由于利用线程池提交任务的操作放到了while循环中,导致利用该线程池循环提交任务,导致任务队列爆满。应该改为线程池提交的子线程中循环处理取处理任务的逻辑。

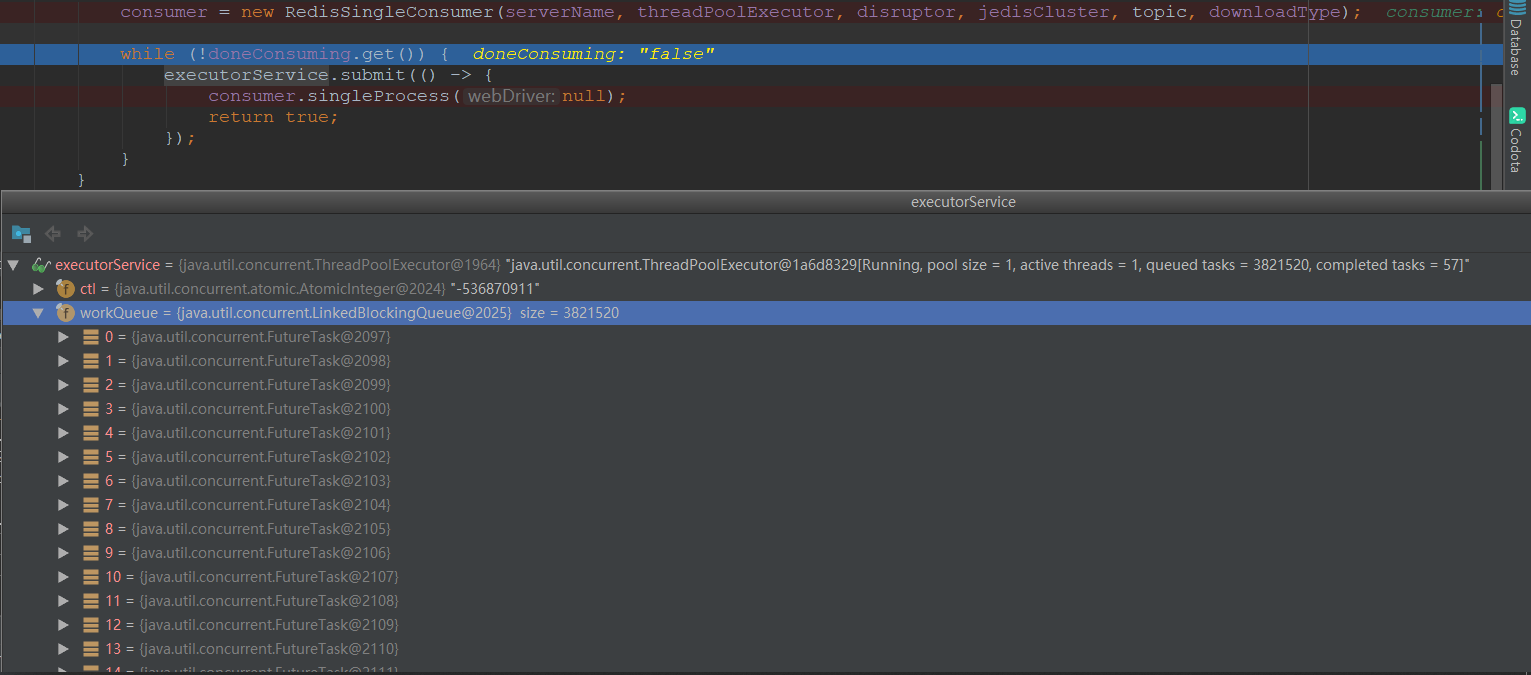

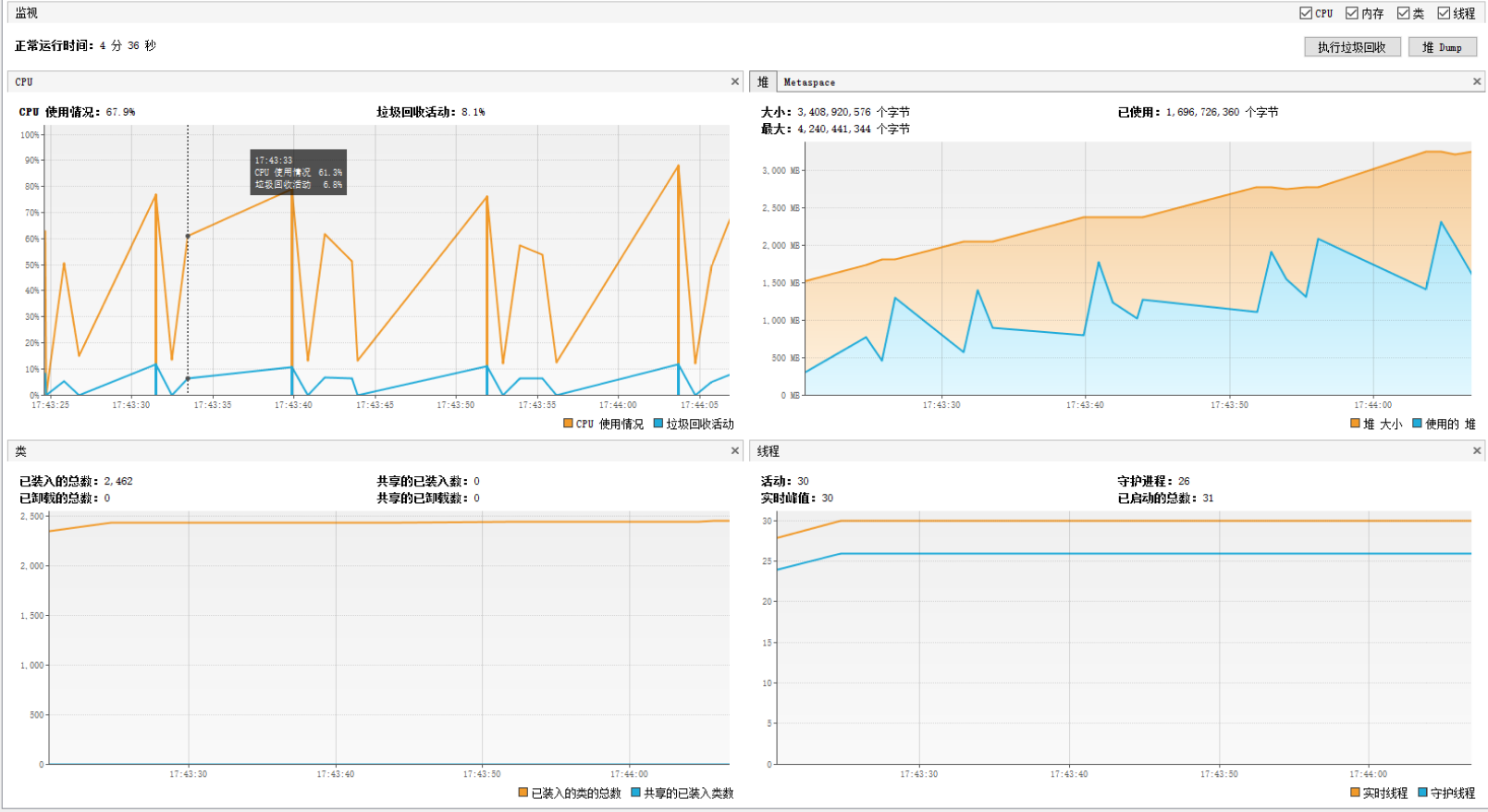
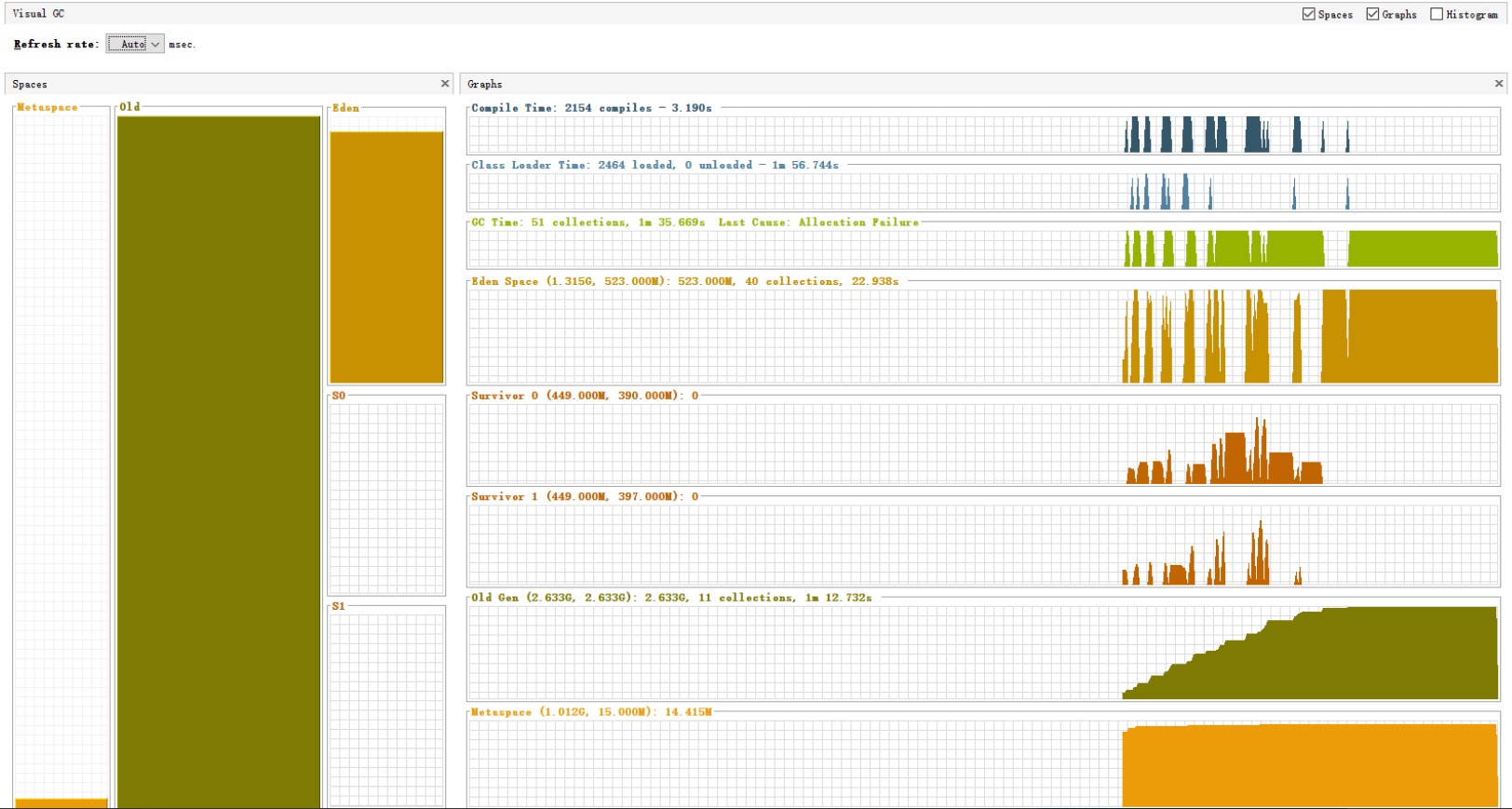
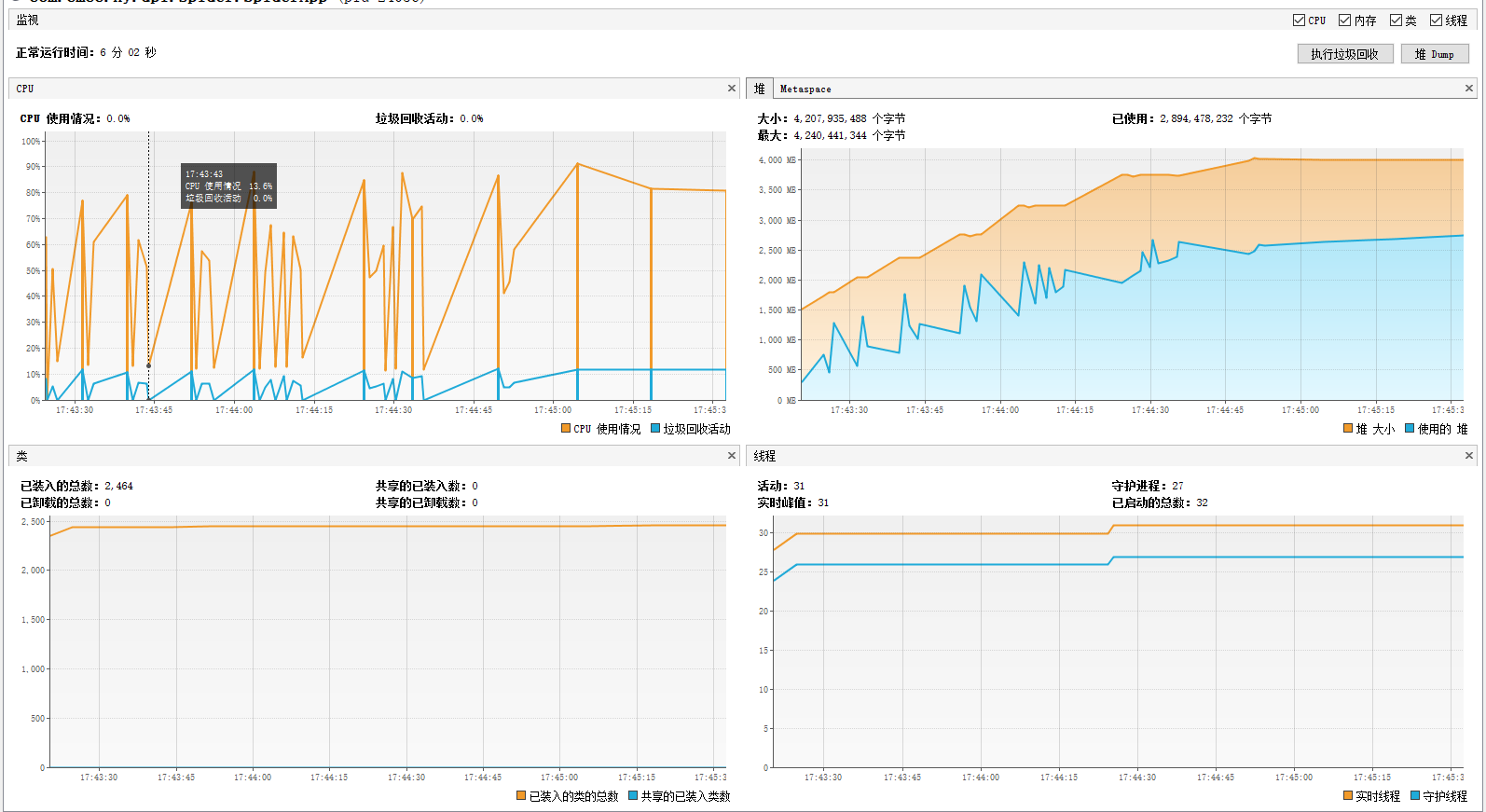
一段时间后线程池中的WorkQueue挤压了4千多条待处理的任务

一种针对大批量数据处理,如从kafka中获取消息然后开多线处理消息的场景,考虑到如果用主线程去从kafka中拿消息可能发生异常,导致线程停止,可以从主线程中创造一个固定长度为1的线程池提交任务去从kafka中取,然后在主线程中检查futuer。这样可以保证如果取从kafka中取消息的线程挂了或者超时了,线程池可以重新创建线程继续处理
class KafkaMessagePublisher{
ExecutorService executorService = Executors.newFixedThreadPool(1);
KafkaBatchConsumer tcConsumer = new KafkaBatchConsumer();
//判断开关变量
while (!doneConsuming.get()) {
Future future = executorService.submit(() -> {
tcConsumer.batchProcess();
return true;
});
try {
future.get(40, TimeUnit.SECONDS);
} catch (Exception e) {
boolean cancelFlag = future.cancel(true);
logger.warn(Thread.currentThread().getName() + "->>KafkaMessagePublisher cancelFlag:" + cancelFlag + ";future isCancelled:" + future.isCancelled()
+ ";" + threadPoolExecutor.toString(), e);
}
}
}
class KafkaBatchConsumer{
public void batchProcess() {
final String batchUUID = UUID.randomUUID().toString();
try {
ConsumerRecords<String, String> records = consumer.poll(1000);
logger.info("records num:" + records.count());
if (records.count() > 0) {
for (ConsumerRecord<String, String> record : records) {
MessageTask messageTask = MessageTaskFactory.getInstance(downloadType, record.value(),null);
Future<Boolean> spiderFuture = threadPoolExecutor.submit(messageTask);
//检测各个子线程是否超时
Object[] args = new Object[2];
args[0] = spiderFuture;
args[1] = record.value();
disruptor.publishEvent(new FutureListEventTranslator(), args);
tpAndOffsetMetadata.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1, batchUUID));
}
consumer.commitSync(tpAndOffsetMetadata);
tpAndOffsetMetadata.clear();
}
} catch (Exception e) {
logger.error("KafkaSource EXCEPTION: {}", e);
}
}
}