1.非数值数据的类型
(1)逻 辑 值:逻辑数据和数值数据都是一串0/1序列,在形式上无任何差异,需要通过指令的操作码类型来识别它们。
(2)西文字符:1)西文由拉丁字母、数字、标点字符及一些特殊字符所组成,它们统称为字符。
2)所有字符的集合叫做字符集。
3)字符主要用于外部设备和计算机之间交换信息。
(3)汉字字符: 汉字被输入到计算机内部后,就按照一种称为内码的编码形式在系统中进行储存,查找,传输等处理.
考虑因素:
1)不能有二义性,即不能和ASCII码有相同的编码.
2)要与汉字在字库中的位置有关系,以便于汉字的处理,查找.
3)编码应尽量短.
汉字字形有两种描述方法:字模点阵描述和轮廓描述.
2.编码的区别
(1)ASCII码:是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
(2)GBK编码:由于ASCII编码不支持中文,因此,当中国人用到计算机时,就需要寻求一种编码方式来支持中文。
(3)Unicode编码:因为世界国家很多,每个国家都定义一套自己的编码标准,结果相互之间谁也不懂谁的编码,就无法进行很好的沟通交流,所以及时的出现了一个组织ISO决定制定一套编码方案来解决所有国家的编码问题。
(4)UTF-8编码:由于Unicode比较浪费网络带宽和硬盘,因此为了解决这个问题,就在Unicode的基础上,定义了一套编码规则(将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)),这个新的编码规则就是UTF-8,采用1-4个字符进行传输和存储数据。
3.效验码的方式
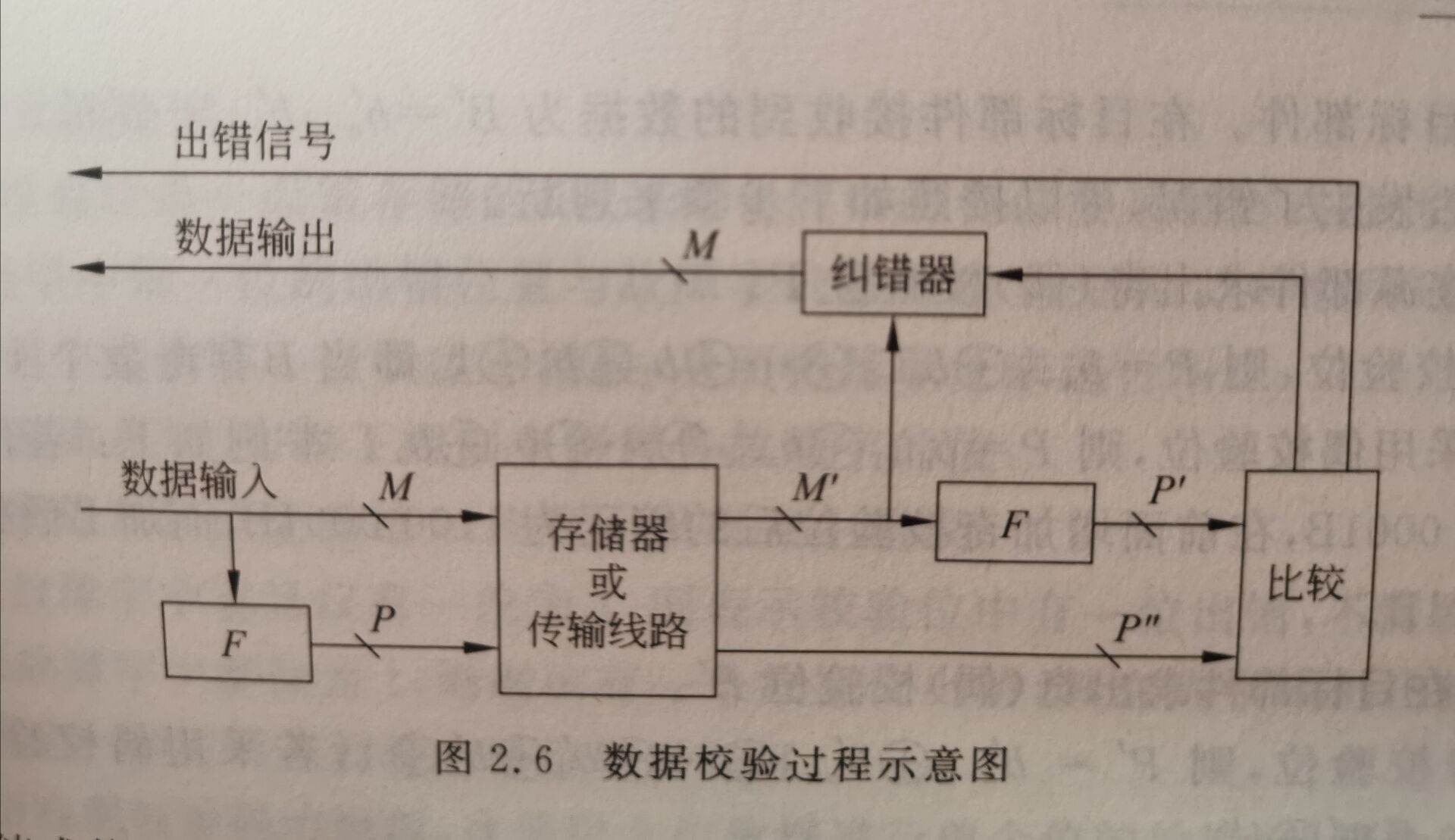
(1)没有检测到错误,得到的数据位直接传送出去。
(2)检测到差错,并可以纠错。数据位和比较结果在目标部件出奇(偶)效验位P'。
(3)计算最终的效验位P*,并根据其值判断有无奇偶错。
B.海明效验码
(1)如果故障字各位全部是0,则表示没有发生错误。
(2)如果故障字中有且仅有一位为1,则表示校验位中有一位出错,不需要纠正
(3)如果故障字中多位为1,则表示有一个数据位出错,其在码字中的出错位置由故障字的数值来确定,纠正时只要将其错位取反即可。
C.循环冗余效验码
1)编码原理:
现假设有:有效信息:M;
除数G(生成多项式)有:M/G=Q+R/G;
此时,可选择R作为校验位,则MR即为校验码。
2)校验原理:(M-R)/G=Q+0/G
说明:以接收到的校验码除以约定的除数,若余数为0,则可认为接收到的数据是正确的。
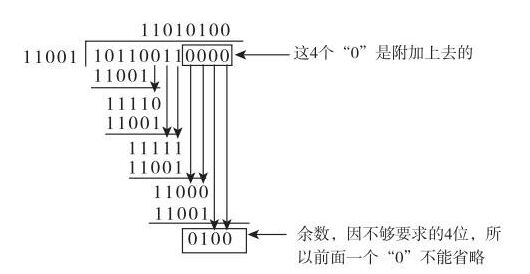
例:有效信息1101,生成多项式样1011
3)循环校验码解:
有效信息1101(k=4),即M(x)=x3+x2+x0,生成多项式1011(r+1=4,即r=3);
即G(x)=x3+x1+x0,M(x)·x3=x6+x5+x3,即1101000(对1101左移三位);
M(x)·x3/G(x)=1101000/1011=1111+001/1011 即1010的CRC是:1101001 。
计算图文如下 :