分析一下do_fork()的源码的主要步骤
1.首次查找_pidmap位图,为新子进程分配新的pid

2.复制进程描述符,返回的是新的进程描述符的地址(struct task_struct *p)

3.初始化完成量,vfrok主要用excv,父进程的虚拟地址空间对其没有用处,所以实现方式为在子进程退出或者替换后父进程才开始执行

4.如果设置了vfork,则调用wait(父进程)
5.free_pidmap(pid):
6.返回子进程pid。
对于第二步,是do_fork的关键
1.检查flag位的合法性
2.为子进程获取进程描述符
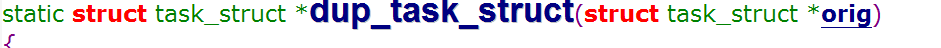
开辟内核栈+thread_info 一般大小为8k
将current的值赋给子进程

3.检查线程数量,设置一些关键字,保存新的pid
4.用系统调用时cpu寄存器中的值初始化新线程,将exa置为0(fork和clone在子进程的返回值)

5.完成一些字段的设置,将新进程加入到链表,将新进程pid加入到散列表

复制父进程每一个vm_area_struct,也复制它的页表,将私有的可写的页都标记为只读,为写时拷贝做准备。

1.判断是否为创建线程,如果是线程,直接使用mm = oldmm ,表示线程公用虚拟地址空间
2.对于非线程,为其创建虚拟地址空间,创建新的局部描述符加入到tsk地址空间,之后调用dup_mmap;
后续需要解决的问题:
1.current是什么
task_struct 包含了进程所有的信息,current是一个宏,由getCurrent()->task替换,此函数内部是一条汇编指令,在x86体系下通过在内核栈尾部插入thread_info结构,计算偏移量,来查找到当前正在运行的进程描述符。
2.用户态fork()->内核态sys_fork()的过程是什么
普通程序调用fork()-->库函数fork()-->系统调用(fork功能号)-->由功能号在 sys_call_table[]中寻到sys_fork()函数地址-->调用sys_fork(),这就完成拉从用户态到内核态的变化过程。
总结一下:
看源码前对fork()只停留在用上,看了之后明白了很多死记硬背的点,也有了自己的理解。主要几个点,fork的返回值,进程和线程的区别,vfork现阶段还暂时没有用过先记住吧,还包括子进程继承父进程的信息,还有写时拷贝的先决条件等。