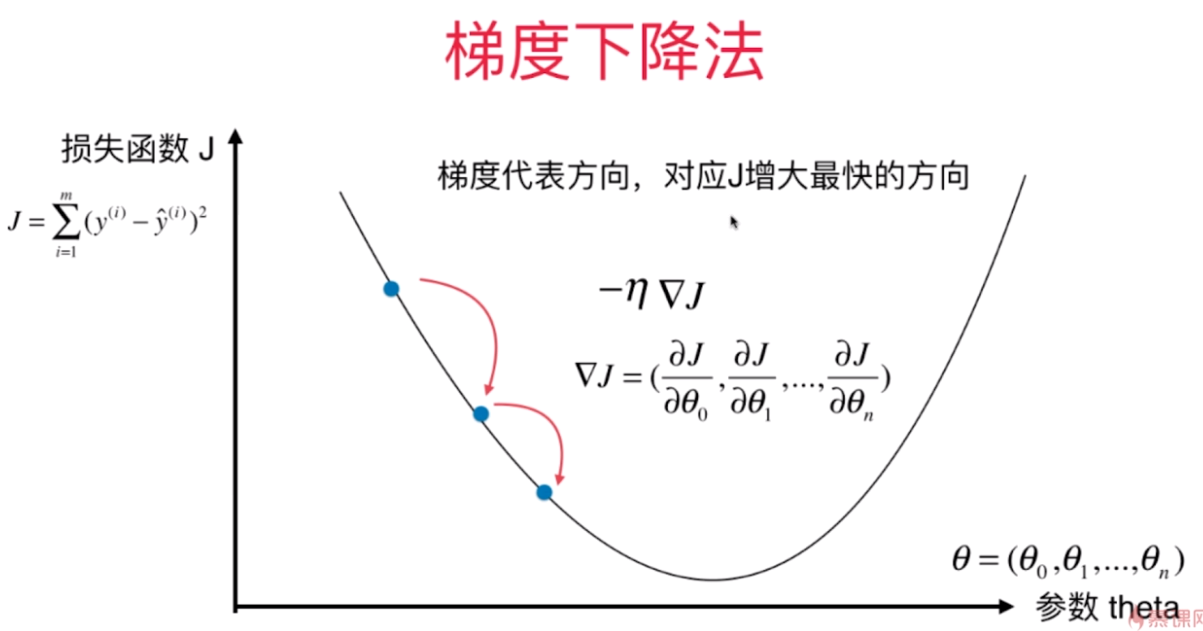
一、什么是梯度下降法
梯度下降法 Gradient Descent
1.不是一个机器学习算法
2.是一种基于搜索的最优化方法
3.作用:最小化一个损失函数
4.梯度上升法:最大化一个效用函数

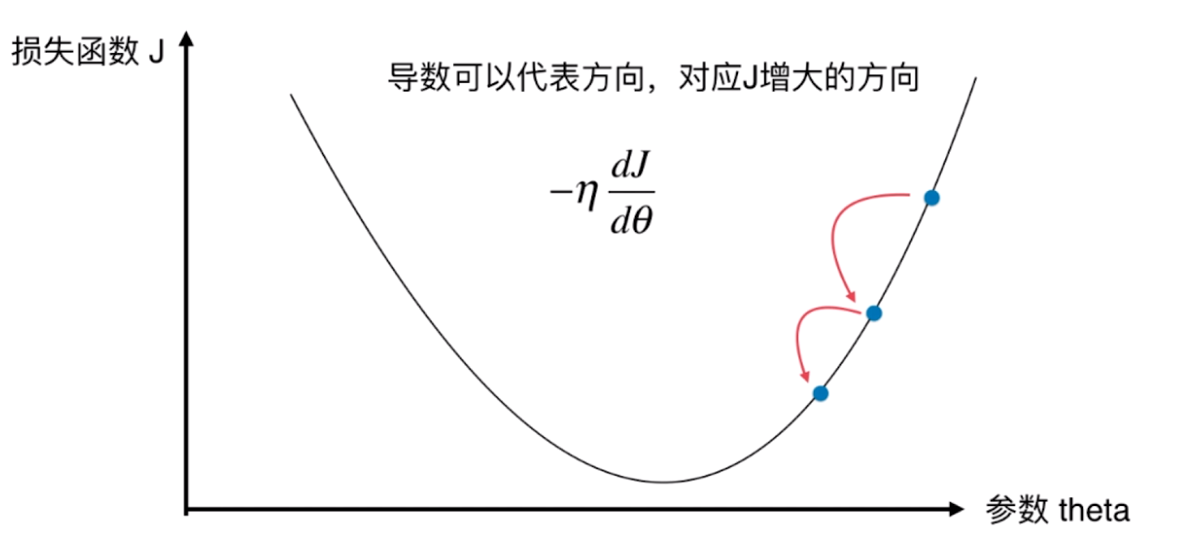

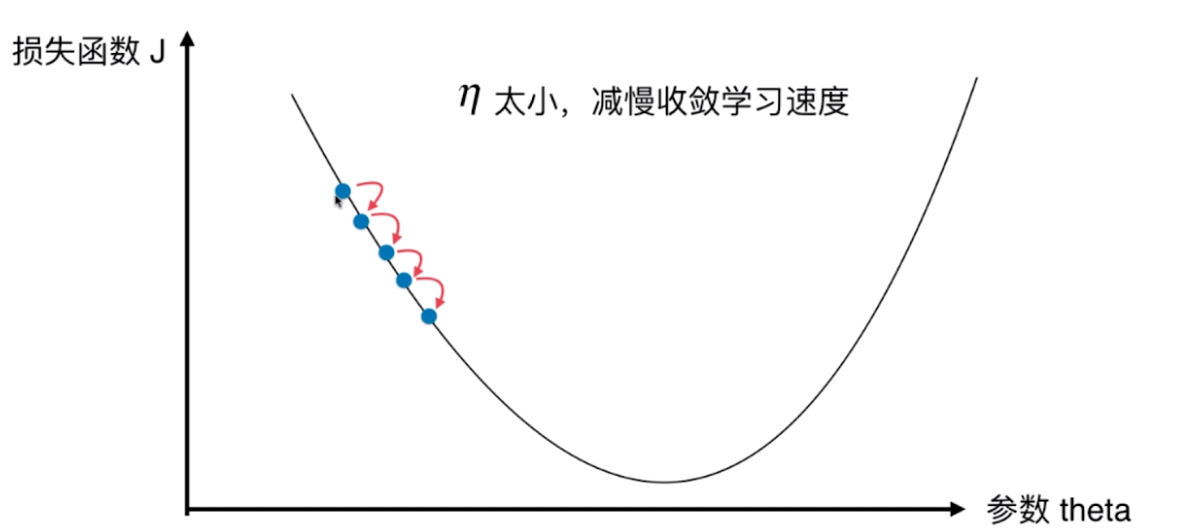
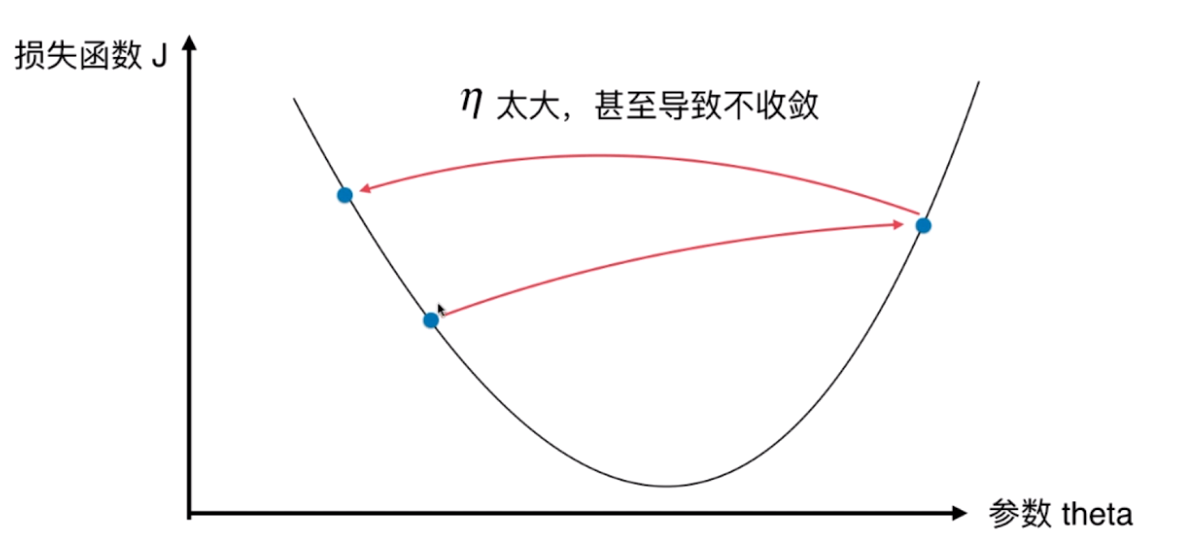
并不是所有函数都有唯一的极值点
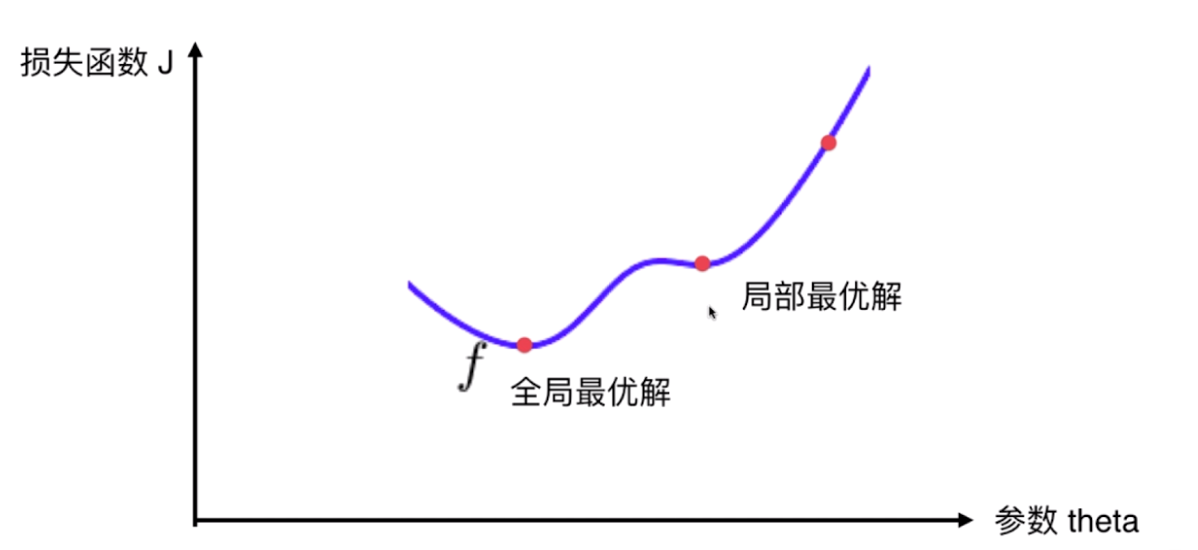


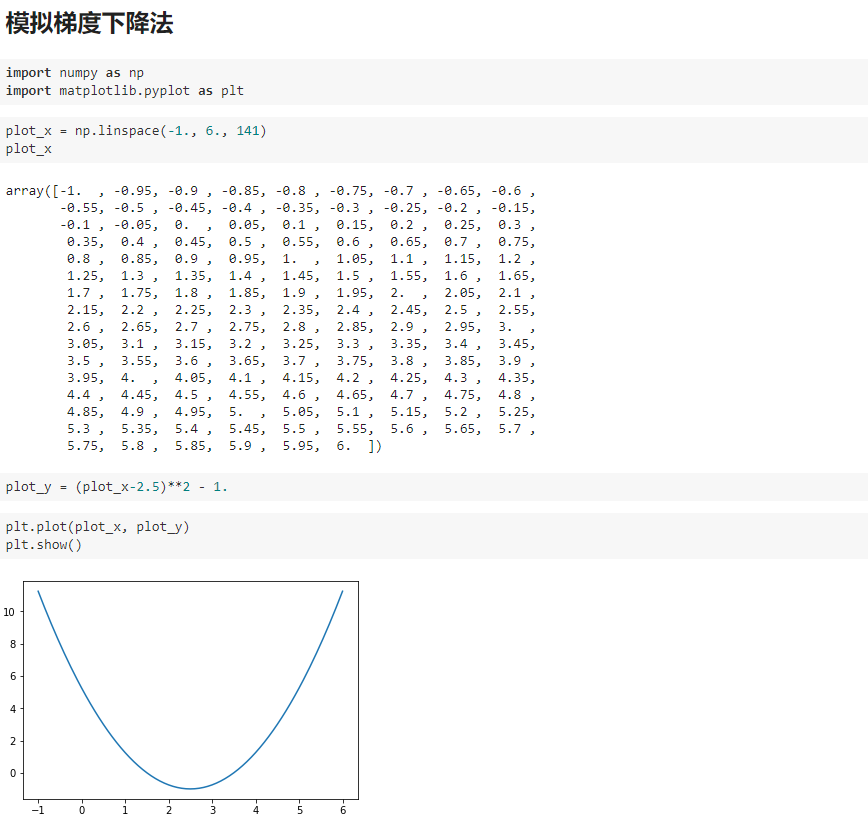
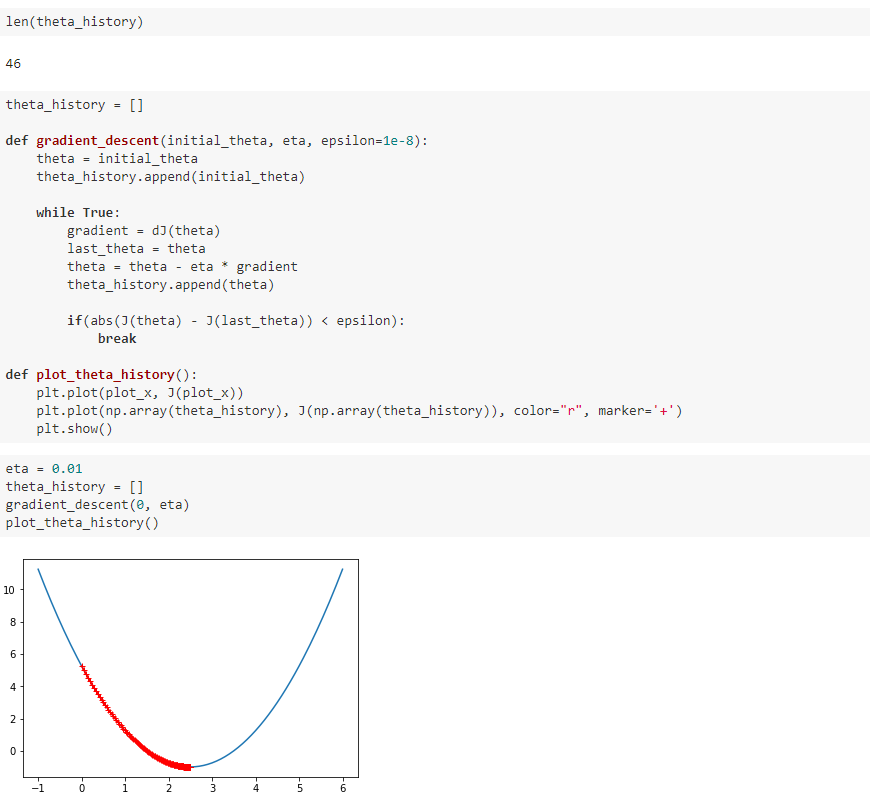
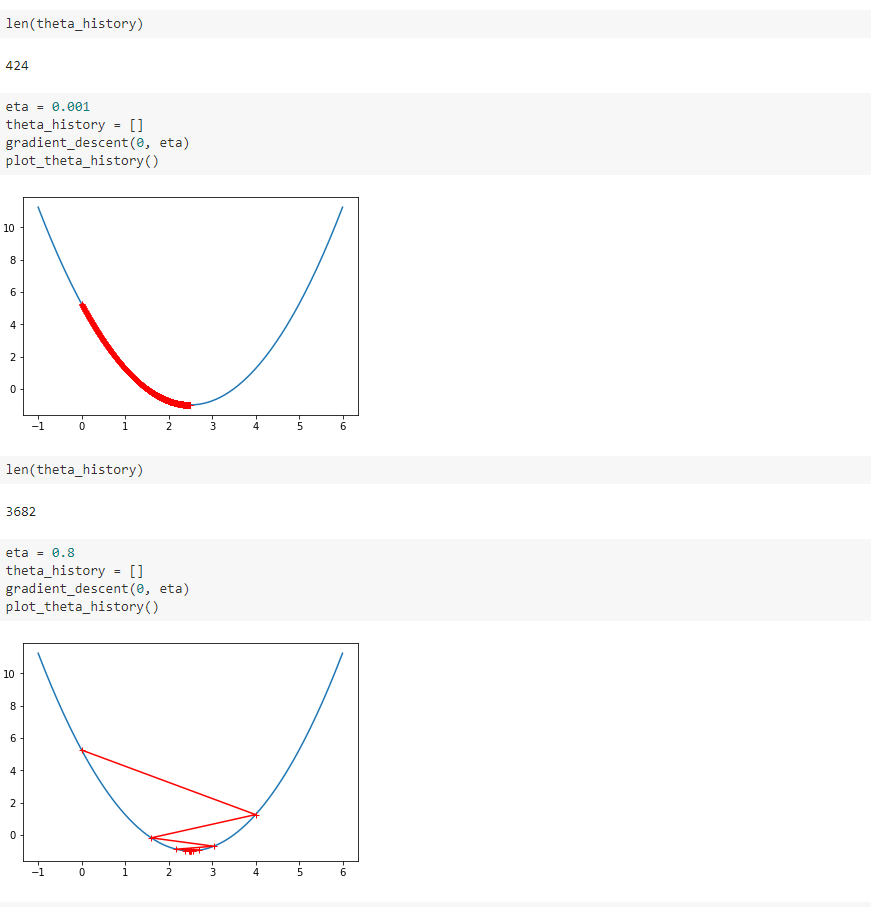
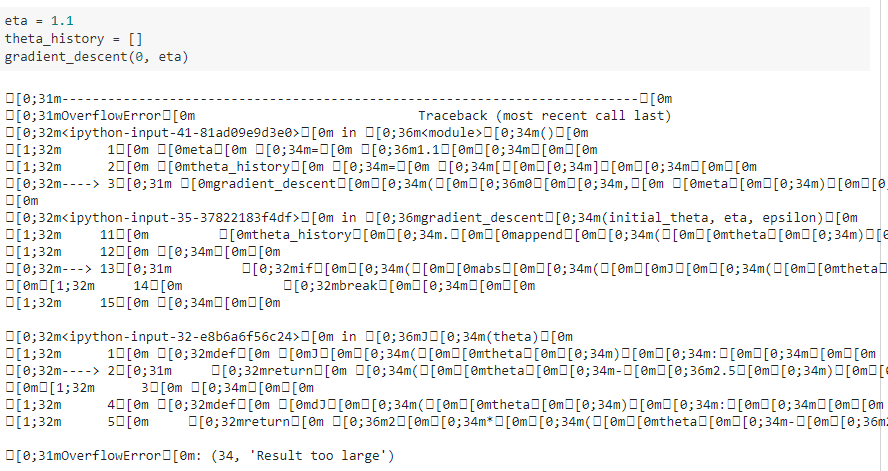
二、模拟梯度下降法

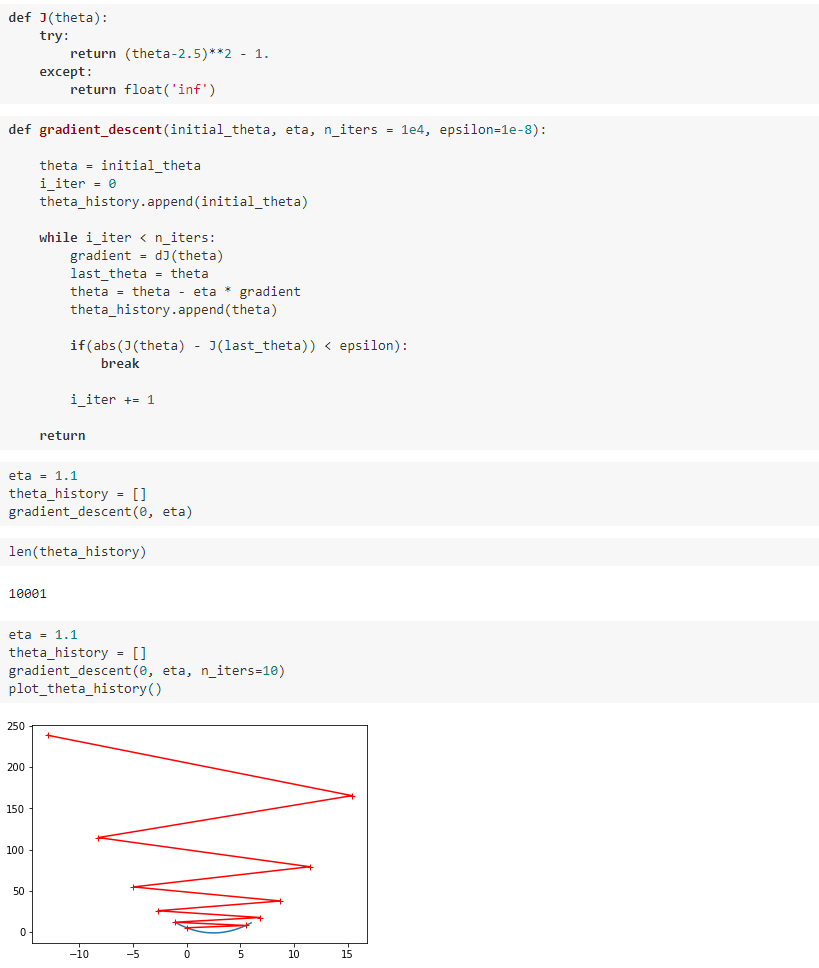
三、线性回归中的梯度下降法
多元线性回归中的梯度下降法
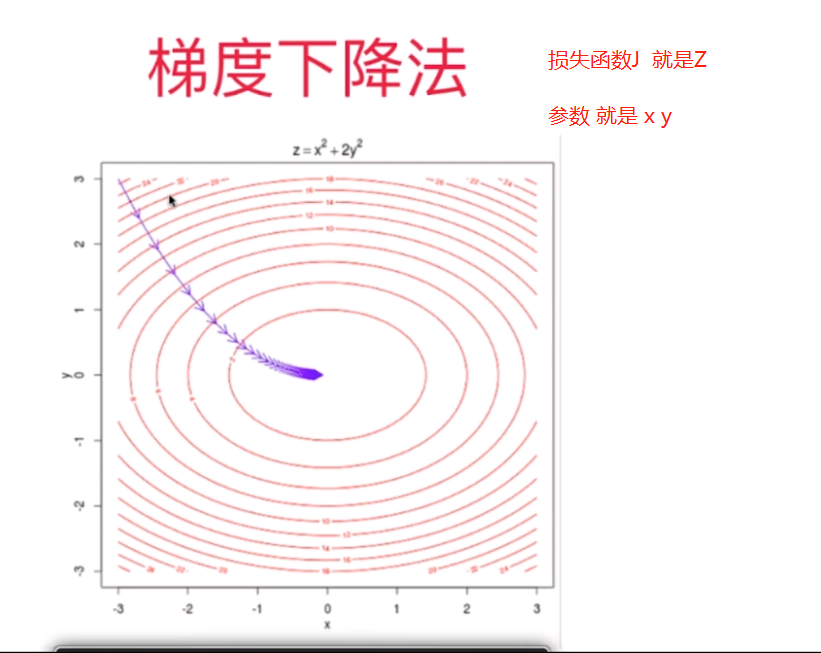



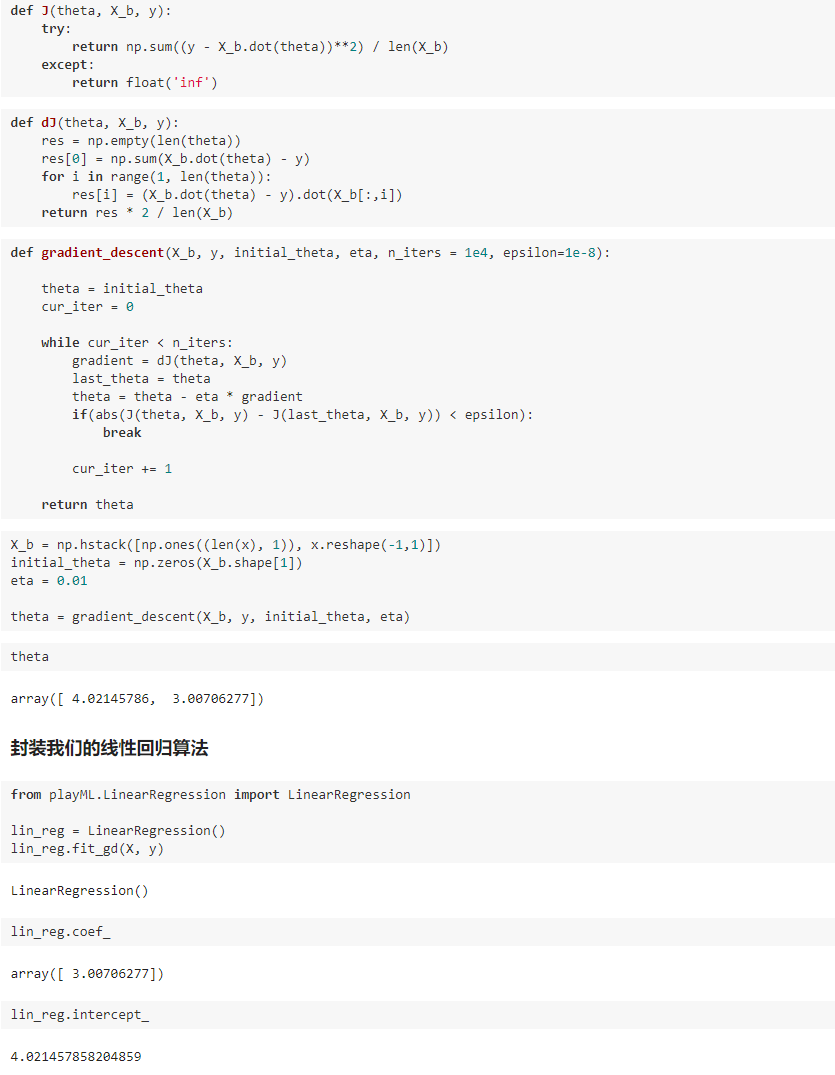
四、实现线性回归中的梯度下降法
playML.LinearRegression.py
import numpy as np from .metrics import r2_score class LinearRegression: def __init__(self): """初始化Linear Regression模型""" self.coef_ = None self.intercept_ = None self._theta = None def fit_normal(self, X_train, y_train): """根据训练数据集X_train, y_train训练Linear Regression模型""" assert X_train.shape[0] == y_train.shape[0], "the size of X_train must be equal to the size of y_train" X_b = np.hstack([np.ones((len(X_train), 1)), X_train]) self._theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y_train) self.intercept_ = self._theta[0] self.coef_ = self._theta[1:] return self def fit_gd(self, X_train, y_train, eta=0.01, n_iters=1e4): """根据训练数据集X_train, y_train, 使用梯度下降法训练Linear Regression模型""" assert X_train.shape[0] == y_train.shape[0], "the size of X_train must be equal to the size of y_train" def J(theta, X_b, y): try: return np.sum((y - X_b.dot(theta)) ** 2) / len(y) except: return float('inf') def dJ(theta, X_b, y): res = np.empty(len(theta)) res[0] = np.sum(X_b.dot(theta) - y) for i in range(1, len(theta)): res[i] = (X_b.dot(theta) - y).dot(X_b[:, i]) return res * 2 / len(X_b) def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e4, epsilon=1e-8): theta = initial_theta cur_iter = 0 while cur_iter < n_iters: gradient = dJ(theta, X_b, y) last_theta = theta theta = theta - eta * gradient if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon): break cur_iter += 1 return theta X_b = np.hstack([np.ones((len(X_train), 1)), X_train]) initial_theta = np.zeros(X_b.shape[1]) self._theta = gradient_descent(X_b, y_train, initial_theta, eta, n_iters) self.intercept_ = self._theta[0] self.coef_ = self._theta[1:] return self def predict(self, X_predict): """给定待预测数据集X_predict,返回表示X_predict的结果向量""" assert self.intercept_ is not None and self.coef_ is not None, "must fit before predict!" assert X_predict.shape[1] == len(self.coef_), "the feature number of X_predict must be equal to X_train" X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict]) return X_b.dot(self._theta) def score(self, X_test, y_test): """根据测试数据集 X_test 和 y_test 确定当前模型的准确度""" y_predict = self.predict(X_test) return r2_score(y_test, y_predict) def __repr__(self): return "LinearRegression()"
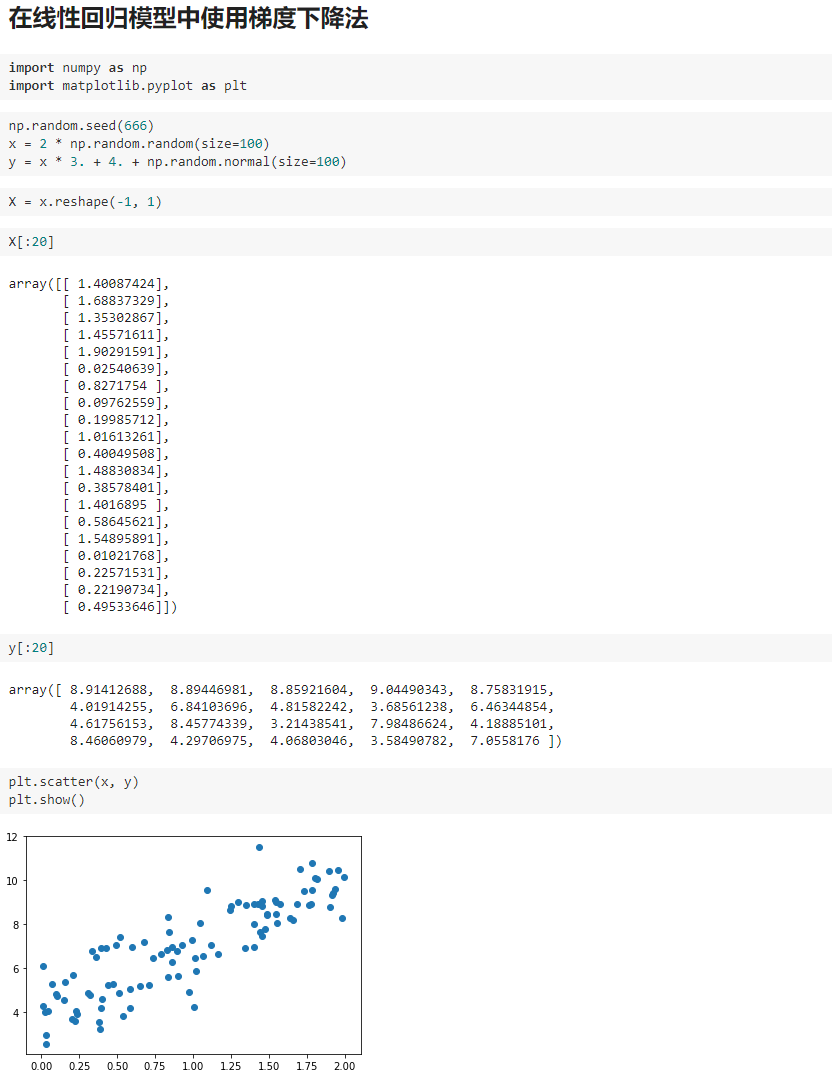

我写的文章只是我自己对bobo老师讲课内容的理解和整理,也只是我自己的弊见。bobo老师的课 是慕课网出品的。欢迎大家一起学习。