学习的心得|笔记
贝叶斯估计,极大似然估计
前两天做了一些极大似然估计和贝叶斯估计的笔记,印象挺深的所以就先记录这一块。
首先先说明一下估计的方法吧,估计的方法包括参数估计和非参数估计,在参数估计中,又包括了最大似然估计和贝叶斯估计。
极大似然估计
最大似然估计的目的是利用已知的样本结果,反推最有可能导致这样参数值。
似然函数
联合概率密度函数P(D|θ)称为相对于{x1,x2,...,xn} θ 的似然函数
l(θ)=P(D|θ)= P(x1,x2,x3,...,xn|θ)=p(x1|θ)p(x2|θ).....*p(xn|θ)
如果 θ'是参数空间中可能使似然函数l(θ)的最大 θ 指则 θ'应该是”最可能“的参数值,那么 θ'就是 θ 的极大似然估计量。是样本集的函数,记作
θ^=d(x1,x2,....,xn)=d(D)
θ^(x1,x2,x3,...,xn)称作极大似然函数估计值
求解极大似然函数
ML估计,求使得出现该组样本的概率最大的 θ 值
θ^=argmax l(θ)=argmax p(x1|θ)*p(x2|θ)*.....*p(xn|θ)
为了方便分析,定义了对数似然函数
H(θ)=ln(θ)
θ^=argmax ln p(x1|θ)*ln p(x2|θ)*.....*ln p(xn|θ)
当未知参数只有一个(θ为标量)时
在似然函数满足连续,可微正则条件下,极大似然估计量是下面微分方程的解:
dl(θ)/dθ=0 或 dln(θ)/dθ=0
当未知参数有多个时(θ为向量)时
则θ可表示为具有S个分量的未知向量 θ=[θ1,θ2,....θs]T
记梯度算子
▽θ=[∂/∂θ1,∂/∂θ2,....∂/∂θn]T
若似然函数满足连续可导的条件,则最大似然函数估计量就是如下方程的解
▽θln(θ)=Pθln p(x1|θ)ln p(x2|θ).....ln p(xn|θ)=0
例题
为了方便理解,我先用课上的例题作为例子。
例题如下


过程就是先写出概率函数,再取对数,再求导,再解方程。
贝叶斯估计
已知样本满足某种概率分布,但参数未知。贝叶斯估计把待估参数看成符合某种先验概率分布的随机变量。对样本进行观测的过程就是把先验概率密度转化为后验概率密度,这样就利用样本信息修正了对参数的初始估计值。
贝叶斯定理
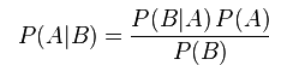
在参数估计中可以写成

贝叶斯估计是在MAP上做进一步拓展,此时不直接估计参数的值,而是允许参数服从一定概率分布。极大似然估计和极大后验概率估计,都求出了参数的值,而贝叶斯估计则不是,贝叶斯估计扩展了极大后验概率估计MAP(一个是等于,一个是约等于)方法,它根据参数的先验分布和一系列观察,求出参数的后验分布,然后求出的期望值,作为其最终值。另外还定义了参数的一个方差量,来评估参数估计的准确程度。
贝叶斯算法过程

贝叶斯估计和极大似然估计的区别
最大似然估计和贝叶斯估计最大区别便在于估计的参数不同,极大似然估计要估计的参数θ被当作是固定形式的一个未知变量而贝叶斯估计则是将参数视为是有某种已知先验分布的随机变量,意思便是这个参数他不是一个固定的未知数,而是符合一定先验分布如:随机变量θ符合正态分布等,那么在贝叶斯估计中除了类条件概率密度p(x|w)符合一定的先验分布,参数θ也符合一定的先验分布。我们通过贝叶斯规则将参数的先验分布转化成后验分布进行求解
在算法的复杂性上,贝叶斯估计要比极大似然估计来的复杂,而当采用的样本数据很有限时,贝叶斯估计误差更小。
机器学习等人工智能领域的前沿技术介绍、展望、应用
自然语言处理
自然语言处理(NLP)是语言学和人工智能的交叉科学,旨在让计算机能够“读懂”人类的语言。其包括的主要范畴有(我们这里说的自然语言处理仅仅指文本相关的):分词、词性标注、命名实体识别、句法分析、关键词抽取、文本分类、自动摘要以及信息检索等等。传统的自然语言处理主要是利用语言学领域本身的知识结合一些统计学的方法来获取语言知识。后来伴随着机器学习浅层模型的发展(如:SVM、逻辑回归等等),自然语言处理领域的研究取得了一定的突破,但在语义消歧、语言的理解等方面还是显得力不存心。近年来,随着深度学习相关技术(DNN、CNN、RNN等)[6][7]取得了显著的进展,其在自然语言处理方面的应用也展现出了明显的优势。
从算法上来看,词向量(word vector)作为深度学习算法在自然语言领域的先驱,有着及其广泛的应用场景,在机器翻译、情感分析等方面均取得了不错的效果。其基本思想是把人类语言中的词尽可能完整地转换成计算机可以理解的稠密向量,同时要保证向量的维度在可控的范围之内,在Bahdanau等人利用LSTM[8]模型结合一些自定义的语料,解决了传统模型的Out of dictionary word问题之后,更使得基于深度学习的自然语言处理较于传统方法有明显的优势。目前,基于深度学习的自然语言处理在文本分类、机器翻译、智能问答、推荐系统以及聊天机器人等方向都有着极为广的应用。
自然语言处理的难点
自然语言处理的困难有很多,但造成困难的根本原因无外乎是自然语言的文本和对话中广泛存在的各种歧义性或多义性。歧义性指在语义分析等处理语言过程中存在的歧义问题,而消除歧义则需要大量知识。对机器来说也是一样,翻译时计算机必须拥有一定的背景知识库。
自然语言中充满了大量的歧义,人类的活动和表达十分复杂,而语言中的词汇和语法规则又是有限的,这就导致了同一种语言形式可能表达了多种不同含义。以汉语为例,汉语一般由字组成词,由词组成句,由句子组成段落,其中含有多层意思的转换。同样形式的语句在不同的语境中可能含有不同的意义,反过来,同样的意思也可以用不同形式的语句表示,这正是语言的魅力所在,却也给自然语言处理带来了困难。
在汉语中,分词问题便属于消歧任务之一。单词是承载语义最小的单元,因此自然语言处理中分词问题是急需解决的。在口语表述中,词和词之间是连贯的,在书写中也是如此。由于汉语不像英语等语言具有天然分词,中文的处理就多了一层障碍。在分词过程中,计算机会在每个单词后面加入分隔符,而有些时候语义有歧义,分隔符的插入就变得困难。