自然语言处理技术概述
自然语言处理(NLP)是语言学和人工智能的交叉科学,旨在让计算机能够“读懂”人类的语言,是指机器理解并解释人类paralyzes写作、说话方式的能力。其包括的主要范畴有:分词、词性标注、命名实体识别、句法分析、关键词抽取、文本分类、自动摘要以及信息检索等等。传统的自然语言处理主要是利用语言学领域本身的知识结合一些统计学的方法来获取语言知识。后来伴随着机器学习浅层模型的发展(如:SVM、逻辑回归等等),自然语言处理领域的研究取得了一定的突破,但在语义消歧、语言的理解等方面还是显得力不存心。近年来,随着深度学习相关技术(DNN、CNN、RNN等)取得了显著的进展,其在自然语言处理方面的应用也展现出了明显的优势。
自然语言处理技术的流程
1、自然语言理解(NLU)
2、自然语言生成(NLG)
自然语言理解
NLU 是要理解给定文本的含义。本内每个单词的特性与结构需要被理解。在理解结构上,NLU 要理解自然语言中的以下几个歧义性:
词法歧义性:
词法歧义性是指一个单词有多重含义。如train这个单词,作为动词使用时,它是训练的意思,当作为名词使用时,它是火车的意思。又如coach这个单词可以表示为长途汽车,也可以作为教练的意思存在。又如一句谚语:Never trouble troubles until troubles trouble you。这里的trouble就有三个意思。
歧义消除方法
一、有监督消歧
- 贝叶斯分类
s = arg max p(Sk|c), Sk 是W可能包含的语义,C是歧义词的上下文,而s是 使该概率最大的语义,即消歧后确定的语义。 - 基于信息论的方法。以W包含2个语义为例,基本思想是最大化 互信息 I(P,Q),P是W的语义集,Q是W的指示器取值集(指示器 即能区分W不同语义的关键邻近词)。
例:法语“ prendre”的含义是take或make,其指示器可以是 decision,note,example,measure。P划分为 p1 = {take,}和p2={make,},
Q分为Q1 = {note,example,measure,}和Q2 = {decision}, 如果W的指示器为note,出现在Q1中,那么W对应的语义应该对应地出现在P1中,即take。在这里,P和Q的集合划分的原则是最大化 I(P,Q)。该方法感觉和贝叶斯分类本质上类似,还是基于邻近词,根据概率判决,只是具体的公式不一样。
二、 基于词典的消歧(本质上也是无监督消歧的一种)
1.基于语义定义的消歧。如果词典中对W的 第i种定义 包含 词汇Ei,那么如果在一个包含W的句子中,同时也出现了Ei,那么就认为 在该句子中 W的语义应该取词典中的第i 种定义。
2.基于类义辞典的消歧。 词的每个语义 都定义其对应的主题或范畴(如“网球”对应的主题是“运动”),多个语义即对应了多个主题。如果W的上下文C中的词汇包含多个主题,则取其频率最高的主题,作为W的主题,确定了W的主题后,也就能确定其对应的语义。
3.基于双语对比的消歧。这种方法比较有创意,即把一种语言作为另一种语言的定义。例如,为了确定“interest”在英文句子A中的含义,可以利用句子A的中文表达,因为 interest的不同语义在中文的表达是不同的。如果句子A对应中文包含“存款利率”,那么“interest”在句子A的语义就是“利率”。如果句子A的对应中文是“我对英语没有兴趣”,那么其语义就是“兴趣”。
三、无监督消歧
主要是使用EM算法 对W的上下文C进行无监督地聚类,也就是对 W的语义进行了分类。(当然,该分类的结果不见得就是和词典中对该词的定义分类是匹配的)。
语义角色标注概述
语义角色标注是一种浅层语义分析技术,它以句子为单位,不对句子所包含的予以信息进行深入分析,而只是分析句子的谓词-论元结构。具体一点讲,语义角色标注的任务就是以句子的谓词为中心,研究句子中各成分与谓词之间的关系,并且用语义角色来描述它们之间的关系。
句法歧义性
句法歧义性是指语句有多重解析树。在英文中,也可以看到不少的例子,如:
They kidnapped the old coin collector.
这个句子所以引起歧义,是因为其中的形容词辖域(focus scope)不确定。例句中的形容词old既可以修饰名词coin,又可以修饰coin和collector两个名词组成的组合体,从而使句子产生两种句义。
又如red red wine 的结构可为 修饰词 修饰词 事物 又可为 修饰词 属性词 事物。基于前者的翻译为红红的酒,基于后者的翻译为红葡萄酒。
使用上下文无关文法时会出现一些问题。
当给定一个句子时,我们便可以按照从左到右的顺序来解析语法。
例如,句子the man sleeps就可以表示为(S (NP (DT the) (NN man)) (VP sleeps))。

这种上下文无关的语法可以很容易的推导出一个句子的语法结构,但是缺点是推导出的结构可能存在二义性。如下
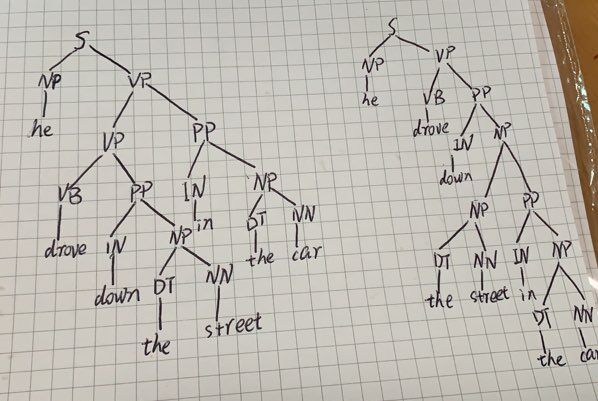
句法歧义消除方法
使用概率分布的上下文无关语法(Probabilistic Context-Free Grammar)
由于语法的解析存在二义性,我们就需要找到一种方法从多种可能的语法树种找出最可能的一棵树。一种常见的方法既是PCFG (Probabilistic Context-Free Grammar)。如下图所示,除了常规的语法规则以外,我们还对每一条规则赋予了一个概率。对于每一棵生成的语法树,我们将其中所以规则的概率的乘积作为语法树的出现概率。
 当我们或得多颗语法树时,我们可以分别计算每颗语法树的概率p(t),出现概率最大的那颗语法树就是我们希望得到的结果,即arg max p(t)。
当我们或得多颗语法树时,我们可以分别计算每颗语法树的概率p(t),出现概率最大的那颗语法树就是我们希望得到的结果,即arg max p(t)。
但是该模型存在一些假设条件:

语义歧义性
语义歧义性是指一个句子有多重含义。
如在英文谚语中,Cats hind their paws 这句话在百度翻译中,这句话的意思是毛隐藏起它们的爪子。但是在实际意义中,这句话是大智若愚的意思。
又如:Diamond cuts diamond在百度翻译中是指 钻石 切割 钻石 但是在实际中又引申为强中自有强中手。语义歧义性的消除主要还是消除词义歧义。
回指歧义性(Anaphoric Ambiguity)
回指歧义性是指之前提到的短语或单词在后面句子中有不同的含义。比如说在英剧中有很多像讽刺,黑色幽默的例子,这里不做详述。
自然语言生成
自然语言生成是研究使计算机具有人一样的表达和写作的功能。即能够根据一些关键信息及其在机器内部的表达形式,经过一个规划过程,来自动生成一段高质量的自然语言文本。
自然语言生成可被分为三个阶段:
1、文本规划
2、语句规划
3、实现
其中,文本规划决定文本要说什么(what);句法实现决定怎么说(how);句子规划则负责让句子更加连贯。
自然语言生成方法
虽然NLG已应用于许多实践当中,但目前对NLG的研究进展远不如NLU。所以,在NLG技术发展的历史过程中,主要包括基于模板的NLG和基于深度学习的NLG方法。
1、基于模板的NLG
NLG模板由句子模板和词汇模板组成。句子模板包括若干个含有变量的句子,词汇模板则是句子模板中变量对应的所有可能的值。为方便理解,下面引用文献中的一个例子:
topic->weather
act->query
Content: weather_state
->3 对不起,请[<tell>]您需要[<refer>]{<where>}的[<what>]。
->2 请[<tell>]您需要[<refer>]的[<what>|具体内容]。
->1 抱歉,请[<tell>]您需要{<refer>}{(day)|今天|[when]}{(location)||<where>}的[<what>]。
符号说明:
|:或者
[]:内部元素出现次数>=1
{}:内部元素出现次数<=1
():对话管理模块中的变量
<>:自定义语料中的变量
句子前的数字:该句子的权重,权重越大句子出现的可能性越大。
询问天气场景中的句子模板
<tell> -> [告诉我|补充|说明|输入]
<refer> -> [查询|知道|获取|收到|了解|咨询]
<where> -> [哪里|何处|什么位置|什么地方|什么城市|哪个位置|哪个区域]
<what> -> [天气|哪方面信息|什么信息|哪方面情况|哪方面内容|何种内容]
<when> -> [哪天|什么时间|哪个时辰|什么时候]
实际工作中,基于模板的NLG技术在项目初期使用较多,由于其可控性,对于语言较为严谨的很多领域中使用极为普遍。
2、基于深度学习的NLG
伴随深度学习的热潮,以及机器翻译相关研究的快速发展,基于深度学习的NLG技术也有了较为突出的进展。尤其是encoder-decoder框架的流行,使得该框架下的seq2seq技术也得到了快速发展.
自然语言生成的任务
了解了上一部分的NLG体系结构,下面对NLG相关任务进行探讨。通常,通过将输入数据分解成若干个子问题来解决将输入数据转换成输出文本的NLG问题。通过对多数NLG系统总结,我们可以大致把NLG的任务分为:
(1)确定内容
确定内容即决定即将构建的文本中应该包含哪些信息;作为生成过程的第一步,NLG系统需要决定哪些信息应该包含在正在构建的文本中,哪些不应该包含在其中。该部分最大的进步应该算是对齐机制的提出,解决了如何自动学习数据和文本之间的对齐关系的问题。
(2)文本结构
确定文本中呈现信息的顺序;在确定了要传递什么消息之后,NLG系统需要决定它们向读者呈现的顺序。
(3)句子聚合
决定在单个句子中呈现哪些信息;并非文本计划中的每一信息都需要用一个单独的句子来表达;通过将多条消息组合成一个句子,使得生成的文本变得更流畅、更具可读性。尽管也有一些情况认为应避免聚合,总的来说,聚合很难定义,也很难实现,我们可以用各种方式解释,比如从冗余消除到语言结构组合。这里对上述语言进行“聚合”一下,就是如何用言简意赅的话语准确表达想要表达的语言信息。
(4)词汇化
找到正确单词或短语来表达信息;即用什么词或短语来表达消息的构建块。通常情况下,上下文约束在这里也扮演着重要的角色,所以这一点在中文NLG任务中尤为突出。
(5)引用表达式生成
选择单词和短语以标识域对象;这种特征表明与词汇化有着密切的相似性,但本质上的区别在于,引用表达式生成是一项“识别任务,系统需要传递足够的信息来区分一个域实体和其他域实体”。这一个task好抽象,白话解释一下,词汇化阶段主要是选用合适的词或短语表达上下文相关的语义信息,而引用表达式生成阶段的任务首先是识别要表达的对象,然后用合适的词或短语表示它。
(6)语言实现
将所有单词和短语组合成格式良好的句子。这项任务涉及到对句子的成分进行排序,以及生成正确的形态形式,通常还需要插入功能词(如助动词和介词)和标点符号等。
自然语言处理技术的运用
1、机器翻译
机器翻译,又称为自动翻译,是利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程。它是计算语言学的一个分支,是人工智能的终极目标之一,具有重要的科学研究价值。
2、打击垃圾邮件
自然语言处理通过分析邮件中的文本内容,能够相对准确地判断邮件是否为垃圾邮件。目前,贝叶斯(Bayesian)垃圾邮件过滤是备受关注的技术之一,它通过学习大量的垃圾邮件和非垃圾邮件,收集邮件中的特征词生成垃圾词库和非垃圾词库,然后根据这些词库的统计频数计算邮件属于垃圾邮件的概率,以此来进行判定。
3、信息提取
从文本中获取信息意义的方法。信息提取目前已经应用于很多领域,比如商业智能,简历收获,媒体分析,情感检测,专利检索及电子邮件扫描。当前研究的一个特别重要的领域是提取出电子科学文献的结构化数据,特别是在生物和医学领域。
4、文本情感分析
情感分析作为一种常见的自然语言处理方法的应用,可以让我们能够从大量数据中识别和吸收相关信息,而且还可以理解更深层次的含义。比如,企业分析消费者对产品的反馈信息,或者检测在线评论中的差评信息等。
5、自动问答
自动问答是指利用计算机自动回答用户所提出的问题以满足用户知识需求的任务,在回答用户问题时,首先要正确理解用户所提出的问题,抽取其中关键的信息,在已有的语料库或者知识库中进行检索、匹配,将获取的答案反馈给用户。
6、个性化推荐
自然语言处理可以依据大数据和历史行为记录,学习出用户的兴趣爱好,预测出用户对给定物品的评分或偏好,实现对用户意图的精准理解,同时对语言进行匹配计算,实现精准匹配。
自然语言处理技术的难点
自然语言处理的困难有很多,但造成困难的根本原因无外乎是自然语言的文本和对话中广泛存在的各种歧义性或多义性。因为歧义性,很多语言的翻译就会很容易出错,比如百度翻译中的那些在人工翻译的情况下很浅显的一些错误,在百度翻译中也比较普遍。
自然语言中充满了大量的歧义,人类的活动和表达十分复杂,而语言中的词汇和语法规则又是有限的,这就导致了同一种语言形式可能表达了多种不同含义。以汉语为例,汉语一般由字组成词,由词组成句,由句子组成段落,其中含有多层意思的转换。同样形式的语句在不同的语境中可能含有不同的意义,反过来,同样的意思也可以用不同形式的语句表示,这正是语言的魅力所在,却也给自然语言处理带来了困难。
在汉语中,分词问题便属于消歧任务之一。单词是承载语义最小的单元,因此自然语言处理中分词问题是急需解决的。在口语表述中,词和词之间是连贯的,在书写中也是如此。由于汉语不像英语等语言具有天然分词,中文的处理就多了一层障碍。在分词过程中,计算机会在每个单词后面加入分隔符,而有些时候语义有歧义,分隔符的插入就变得困难。比如说在汉语中的看就有
仰视 俯视
环视 窥视
凝视 斜视
扫视 眺望
等种。。。这为自然语言处理带来了较多的麻烦。