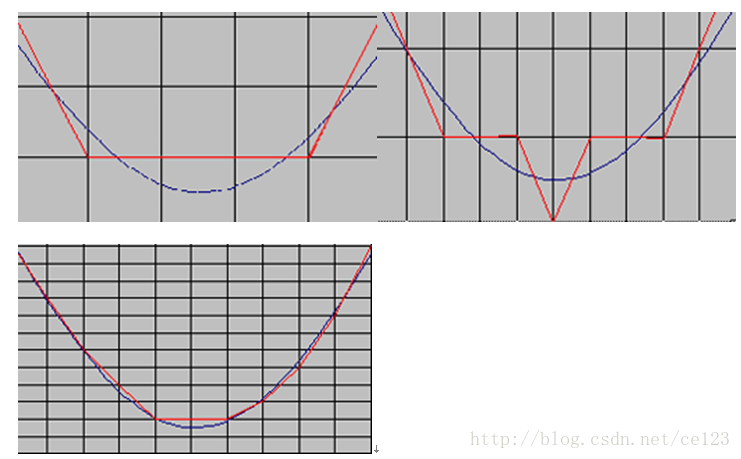
以下再用图解来看看採样位数和採样频率的概念。让我们来看看这几幅图。图中的黑色曲线表示的是PCM 文件录制的自然界的声波,红色曲线表示的是PCM 文件输出的声波。横坐标便是採样频率;纵坐标便是採样位数。这几幅图中的格子从左到右,逐渐加密,先是加大横坐标的密度,然后加大纵坐标的密度。显然,当横坐标的单位越小即两个採样时刻的间隔越小。则越有利于保持原始声音的真实情况,换句话说,採样的频率越大则音质越有保证;同理,当纵坐标的单位越小则越有利于音质的提高。即採样的位数越大越好。
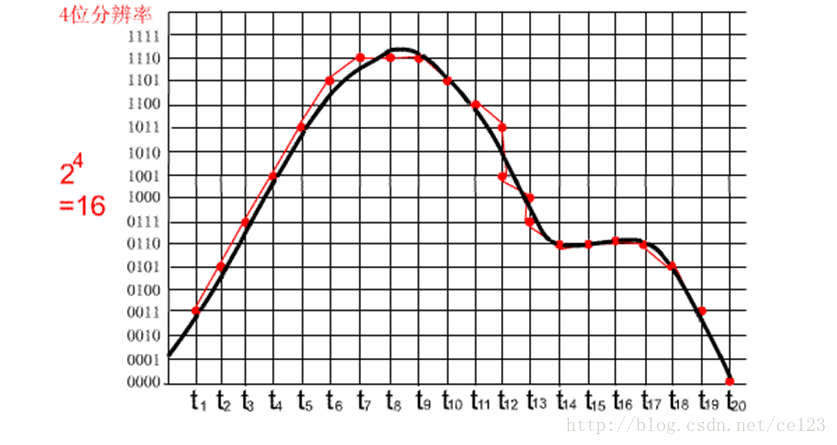
在计算机中採样位数一般有8位和16位之分。但有一点请大家注意,8位不是说把纵坐标分成8份,而是分成2的8次方即256份; 同理16位是把纵坐标分成2的16次方65536份; 而採样频率一般有11025HZ(11KHz),22050HZ(22KHz)、44100Hz(44KHz)三种。
那么,如今我们就能够得到PCM文件所占容量的公式:存储量 = (採样频率*採样位数*声道)*时间/8(单位:字节数).比如,数字激光唱盘(CD-DA。红皮书标准)的标准採样频率为44.lkHz。採样数位为16位,立体声(2声道),能够差点儿无失真地播出频率高达22kHz的声音,这也是人类所能听到的最高频率声音。
激光唱盘一分钟音乐须要的存储量为:
(44.1*1000*l6*2)*60/8=10。584。000(字节)=10.584MBytes
这个数值就是PCM声音文件在硬盘中所占磁盘空间的存储量。
计算机音频文件的格式决定了其声音的品质,日常生活中电话、收音机等均为模拟音频信号。即不存在採样频率和採样位数的概念,我们能够这样比較一下:
44KHz,16BIT的声音称作:CD音质;
22KHz、16Bit的声音效果近似于立体声(FM Stereo)广播。称作:广播音质;
11kHz、8Bit的声音,称作:电话音质。

音频参数
经常见到这样的描述: 44100HZ 16bit stereo 或者 22050HZ 8bit mono 等等.
- 44100HZ 16bit stereo:
每秒钟有 44100 次采样, 采样数据用 16 位(2字节)记录, 双声道(立体声);
- 22050HZ 8bit mono:
每秒钟有 22050 次采样, 采样数据用 8 位(1字节)记录, 单声道;
什么是PCM音频数据
PCM(Pulse Code Modulation)也被称为脉冲编码调制。
PCM音频数据是未经压缩的音频采样数据裸流,它是由模拟信号经过采样、量化、编码转换成的标准的数字音频数据。
PCM数据存储格式
PCM数据存储格式

本文中声音样值的采样频率一律是44100Hz,采样格式一律为16LE。
“16”代表采样位数是16bit。由于1Byte=8bit,所以一个声道的一个采样值占用2Byte。
“LE”代表Little Endian,代表2 Byte采样值的存储方式为高位存在高地址中。
立体声的左右声道的数据是一样的吗?
原来一直理解立体声的左右声道是一样的,但是通过查看实际的数据,发现并不一样。比如:

从以上可以看出,刚开始的4个字节是同一个采样点,其中0x04e8是左声道,0x01c9是右声道,发现是不一样的。
通过cool edit pro查看波形:

可以看出左右声道,虽然波形相似,但是的确存在不同。
二、WAV文件
FileSize = HeadSize + TimeInSecond * SampleRate * Channels * BitsPerSample / 8
2、其中HeadSize为WAV文件头部长度;SampleRate,即采样率,可选8000、16000、32000、44100或48000;Channels表示声道数量,通常为1或2;BitsPerSample代表单个Sample的位深,可选8、16以及32,其中32位时可以是float类型。
WAV是一种极其简单的文件格式,如果对其结构足够熟悉,完全可以自己通过代码写入WAV文件,从而免去引入一些复杂中间库。特别是在对音频进行调试的时候,能提高效率,降低复杂度。
WAV格式遵循RIFF规范,所有WAV都有一个文件头,记录着音频流的采样和编码信息。数据块的记录方式是小尾端(little-endian)。
三、RIFF
RIFF,全称Resource Interchange File Format,是一种按照标记区块存储数据的通用文件存储格式,多用于存储音频、视频等多媒体数据。Microsoft在Windows下的WAV、AVI等都是基于RIFF实现的。
一个标准的RIFF规范规范文件,最小存储单位为“块”(Chunk),每个块(Chunk)包含以下三个信息:
| 名称 | 大小 | 类型 | 端序 | 含义 |
|---|---|---|---|---|
| FOURCC | 4 | 字符 | 大端 | 用于标识Chunk ID或chunk 类型,通常为Chunk ID |
| Data Field Size | 4 | 整形 | 小端 | 特别注意,该长度不包含其本身,以及FOURCC |
| Data Field | - | - | - | 数据域,如果Chunk ID为"RIFF"或"LIST",则开始四个字节为类型码 |
只有ID为"RIFF"或者"LIST"的块允许拥有子块(SubChunk)。RIFF文件的第一个块的ID必须是"RIFF",也就是说ID为"LIST"的块只能是子块(SubChunk),他们和各个子块形成了复杂的RIFF文件结构。
RIFF数据域的的起始位置四个字节为类型码(Form Type),用于说明数据域的格式,比如WAV文件的类型码为"WAVE"。
"LIST"块的数据域的起始位置也有一个四字节类型码(List Type),用于说明LIST数据域的数据内容。比如,类型码为"INFO"时,其数据域可能包括"ICOP"、"ICRD"块,用于记录文件版权和创建时间信息。
四、WAV
以最简单的无损WAV格式文件为例,此时文件的音频数据部分为PCM,比较简单,重点在于WAV头部。一个典型的WAV文件头部长度为44字节,包含了采样率,通道数,位深等信息,如下表所示。
| 偏移位置 | 大小 | 类型 | 端序 | 含义 |
|---|---|---|---|---|
| 0x00-0x03 | 4 | 字符 | 大端 | "RIFF"块(0x52494646),标记为RIFF文件格式 |
| 0x04-0x07 | 4 | 整型 | 小端 | 块数据域大小(Chunk Size),即从下一个地址开始,到文件末尾的总字节数,或者文件总字节数-8。从0x08开始一直到文件末尾,都是ID为"RIFF"块的内容,其中会包含两个子块,"fmt "和"data" |
| 0x08-0x0B | 4 | 字符 | 大端 | 类型码(Form Type),WAV文件格式标记,即"WAVE"四个字母 |
| 0x0C-0x0F | 4 | 字符 | 大端 | "fmt "子块(0x666D7420),注意末尾的空格 |
| 0x10-0x13 | 4 | 整形 | 小端 | 子块数据域大小(SubChunk Size) |
| 0x14-0x15 | 2 | 整形 | 小端 | 编码格式(Audio Format),1代表PCM无损格式 |
| 0x16-0x17 | 2 | 整形 | 小端 | 声道数(Channels),1或2 |
| 0x18-0x1B | 4 | 整形 | 小端 | 采样率(Sample Rate) |
| 0x1C-0x1F | 4 | 整形 | 小端 | 传输速率(Byte Rate),每秒数据字节数,SampleRate * Channels * BitsPerSample / 8 |
| 0x20-0x21 | 2 | 整形 | 小端 | 每个采样所需的字节数BlockAlign,BitsPerSample*Channels/8 |
| 0x22-0x23 | 2 | 整形 | 小端 | 单个采样位深(Bits Per Sample),可选8、16或32 |
| 0x24-0x27 | 4 | 字符 | 大端 | "data"子块 (0x64617461) |
| 0x28-0x2B | 4 | 整形 | 小端 | 子块数据域大小(SubChunk Size) |
| 0x2C-eos | N | PCM |
上表为典型的WAV头部格式,从0x00到0x2B总共44字节,从0x2C开始一直到文件末尾都是PCM音频数据。所以如果你已经知道了PCM的采样信息,那么可以直接跳过头部的解析,直接从0x2C开始读取PCM即可,但是对于另一些无损的WAV文件却是不行的。
五、WAV扩展
有一些WAV的头部并不仅仅只有44个字节,比如通过FFmpge编码而来的WAV文件头部信息通常大于44个字节。这是因为根据WAV规范,其头部还支持携带附加信息,所以只按照44个字节的长度去解析WAV头部信息是不一定正确的,还需要考虑附加信息。那么如何知道一个WAV文件头部是否包含附加信息呢?
根据"fmt "子块长度来判断即可。
如果fmt SubChunk Size等于0x10(16),表示头部不包含附加信息,即WAV头部信息长度为44;如果等于0x12(18),则包含附加信息,此时头部信息长度大于44。
当WAV头部包含附加信息时,fmt SubChunk Size长度为18,并且紧随是另一个子块,这个包含了一些自定义的附加信息,接着往下才是"data"子块,格式如下:
| 偏移位置 | 大小 | 类型 | 端序 | 含义 |
|---|---|---|---|---|
| 0x00-0x03 | 4 | 字符 | 大端 | "RIFF"块(0x52494646),标记为RIFF文件格式 |
| 0x04-0x07 | 4 | 整型 | 小端 | 块数据域大小(Chunk Size),即从下一个地址开始,到文件末尾的总字节数,或者文件总字节数-8。从0x08开始一直到文件末尾,都是ID为"RIFF"块的内容,其中会包含两个子块,"fmt "和"data" |
| 0x08-0x0B | 4 | 字符 | 大端 | 类型码(Form Type),WAV文件格式标记,即"WAVE"四个字母 |
| 0x0C-0x0F | 4 | 字符 | 大端 | "fmt "子块(0x666D7420),注意末尾的空格 |
| 0x10-0x13 | 4 | 整形 | 小端 | 子块数据域大小(SubChunk Size),这里为0x12 |
| 0x14-0x15 | 2 | 整形 | 小端 | 编码格式(Audio Format),1代表PCM无损格式 |
| 0x16-0x17 | 2 | 整形 | 小端 | 声道数(Channels),1或2 |
| 0x18-0x1B | 4 | 整形 | 小端 | 采样率(Sample Rate) |
| 0x1C-0x1F | 4 | 整形 | 小端 | 传输速率(Byte Rate),每秒数据字节数,SampleRate * Channels * BitsPerSample / 8 |
| 0x20-0x21 | 2 | 整形 | 小端 | 每个采样所需的字节数BlockAlign,BitsPerSample*Channels/8 |
| 0x22-0x23 | 2 | 整形 | 小端 | 单个采样位深(Bits Per Sample),可选8、16或32 |
| 0x24-0x25 | 2 | |||
| 0x26-不定 | - | - | - | 可选附加信息,标准RIFF Chunk |
| 不定 | 4 | 字符 | 大端 | "data"子块 (0x64617461) |
| 不定 | 4 | 整形 | 小端 | 子块数据域大小(SubChunk Size) |
| 不定 | N | PCM |
如果一个无损WAV文件头部包含了附加信息,那么PCM音频所在的位置就不确定了,但由于附加信息也是一个子块(SubChunk),根据RIFF规范,该子块也必然记录着其长度信息,所以我们还是有办法能够动态计算出其位置,下面是计算步骤:
- 判断fmt块长度是否为18。
- 如果fmt长度为18,那么必然从0x26位置开始为附加信息块,0x30-0x33位置记录着该子块长度。
- 根据步骤2获取的子块长度,假定为N(16进制),那么PCM音频信息开始位置为:0x34 + N + 8。
六、补充
WAVE文件支持很多不同的比特率、采样率、多声道音频。WAVE是PC机上存储PCM音频最流行的文件格式,基本上可以等同于原始数字音频。
WAVE文件为了与IFF保持一致,数据采用“chunk”来存储。因此,如果想要在WAVE文件中补充一些新的信息,只需要在在新chunk中添加信息,而不需要改变整个文件。这也是设计IFF最初的目的。
WAVE文件是很多不同的chunk集合,但是对于一个基本的WAVE文件而言,以下三种chunk是必不可少的。
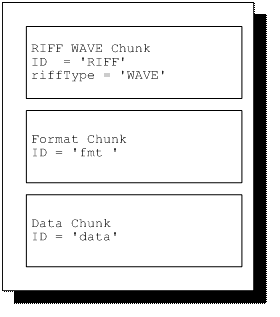
使用WAVE文件的应用程序必须具有读取以上三种chunk信息的能力,如果程序想要复制WAVE文件,必须拷贝文件中所有的chunk。
文件中第一个chunk是RIFFchunk,然后是fmtchunk,最后是datachunk。对于其他的chunk,顺序没有严格的限制。
以下是一个最基本的WAVE文件,包含三种必要chunk。
文件组织形式:
1. 文件头
RIFF/WAV文件标识段
声音数据格式说明段
2. 数据体:
由 PCM(脉冲编码调制)格式表示的样本组成。

描述WAVE文件的基本单元是“sample”,一个sample代表采样一次得到的数据。因此如果用44KHz采样,将在一秒中得到44000个sample。每个sample可以用8位、24位,甚至32位表示(位数没有限制,只要是8的整数倍即可),位数越高,音频质量越好。
此处有一个值得注意的细节,8位代表无符号的数值,而16位或16位以上代表有符号的数值。例如,如果有一个10bit的样本,由于sample位数要求是8的倍数,我们就需要把它填充到16位。16位中:0-5位补0,6-15位是原始的10bit数据。这就是左补零对齐原则。
上述只是单声道,如果要处理多声道,就需要在任意给定时刻给出多个sameple。例如,在多声道中,给出某一时刻,我们需要分辨出哪些sample是左声道的,哪些sample是右声道的。因此,我们需要一次读写两个sample.
假如以44KHz取样立体声音频,我们需要一秒读写44*2 KHz的sample. 给出公式:
每秒数据大小(字节)=采样率 * 声道数 * sample比特数 / 8
处理多声道音频时,每个声道的样本是交叉存储的。我们把左右声道数据交叉存储在一起:先存储第一个sample的左声道数据,然后存储第一个sample的右声道数据。
当一个设备需要重现声音时,它需要同时处理多个声道,一个sample中多个声道信息称为一个样本帧。
七、实例分析

(1)“52 49 46 46”这个是Ascii字符“RIFF”,这部分是固定格式,表明这是一个WAVE文件头。
(2)“22 60 28 00”,这个是我这个WAV文件的数据大小,这个大小包括除了前面4个字节的所有字节,也就等于文件总字节数减去8。16进制的“22 60 28 00”对应是十进制的“2646050”。
(3)“57 41 56 45 66 6D 74 20”,也是Ascii字符“WAVEfmt”,这部分是固定格式。
以后是PCMWAVEFORMAT部分
(4)“12 00 00 00”,这是一个DWORD,对应数字18,这个对应定义中的PCMWAVEFORMAT部分的大小,可以看到后面的这个段内容正好是18个字节。一般情况下大小为16,此时最后附加信息没有,上面这个文件多了两个字节的附加信息。
(5)“01 00”,这是一个WORD,对应定义为编码格式(WAVE_FORMAT_PCM格式一般用的是这个)。
(6)“01 00”,这是一个WORD,对应数字1,表示声道数为1,是个单声道Wav。
(7)“22 56 00 00”对应数字22050,代表的是采样频率22050,采样率(每秒样本数),表示每个通道的播放速度
(8)“44 AC 00 00”对应数字44100,代表的是每秒的数据量,波形音频数据传送速率,其值为通道数×每秒样本数×每样本的数据位数/8(1*22050*16/8)。播放软件利用此值可以估计缓冲区的大小。
(9)“02 00”对应数字是2,表示块对齐的内容。数据块的调整数(按字节算的),其值为通道数×每样本的数据位值/8。播放软件需要一次处理多个该值大小的字节数据,以便将其值用于缓冲区的调整。
(10)“10 00”数值为16,采样大小为16Bits,每样本的数据位数,表示每个声道中各个样本的数据位数。如果有多个声道,对每个声道而言,样本大小都一样。
(11)“00 00”此处为附加信息(可选),和(4)中的size对应。
(12)“66 61 73 74” Fact是可选字段,一般当wav文件由某些软件转化而成,则包含该项,“04 00 00 00”Fact字段的大小为4字节,“F8 2F 14 00”是fact数据。
(13)“64 61 74 61”,这个是Ascii字符“data”,标示头结束,开始数据区域。
(14)“F0 5F 28 00”十六进制数是“0x285ff0”,对应十进制2646000,是数据区的开头,以后数据总数,看一下前面正好可以看到,文件大小是2646050,从(2)到(13)包括(13)正好是2646050-2646000=50字节。