HTTP请求与响应的过程
首先在浏览器输入www.163.com(url 统一资源定位符) 通过DNS解析获得IP地址,然后封装一个http请求
Http请求的构建
| 请求行 | 方法 | URL | 版本 | |
|---|---|---|---|---|
| 首部 | key | value | key | value |
| 实体 |
http请求包含三部分:请求行、首部、实体
请求行:
- 版本为http版本,如1.0, 1.1, 2.0
- URL:即www.163.com
- 方法:如get post put delete
首部:保存重要的字段
例如:
- accept-charset 客户端可以接受的字符集
- content-type 正文的格式
- cache-control 控制缓存
HTTP请求的发送
HTTP是基于TCP,所以使用面向连接的方式发送请求,通过stream二进制的方式传给对方,到了TCP层,二进制流转成报文段发送给服务器。
HTTP返回的构建
| 状态行 | 版本 | 状态码 | 短语 | |
|---|---|---|---|---|
| 首部 | key | value | key | value |
| 实体 |
状态行
- 状态码:如200 404
- 短语:大概的原因
首部:功能同上
- retry-after 稍后尝试
- content-type 返回类型:HTML,JSON
HTTP进化历程
| HTTP1.0 | HTTP1.1 | HTTP2.0 | |
|---|---|---|---|
| 问题 | 客户端队首阻塞 | 服务端队首阻塞 | |
| 对于同一个TCP连接,所有请求放到一个队列中,只有前一个请求的响应到了才能发送第二个请求 | 对于同一个TCP连接可以一次发送多个请求,解决了HTTP1.0的阻塞问题。但是规定服务器要按照接受顺序发送响应,先接受的请求的响应要先发送,那么此时就会出现一个问题,如果前一个响应的处理时间过长生成响应过慢,那么便会阻塞已生成响应的发送 | 无论是客户端还是服务端都不需要排队,同一个TCP有多个stream有各个stream发送和接收HTTP请求,相互独立,互不阻塞 |
HTTP2.0的提升性能的优化思路
- 头压缩:使用索引表的方式,将每次搜药携带的大量key-value在两端建立索引表,对相同的头只发送索引表中的索引
- 分帧
- 二进制编码
- 多路复用技术
基于UDP的QUIC协议
(我猜quic是quick快速的缩写)
Google的QUIC协议
- 自定义连接机制:源IP,源端口,目的IP,目的端口一个元素发生改变时TCP便会断开连接,重新连接。WiFi或移动网络切换时会导致重连,导致时延。基于UDP的连接不以四元组标识,而是以一个64位的随机数作为ID。
- 自定义重传机制:修复TCP中的采样往返时间RTT不准确的问题
- 无阻塞的多路复用:同HTTP2.0一样,同一条连接可以建立多个stream来发送HTTP请求。由于QUIC是基于UDP的,一个连接上的stream没有依赖,这样假如stream2丢包,需要重传,后面的stream3无需等待就可以发送诶用户。
- 自定义流量控制:TCP流量控制是基于滑动窗口协议,起点是下一个要接受并且ACK的包,及时后面的包到了放在缓存里窗口也不能右移。
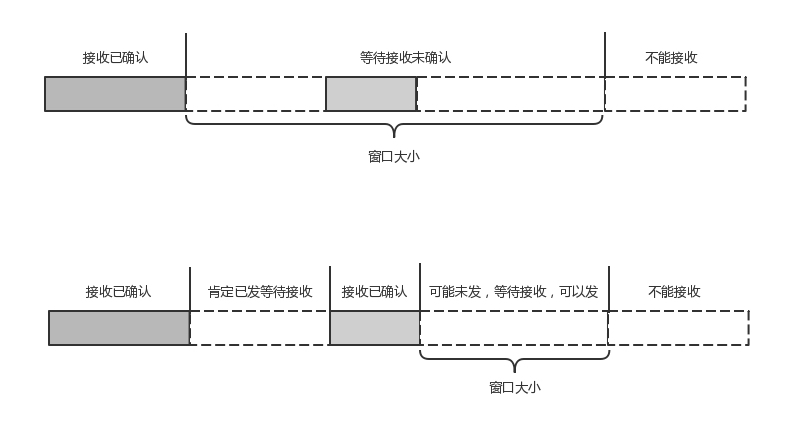
而QUIC是基于offset,包来之后进入缓存便可应答,且不但在一个连接上控制窗口,还在一个连接的每一个stream控制窗口