作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
Hadoop综合大作业 要求:
1.将爬虫大作业产生的csv文件上传到HDFS
把数据保存在dataset目录下
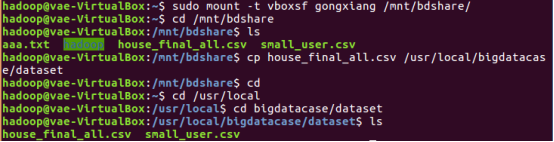
在本地查看数据集
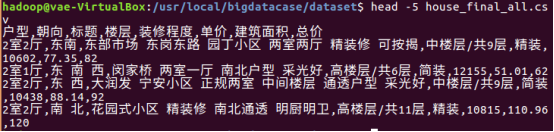
2.对CSV文件进行预处理生成无标题文本文件
删除文件第一行数据
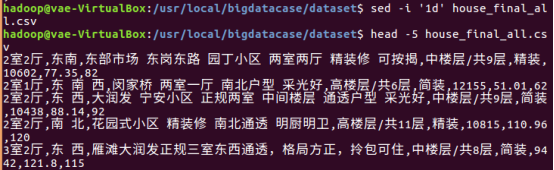
3.把hdfs中的文本文件最终导入到数据仓库Hive中
在HDFS上创建文件夹
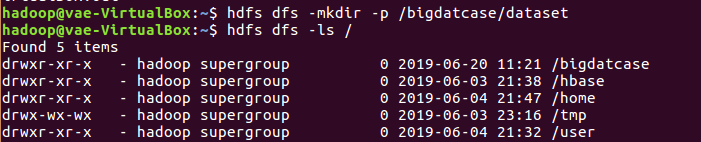
把数据文件上传到HDFS中
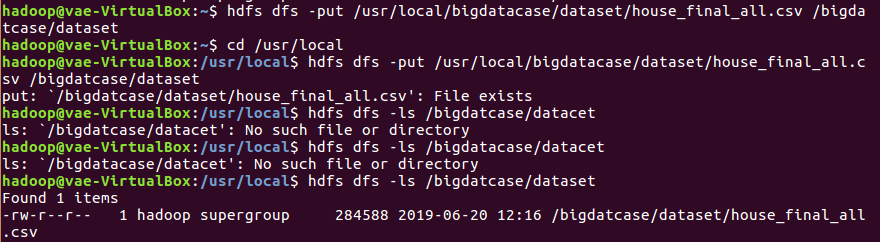
查看前10条数据
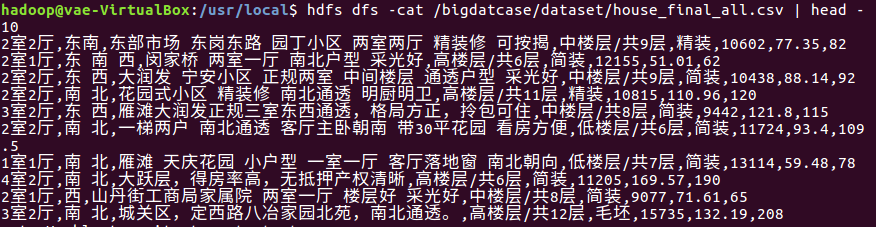
4.在Hive中查看并分析数据
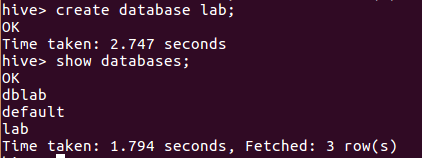
创建数据库
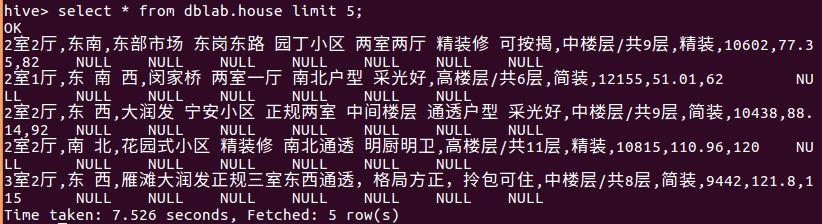
查看数据
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
(1)查找数据量
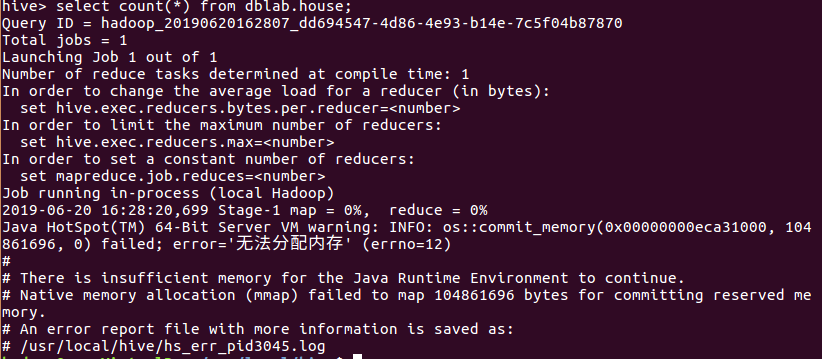
###########################################################################################################
分布式文件系统HDFS 练习
作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3310
作业要求:
利用Shell命令与HDFS进行交互
以”./bin/dfs dfs”开头的Shell命令方式
1.目录操作
在HDFS中为hadoop用户创建一个用户目录(hadoop用户)

在用户目录下创建一个input目录

在HDFS的根目录下创建一个名称为input的目录

删除HDFS根目录中的“input”目录

2.文件操作
使用vim编辑器,在本地Linux文件系统的“/home/hadoop/”目录下创建一个文件:姓名.txt
在该文件里面可以随意输入一些单词,如学号

把本地文件系统的“/home/hadoop/姓名.txt”上传到HDFS中的当前用户目录的input目录下
查看一下文件是否成功上传到HDFS中
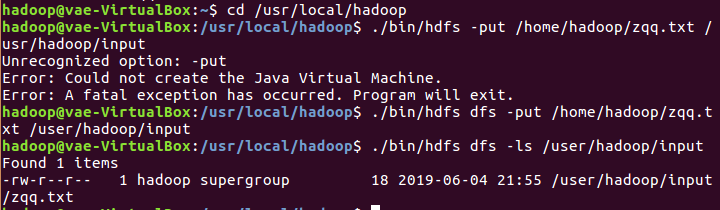
查看HDFS中的姓名.txt这个文件的内容

把文件从HDFS中当前用户目录的input目录拷贝到HDFS根目录

从HDFS根目录删除这个文件
