DBSCAN有一些缺点,如:参数的设定,比如说阈值和半径 这些参数对结果很敏感,还有就是该算法是全局密度的,假若数据集的密度变化很大时,可能识别不出某些簇。如下图:
核心距离:假定P是核心对象,人为给定一个阈值A,然后计算关于P点满足阈值A的最小的半径R,即在R内,P最少有给定A个点数。
可达距离:对象q到对象p的可达距离是指p的核心距离和p与q之间欧几里得距离之间的较大值。如果p不是核心对象,p和q之间的可达距离没有意义。
核心距离:假若半径ξ=8 阈值MinPts=5
则有图而知:P是核心对象(在半径8内,P的近邻对象个数>5),并且P的核心距离为4 因为在半径4内,有四个近邻点,满足阈值5
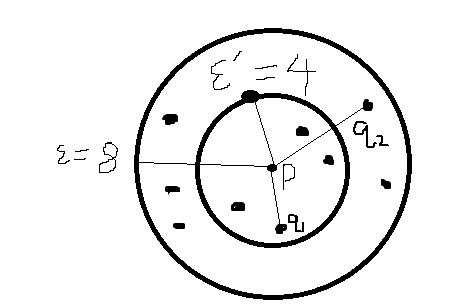
最小的阈值确定和核心距离
算法
注意:一个点有多个可达距离,选取最小的距离,因为最小的距离就是给点距离最近的一个簇的距离。
OPTICS算法的难点在于维护核心点的直接可达点的有序列表。算法的计算过程如下:
输入:数据样本D,初始化所有点的可达距离和核心距离为MAX,半径ε,和最少点数MinPts。
1、建立两个队列,有序队列(核心点及该核心点的直接密度可达点),结果队列(存储样本输出及处理次序)
2、如果D中数据全部处理完,则算法结束,否则从D中选择一个未处理且未核心对象的点,将该核心点放入结果队列,该核心点的直接密度可达点放入有序队列,直接密度可达点并按可达距离升序排列;
3、如果有序序列为空,则回到步骤2,否则从有序队列中取出第一个点;
3.1 判断该点是否为核心点,不是则回到步骤3,是的话则将该点存入结果队列,如果该点不在结果队列;
3.2 该点是核心点的话,找到其所有直接密度可达点,并将这些点放入有序队列,且将有序队列中的点按照可达距离重新排序,如果该点已经在有序队列中且新的可达距离较小,则更新该点的可达距离。
3.3 重复步骤3,直至有序队列为空。
4、算法结束。
预先筛选出数据集中的核心对象,然后计算每个核心对象的核心距离。进而执行算法。
输出结果
给定半径ε,和最少点数MinPts,就可以输出所有的聚类。
计算过程为:
给定结果队列
1、从结果队列中按顺序取出点,如果该点的可达距离不大于给定半径ε,则该点属于当前类别,否则至步骤2;
2、如果该点的核心距离大于给定半径ε,则该点为噪声,可以忽略,否则该点属于新的聚类,跳至步骤1;
3、结果队列遍历结束,则算法结束。
基于matlab的代码:
% Function: % [RD,CD,order]=optics(x,k) % ------------------------------------------------------------------------- % Aim: % Ordering objects of a data set to obtain the clustering structure % ------------------------------------------------------------------------- % Input: % x - data set (m,n); m-objects, n-variables % k - number of objects in a neighborhood of the selected object % (minimal number of objects considered as a cluster) % ------------------------------------------------------------------------- % Output: % RD - vector with reachability distances (m,1) % CD - vector with core distances (m,1) % order - vector specifying the order of objects (1,m) % ------------------------------------------------------------------------- % Example of use: % x=[randn(30,2)*.4;randn(40,2)*.5+ones(40,1)*[4 4]]; % [RD,CD,order]=optics(x,4) % ------------------------------------------------------------------------- % References: % [1] M. Ankrest, M. Breunig, H. Kriegel, J. Sander, % OPTICS: Ordering Points To Identify the Clustering Structure, % available from www.dbs.informatik.uni-muenchen.de/cgi-bin/papers?query=--CO % [2] M. Daszykowski, B. Walczak, D.L. Massart, Looking for natural % patterns in analytical data. Part 2. Tracing local density % with OPTICS, J. Chem. Inf. Comput. Sci. 42 (2002) 500-507 % ------------------------------------------------------------------------- % Written by Michal Daszykowski % Department of Chemometrics, Institute of Chemistry, % The University of Silesia % December 2004 % http://www.chemometria.us.edu.pl function [RD,CD,order,D]=optics(x,k) [m,n]=size(x); % m=70,n=2 CD=zeros(1,m); RD=ones(1,m)*10^10; % Calculate Core Distances for i=1:m D=sort(dist(x(i,:),x)); CD(i)=D(k+1); % 第k+1个距离是密度的界限阈值 end order=[]; seeds=[1:m]; ind=1; while ~isempty(seeds) ob=seeds(ind); %disp(sprintf('aaaa%i',ind)) seeds(ind)=[]; order=[order ob]; % 更新order var1 = ones(1,length(seeds))*CD(ob); var2 = dist(x(ob,:),x(seeds,:)); mm=max([var1;var2]); % 比较两个距离矩阵,选择较大的距离矩阵 ii=(RD(seeds))>mm; RD(seeds(ii))=mm(ii); [i1 ind]=min(RD(seeds)); %disp(sprintf('bbbb%i',ind)) end RD(1)=max(RD(2:m))+.1*max(RD(2:m)); function [D]=dist(i,x) % function: [D]=dist(i,x) % % Aim: % Calculates the Euclidean distances between the i-th object and all objects in x % Input: % i - an object (1,n) % x - data matrix (m,n); m-objects, n-variables % % Output: % D - Euclidean distance (m,1) [m,n]=size(x); D=(sum((((ones(m,1)*i)-x).^2)')); % 距离和 if n==1 D=abs((ones(m,1)*i-x))'; end
这个是根据个人理解的主要思路
