1.Oozie是任务调度管理系统: 当然简单的可以用crontab表达式结合shell脚本作为任务调度管理系统
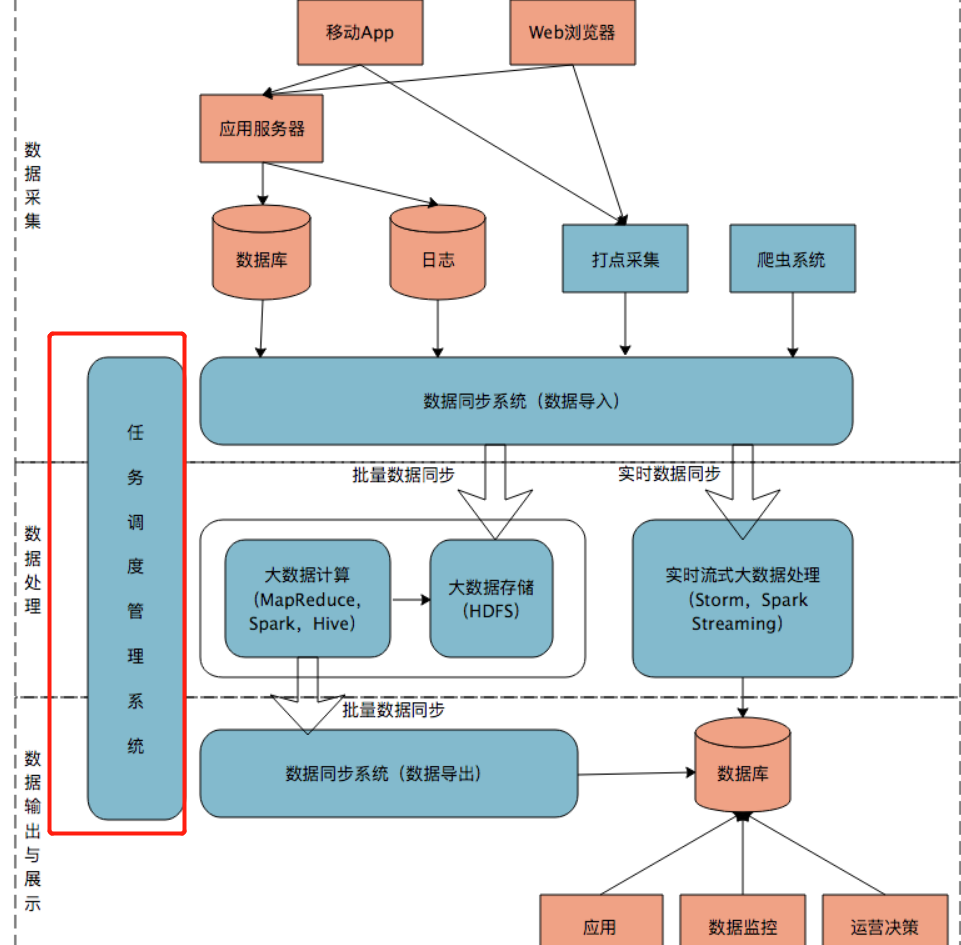
2.关系型数据库导入数据到大数据平台用sqoop和Canal , Sqoop适合关系数据库数据的批量导入,如果想实时导入关系数据库的数据,可以选择Canal。
Canal是阿里巴巴开源的一个MySQL binlog获取工具,binlog是MySQL的事务日志,可用于MySQL数据库主从复制,Canal将自己伪装成MySQL从库,从MySQL获取binlog。
而我们只要开发一个Canal客户端程序就可以解析出来MySQL的写操作数据,将这些数据交给大数据流计算处理引擎,就可以实现对MySQL数据的实时处理了。
3.前端埋点数据采集也是互联网应用大数据的重要来源之一,用户的某些前端行为并不会产生后端请求,比如用户在一个页面的停留时间、用户拖动页面的速度、用户选中一个复选框然后又取消了。这些信息对于大数据处理,对于分析用户行为,进行智能推荐都很有价值。但是这些数据必须通过前端埋点获得,所谓前端埋点,就是应用前端为了进行数据统计和分析而采集数据。
4.
5.我们学大数据,手里用的是技术,眼里要看到数据,要让数据为你所用。数据才是核心才是不可代替的,技术并不是
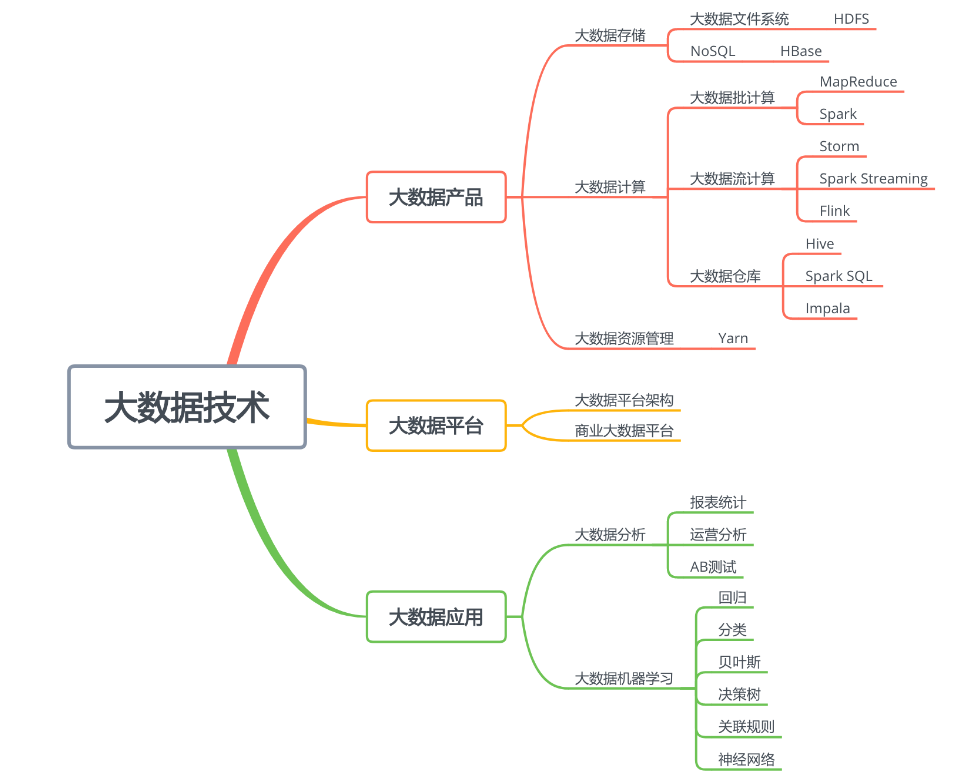
6.大数据越来越多的和人工智能关联起来了,所谓的人工智能就是利用数学统计方法,统计数据中的规律,然后利用这些统计规律进行自动化数据处理,使计算机表现出某种智能的特性,而各种数学统计方法,就是大数据算法
7.数据挖掘的典型应用场景有搜索排序、关联分析、聚类
8.所谓的人工智能,在技术层面很多时候就是指机器学习,通过选择特定的算法对样本数据进行计算,获得一个计算模型,并利用这个模型,对以前未曾见过的数据进行预测。如果这个预测在一定程度上和事实相符,我们就认为机器像人一样具有某种智能,即人工智能。
9.样本就是通常我们常说的“训练数据”,包括输入和结果两部分。比如我们要做一个自动化新闻分类的机器学习系统,对于采集的每一篇新闻,能够自动发送到对应新闻分类频道里面,比如体育、军事、财经等。这时候我们就需要批量的新闻和其对应的分类类别作为训练数据。通常随机选取一批现成的新闻素材就可以,但是分类需要人手工进行标注,也就是需要有人阅读每篇新闻,根据其内容打上对应的分类标签。
10.模型就是映射样本输入与样本结果的函数,可能是一个条件概率分布,也可能是一个决策函数。一个具体的机器学习系统所有可能的函数构成了模型的假设空间
算法就是要从模型的假设空间中寻找一个最优的函数,使得样本空间的输入$X$经过该函数的映射得到的$f(X)$,和真实的$Y$值之间的距离最小。这个最优的函数通常没办法直接计算得到,即没有解析解,需要用数值计算的方法不断迭代求解。因此如何寻找到$f$函数的全局最优解,以及使寻找过程尽量高效,就构成了机器学习的算法。
11.如何保证$f$函数或者$f$函数的参数空间最接近最优解,就是算法的策略。机器学习中用损失函数来评估模型是否最接近最优解。损失函数用来计算模型预测值与真实值的差距,常用的有0-1损失函数、平方损失函数、绝对损失函数、对数损失函数等。。一个机器学习模型的参数可能有数百万,训练的样本数据则会更多,因此机器学习通常依赖大数据技术进行模型训练,而机器学习及其高阶形态的神经网络、深度学习则是实现人工智能的主要手段。