模型存储与载入
一、存储、载入体系简介
1.1 接口体系
飞桨框架2.x对模型与参数的存储与载入相关接口进行了梳理,根据接口使用的场景与模式,分为三套体系,分别是:
1.1.1 动态图存储载入体系
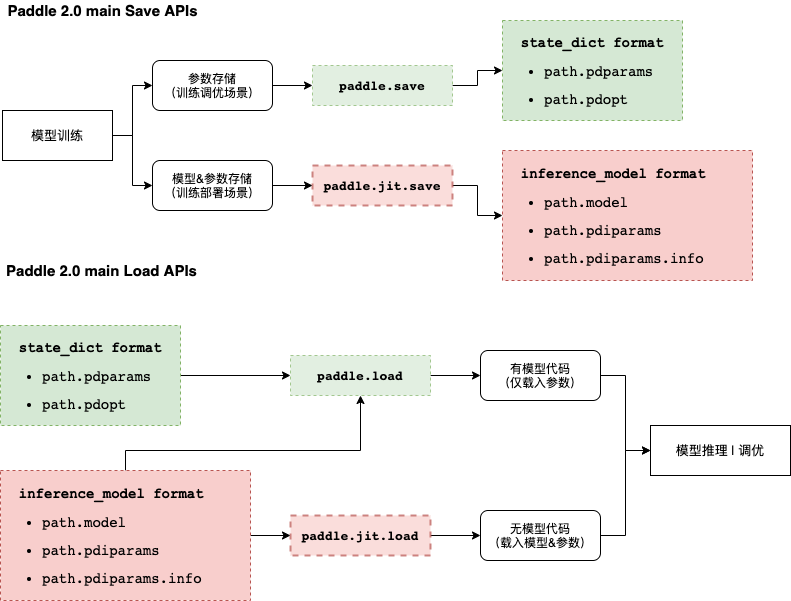
为提升框架使用体验,飞桨框架2.0将主推动态图模式,动态图模式下的存储载入接口包括:
- paddle.save
- paddle.load
- paddle.jit.save
- paddle.jit.load
本文主要介绍飞桨框架2.0动态图存储载入体系,各接口关系如下图所示:
1.1.2 静态图存储载入体系[不再推荐]
静态图存储载入相关接口为飞桨框架1.x版本的主要使用接口,出于兼容性的目的,这些接口仍然可以在飞桨框架2.x使用,但不再推荐。相关接口包括:
- paddle.static.save
- paddle.static.load
- paddle.static.save_inference_model
- paddle.static.load_inference_model
- paddle.static.load_program_state
- paddle.static.set_program_state
由于飞桨框架2.0不再主推静态图模式,故本文不对以上主要用于飞桨框架1.x的相关接口展开介绍,如有需要,可以阅读对应API文档。
1.1.3 高阶API存储载入体系
- paddle.Model.fit (训练接口,同时带有参数存储的功能)
- paddle.Model.save
- paddle.Model.load
飞桨框架2.0高阶API仅有一套Save/Load接口,表意直观,体系清晰,若有需要,建议直接阅读相关API文档,此处不再赘述。
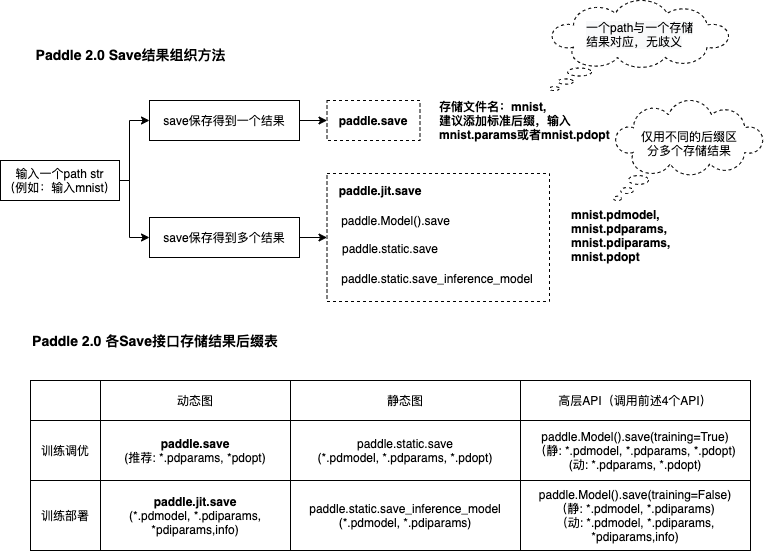
1.2 接口存储结果组织形式
飞桨2.0统一了各存储接口对于同一种存储行为的处理方式,并且统一推荐或自动为存储的文件添加飞桨标准的文件后缀,详见下图:
二、参数存储载入(训练调优)
若仅需要存储/载入模型的参数,可以使用 paddle.save/load 结合Layer和Optimizer的state_dict达成目的,此处state_dict是对象的持久参数的载体,dict的key为参数名,value为参数真实的numpy array值。
结合以下简单示例,介绍参数存储和载入的方法,以下示例完成了一个简单网络的训练过程:
import numpy as np
import paddle
import paddle.nn as nn
import paddle.optimizer as opt
BATCH_SIZE = 16
BATCH_NUM = 4
EPOCH_NUM = 4
IMAGE_SIZE = 784
CLASS_NUM = 10
# define a random dataset
class RandomDataset(paddle.io.Dataset):
def __init__(self, num_samples):
self.num_samples = num_samples
def __getitem__(self, idx):
image = np.random.random([IMAGE_SIZE]).astype('float32')
label = np.random.randint(0, CLASS_NUM - 1, (1, )).astype('int64')
return image, label
def __len__(self):
return self.num_samples
class LinearNet(nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM)
def forward(self, x):
return self._linear(x)
def train(layer, loader, loss_fn, opt):
for epoch_id in range(EPOCH_NUM):
for batch_id, (image, label) in enumerate(loader()):
out = layer(image)
loss = loss_fn(out, label)
loss.backward()
opt.step()
opt.clear_grad()
print("Epoch {} batch {}: loss = {}".format(
epoch_id, batch_id, np.mean(loss.numpy())))
# create network
layer = LinearNet()
loss_fn = nn.CrossEntropyLoss()
adam = opt.Adam(learning_rate=0.001, parameters=layer.parameters())
# create data loader
dataset = RandomDataset(BATCH_NUM * BATCH_SIZE)
loader = paddle.io.DataLoader(dataset,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=True,
num_workers=2)
# train
train(layer, loader, loss_fn, adam)
2.1 参数存储
参数存储时,先获取目标对象(Layer或者Optimzier)的state_dict,然后将state_dict存储至磁盘,示例如下(接前述示例):
# save
paddle.save(layer.state_dict(), "linear_net.pdparams")
paddle.save(adam.state_dict(), "adam.pdopt")
2.2 参数载入
参数载入时,先从磁盘载入保存的state_dict,然后通过set_state_dict方法配置到目标对象中,示例如下(接前述示例):
# load
layer_state_dict = paddle.load("linear_net.pdparams")
opt_state_dict = paddle.load("adam.pdopt")
layer.set_state_dict(layer_state_dict)
adam.set_state_dict(opt_state_dict)
三、模型&参数 存储载入(训练部署)
若要同时存储/载入模型结构和参数,可以使用 paddle.jit.save/load实现。
3.1 模型&参数存储
模型&参数存储根据训练模式不同,有两种使用情况:
-
- 动转静训练 + 模型&参数存储
-
- 动态图训练 + 模型&参数存储
3.1.1 动转静训练 + 模型&参数存储
动转静训练相比直接使用动态图训练具有更好的执行性能,训练完成后,直接将目标Layer传入 paddle.jit.save 存储即可。:
一个简单的网络训练示例如下:
import numpy as np
import paddle
import paddle.nn as nn
import paddle.optimizer as opt
BATCH_SIZE = 16
BATCH_NUM = 4
EPOCH_NUM = 4
IMAGE_SIZE = 784
CLASS_NUM = 10
# define a random dataset
class RandomDataset(paddle.io.Dataset):
def __init__(self, num_samples):
self.num_samples = num_samples
def __getitem__(self, idx):
image = np.random.random([IMAGE_SIZE]).astype('float32')
label = np.random.randint(0, CLASS_NUM - 1, (1, )).astype('int64')
return image, label
def __len__(self):
return self.num_samples
class LinearNet(nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM)
@paddle.jit.to_static
def forward(self, x):
return self._linear(x)
def train(layer, loader, loss_fn, opt):
for epoch_id in range(EPOCH_NUM):
for batch_id, (image, label) in enumerate(loader()):
out = layer(image)
loss = loss_fn(out, label)
loss.backward()
opt.step()
opt.clear_grad()
print("Epoch {} batch {}: loss = {}".format(
epoch_id, batch_id, np.mean(loss.numpy())))
# create network
layer = LinearNet()
loss_fn = nn.CrossEntropyLoss()
adam = opt.Adam(learning_rate=0.001, parameters=layer.parameters())
# create data loader
dataset = RandomDataset(BATCH_NUM * BATCH_SIZE)
loader = paddle.io.DataLoader(dataset,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=True,
num_workers=2)
# train
train(layer, loader, loss_fn, adam)
随后使用 paddle.jit.save 对模型和参数进行存储(接前述示例):
# save
path = "example.model/linear"
paddle.jit.save(layer, path)
- 通过动转静训练后保存模型&参数,有以下三项注意点:
- 1).Layer对象的forward方法需要经由 paddle.jit.to_static 装饰
经过 paddle.jit.to_static 装饰forward方法后,相应Layer在执行时,会先生成描述模型的Program,然后通过执行Program获取计算结果,示例如下:
若最终需要生成的描述模型的Program支持动态输入,可以同时指明模型的 InputSepc ,示例如下:【不懂】import paddle import paddle.nn as nn IMAGE_SIZE = 784 CLASS_NUM = 10 class LinearNet(nn.Layer): def __init__(self): super(LinearNet, self).__init__() self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM) @paddle.jit.to_static def forward(self, x): return self._linear(x)import paddle import paddle.nn as nn from paddle.static import InputSpec IMAGE_SIZE = 784 CLASS_NUM = 10 class LinearNet(nn.Layer): def __init__(self): super(LinearNet, self).__init__() self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM) @paddle.jit.to_static(input_spec=[InputSpec(shape=[None, 784], dtype='float32')]) def forward(self, x): return self._linear(x) -
- 请确保Layer.forward方法中仅实现预测功能,避免将训练所需的loss计算逻辑写入forward方法
-
- 如果你需要存储多个方法,需要用 paddle.jit.to_static 装饰每一个需要被存储的方法。
| 只有在forward之外还需要存储其他方法时才用这个特性,如果仅装饰非forward的方法,而forward没有被装饰,是不符合规范的。此时 paddle.jit.save 的 input_spec 参数必须为None。
示例代码如下:
存储的模型命名规则:forward的模型名字为:模型名+后缀,其他函数的模型名字为:模型名+函数名+后缀。每个函数有各自的pdmodel和pdiparams的文件,所有函数共用pdiparams.info。上述代码将在 example.model 文件夹下产生5个文件: linear.another_forward.pdiparams、 linear.pdiparams、 linear.pdmodel、 linear.another_forward.pdmodel、 linear.pdiparams.infoimport paddle import paddle.nn as nn from paddle.static import InputSpec IMAGE_SIZE = 784 CLASS_NUM = 10 class LinearNet(nn.Layer): def __init__(self): super(LinearNet, self).__init__() self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM) self._linear_2 = nn.Linear(IMAGE_SIZE, CLASS_NUM) @paddle.jit.to_static(input_spec=[InputSpec(shape=[None, IMAGE_SIZE], dtype='float32')]) def forward(self, x): return self._linear(x) @paddle.jit.to_static(input_spec=[InputSpec(shape=[None, IMAGE_SIZE], dtype='float32')]) def another_forward(self, x): return self._linear_2(x) inps = paddle.randn([1, IMAGE_SIZE]) layer = LinearNet() before_0 = layer.another_forward(inps) before_1 = layer(inps) # save and load path = "example.model/linear" paddle.jit.save(layer, path) - 如果你需要存储多个方法,需要用 paddle.jit.to_static 装饰每一个需要被存储的方法。
- 1).Layer对象的forward方法需要经由 paddle.jit.to_static 装饰
3.1.2 动态图训练 + 模型&参数存储
动态图模式相比动转静模式更加便于调试,如果你仍需要使用动态图直接训练,也可以在动态图训练完成后调用 paddle.jit.save 直接存储模型和参数。
同样是一个简单的网络训练示例:
import numpy as np
import paddle
import paddle.nn as nn
import paddle.optimizer as opt
from paddle.static import InputSpec
BATCH_SIZE = 16
BATCH_NUM = 4
EPOCH_NUM = 4
IMAGE_SIZE = 784
CLASS_NUM = 10
# define a random dataset
class RandomDataset(paddle.io.Dataset):
def __init__(self, num_samples):
self.num_samples = num_samples
def __getitem__(self, idx):
image = np.random.random([IMAGE_SIZE]).astype('float32')
label = np.random.randint(0, CLASS_NUM - 1, (1, )).astype('int64')
return image, label
def __len__(self):
return self.num_samples
class LinearNet(nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM)
def forward(self, x):
return self._linear(x)
def train(layer, loader, loss_fn, opt):
for epoch_id in range(EPOCH_NUM):
for batch_id, (image, label) in enumerate(loader()):
out = layer(image)
loss = loss_fn(out, label)
loss.backward()
opt.step()
opt.clear_grad()
print("Epoch {} batch {}: loss = {}".format(
epoch_id, batch_id, np.mean(loss.numpy())))
# create network
layer = LinearNet()
loss_fn = nn.CrossEntropyLoss()
adam = opt.Adam(learning_rate=0.001, parameters=layer.parameters())
# create data loader
dataset = RandomDataset(BATCH_NUM * BATCH_SIZE)
loader = paddle.io.DataLoader(dataset,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=True,
num_workers=2)
# train
train(layer, loader, loss_fn, adam)
训练完成后使用 paddle.jit.save对模型和参数进行存储:
# save
path = "example.dy_model/linear"
paddle.jit.save(
layer=layer,
path=path,
input_spec=[InputSpec(shape=[None, 784], dtype='float32')])
- 动态图训练后使用 paddle.jit.save 存储模型和参数注意点如下:
-
- 相比动转静训练,Layer对象的forward方法不需要额外装饰,保持原实现即可
-
- 与动转静训练相同,请确保Layer.forward方法中仅实现预测功能,避免将训练所需的loss计算逻辑写入forward方法
-
- 在最后使用 paddle.jit.save 时,需要指定Layer的 InputSpec ,Layer对象forward方法的每一个参数均需要对应的 InputSpec 进行描述,不能省略。这里的 input_spec 参数支持两种类型的输入:
- InputSpec 列表
使用InputSpec描述forward输入参数的shape,dtype和name,如前述示例(此处示例中name省略,name省略的情况下会使用forward的对应参数名作为name,所以这里的name为 x ):paddle.jit.save( layer=layer, path=path, input_spec=[InputSpec(shape=[None, 784], dtype='float32')]) - Example Tensor 列表
除使用InputSpec之外,也可以直接使用forward训练时的示例输入,此处可以使用前述示例中迭代DataLoader得到的 image ,示例如下:paddle.jit.save( layer=layer, path=path, input_spec=[image])
-
3.2 模型&参数载入
载入模型参数,使用 paddle.jit.load 载入即可,载入后得到的是一个Layer的派生类对象 TranslatedLayer , TranslatedLayer 具有Layer具有的通用特征,支持切换 train 或者 eval 模式,可以进行模型调优或者预测。
| 注解: 为了规避变量名字冲突,载入之后会重命名变量。
载入模型及参数,示例如下:
import numpy as np
import paddle
import paddle.nn as nn
import paddle.optimizer as opt
BATCH_SIZE = 16
BATCH_NUM = 4
EPOCH_NUM = 4
IMAGE_SIZE = 784
CLASS_NUM = 10
# load
path = "example.model/linear"
loaded_layer = paddle.jit.load(path)
载入模型及参数后进行预测,示例如下(接前述示例):
# inference
loaded_layer.eval()
x = paddle.randn([1, IMAGE_SIZE], 'float32')
pred = loaded_layer(x)
载入模型及参数后进行调优,示例如下(接前述示例):
# define a random dataset
class RandomDataset(paddle.io.Dataset):
def __init__(self, num_samples):
self.num_samples = num_samples
def __getitem__(self, idx):
image = np.random.random([IMAGE_SIZE]).astype('float32')
label = np.random.randint(0, CLASS_NUM - 1, (1, )).astype('int64')
return image, label
def __len__(self):
return self.num_samples
def train(layer, loader, loss_fn, opt):
for epoch_id in range(EPOCH_NUM):
for batch_id, (image, label) in enumerate(loader()):
out = layer(image)
loss = loss_fn(out, label)
loss.backward()
opt.step()
opt.clear_grad()
print("Epoch {} batch {}: loss = {}".format(
epoch_id, batch_id, np.mean(loss.numpy())))
# fine-tune
loaded_layer.train()
dataset = RandomDataset(BATCH_NUM * BATCH_SIZE)
loader = paddle.io.DataLoader(dataset,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=True,
num_workers=2)
loss_fn = nn.CrossEntropyLoss()
adam = opt.Adam(learning_rate=0.001, parameters=loaded_layer.parameters())
train(loaded_layer, loader, loss_fn, adam)
# save after fine-tuning
paddle.jit.save(loaded_layer, "fine-tune.model/linear", input_spec=[x])
此外, paddle.jit.save 同时保存了模型和参数,如果你只需要从存储结果中载入模型的参数,可以使用 paddle.load 接口载入,返回所存储模型的state_dict,示例如下:
import paddle
import paddle.nn as nn
IMAGE_SIZE = 784
CLASS_NUM = 10
class LinearNet(nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM)
@paddle.jit.to_static
def forward(self, x):
return self._linear(x)
# create network
layer = LinearNet()
# load
path = "example.model/linear"
state_dict = paddle.load(path)
# inference
layer.set_state_dict(state_dict, use_structured_name=False)
layer.eval()
x = paddle.randn([1, IMAGE_SIZE], 'float32')
pred = layer(x)
四、旧存储格式兼容载入
模型存储载入相关API详解
-
10.paddle.save(obj, path, pickle_protocol=2) 将对象实例obj保存到指定路径中。
* 目前仅支持存储 Layer 或者 Optimizer 的 state_dict * 不同于 paddle.jit.save ,由于 paddle.save 的存储结果是单个文件,所以不需要通过添加后缀的方式区分多个存储文件,paddle.save 的输入参数 path 将直接作为存储结果的文件名而非前缀。为了统一存储文件名的格式,我们推荐使用paddle标椎文件后缀: 1. 对于 Layer.state_dict ,推荐使用后缀 .pdparams ; 2. 对于 Optimizer.state_dict ,推荐使用后缀 .pdopt * obj (Object) – 要保存的对象实例 * path (str) – 保存对象实例的路径。如果存储到当前路径,输入的path字符串将会作为保存的文件名 * pickle_protocol (int, 可选) – pickle模块的协议版本,默认值为2,取值范围是[2,4] emb = paddle.nn.Embedding(10, 10) layer_state_dict = emb.state_dict() paddle.save(layer_state_dict, "emb.pdparams") scheduler = paddle.optimizer.lr.NoamDecay( d_model=0.01, warmup_steps=100, verbose=True) adam = paddle.optimizer.Adam( learning_rate=scheduler, parameters=emb.parameters()) opt_state_dict = adam.state_dict() paddle.save(opt_state_dict, "adam.pdopt") -
11.paddle.load(path, **configs) 从指定路径载入可以在 paddle中使用的 对象实例。
返回: Object,一个可以在paddle中使用的对象实例 * 目前仅仅支持载入 Layer 或 Optimizer 的static_dict * 注释: 为了高效的使用paddle存储的模型参数, paddle.load 支持从除 paddle.save 之外的其他 save 相关API的存储结果中载入 state_dict, 但是在不同场景中, 参数 path 的形式有所不同: * 1.从 paddle.static.svae() 或者 paddle.Model().save(training=True)的保存结果载入: path 需要是完整的 文件名,例如: model.pdparams 或 model.opt; * 2.从paddle.jit.save() 或者 paddle.static.save_inference_model() 或 paddle.Model().save(training= False) 的保存结果结果载入: path 需要是路径前缀,例如: model/mnist, paddle.load 会从 mnist.pdmodel 和 mnist.pdiparams 中解析 static_dict 的信息并返回。 * 3. 从paddle 1.x API paddle.fluid.io.save_inference_model 或者 paddle.fluid.io.save_params/save_persistables 的保存结果载入: path 需要是目录,例如 model ,此处model是一个文件夹路径。 * 注释: 如果从 paddle.static.save 或者 paddle.static.save_inference_model 等静态图API的存储结果中载入 state_dict ,动态图模式下参数的结构性变量名将无法被恢复。在将载入的 state_dict 配置到当前Layer中时,需要配置 Layer.set_state_dict 的参数 use_structured_name=False. 啥是 结构性变量名? * path (str) – 载入目标对象实例的路径。通常该路径是目标文件的路径,当从用于存存储预测模型API的存储结果中载入state_dict时,该路径可能是一个文件前缀或者目录 emb = paddle.nn.Embedding(10, 10) layer_state_dict = emb.state_dict() paddle.save(layer_state_dict, "emb.pdparams") scheduler = paddle.optimizer.lr.NoamDecay( d_model=0.01, warmup_steps=100, verbose=True) adam = paddle.optimizer.Adam( learning_rate=scheduler, parameters=emb.parameters()) opt_state_dict = adam.state_dict() paddle.save(opt_state_dict, "adam.pdopt") load_layer_state_dict = paddle.load("emb.pdparams") load_opt_state_dict = paddle.load("adam.pdopt") -
paddle.jit.save()
-
paddle.jit.load()
-
layer.set_state_dict(layer_state_dict)
-
adam.set_state_dict(opt_state_dict)
Paddle保存的模型有两种格式,一种是训练格式,保存模型参数和优化器相关的状态,可用于恢复训练;一种是预测格式,保存预测的静态图网络结构以及参数,用于预测部署。
* 高层API场景:高层API下用于预测部署的模型保存方法为:
model = paddle.Model(Mnist())
# 预测格式,保存的模型可用于预测部署
model.save('mnist', training=False)
# 保存后可以得到预测部署所需要的模型
* 基础API场景:动态图训练的模型,可以通过动静转换功能,转换为可部署的静态图模型,具体做法如下:
import paddle
from paddle.jit import to_static
from paddle.static import InputSpec
class SimpleNet(paddle.nn.Layer):
def __init__(self):
super(SimpleNet, self).__init__()
self.linear = paddle.nn.Linear(10, 3)
# 第1处改动
# 通过InputSpec指定输入数据的形状,None表示可变长
# 通过to_static装饰器将动态图转换为静态图Program
@to_static(input_spec=[InputSpec(shape=[None, 10], name='x'), InputSpec(shape=[3], name='y')])
def forward(self, x, y):
out = self.linear(x)
out = out + y
return out
net = SimpleNet()
# 第2处改动
# 保存静态图模型,可用于预测部署
paddle.jit.save(net, './simple_net')