一、模块
1、模块简介
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用python标准库的方法。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
2、模块的引入
在Python中用关键字import来引入某个模块,比如要引用模块math,就可以在文件最开始的地方用import math来引入。在调用math模块中的函数时,必须这样引用:
1 模块名.函数名 2 3 例: 4 5 import math 6 7 import sys
有时候我们只需要用到模块中的某个函数,只需要引入该函数即可,此时可以通过语句
from 模块名 import 函数名1,函数名2....
例:
1 import module 2 3 #从某个模块导入某个功能 4 5 from module.xx.xx import xx 6 7 #从某个模块导入某个功能,并且给他个别名 8 9 from module.xx.xx import xx as rename 10 11 #从某个模块导入所有 12 13 from module.xx.xx import *
模块分为三种:
-
自定义模块
-
内置模块
-
开源模块
3、自定义模块
在Python中,每个Python文件都可以作为一个模块,模块的名字就是文件的名字。
例:
写一个模块(模块文件要和代码文件在同一目录下)
1 #vim moudle_test.py 2 3 #写入如下代码 4 5 #!/usr/bin/env python3 6 7 print ('自定义 moudle') 8 9 #调用 10 11 #vim test.py 12 13 #!/usr/bin/env python3 14 15 #导入自定义模块 16 17 import moudle_test 18 19 #执行test.py
模块文件为单独文件夹 ,文件夹和代码在同一目录下
导入模块其实就是告诉Python解释器去解释那个py文件
-
导入一个py文件,解释器解释该py文件
-
导入一个包,解释器解释该包下的 __init__.py 文件
4、sys.path添加目录
如果sys.path路径列表没有你想要的路径,可以通过 sys.path.append('路径') 添加。
通过os模块可以获取各种目录,例如:
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
1 >>> os.getcwd() 2 3 '/root' 4 5 >>>
os.chdir("目录名") 改变当前脚本工作目录;相当于linux下cd命令
1 >>> os.chdir('/usr/local') 2 3 >>> os.getcwd() 4 5 '/usr/local' 6 7 >>>
os.curdir 返回当前目录: ('.')
1 >>> os.curdir 2 3 '.'
os.pardir 获取当前目录的父目录字符串名:('..')
1 >>> os.pardir 2 3 '..'
os.makedirs('目录1/目录2') 可生成多层递归目录(相当于linux下mkdir -p)
1 >>> os.makedirs('/python/moudle/') 2 3 # ll /python/moudle/
os.removedirs('目录') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
1 >>> os.removedirs('/python/moudle') 2 3 #a目录中除了有一个b目录外,再没有其它的目录和文件。 4 5 #b目录中必须是一个空目录。 如果想实现类似rm -rf的功能可以使用shutil模块
os.mkdir('目录') 生成单级目录;相当于shell中mkdir 目录
1 >>> os.mkdir('/python')
os.rmdir('目录') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir
1 >>> os.rmdir('/python') 2 3 >>> os.rmdir('/python') 4 5 Traceback (most recent call last): 6 7 File "<stdin>", line 1, in <module> 8 9 FileNotFoundError: [Errno 2] No such file or directory: '/python'
os.listdir('目录') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
1 >>> os.listdir('/root') 2 3 ['.Xauthority', 'yaoyao@192.168.42.51', '.py.swp', '.ssh', 'in.sh', '1', 'IPy-0.81.tar.gz', 'Dockerssh', 'id_rsa.pub', 'psutil-2.0.0.tar.gz', '.python_history', '.bashrc', 'ansible', '.bash_history', '.vim', 'IPy-0.81', '.pip', '.profile', '.ansible', 'python', '.dockercfg', 'Docker', 'util-linux-2.27', '.viminfo', 'util-linux-2.27.tar.gz', 'ubuntu_14.04.tar', '__pycache__', 'psutil-2.0.0', 'xx.py', 'ip.py', 'DockerNginx', '.cache', 'dict_shop.py']
os.remove()删除一个文件
1 >>> os.remove('/root/xx.py')
os.rename("原名","新名") 重命名文件/目录
1 >>> os.listdir('/python') 2 3 ['oldtouch'] 4 5 >>> os.rename('oldtouch','newtouch') 6 7 >>> os.listdir('/python') 8 9 ['newtouch']
os.stat('path/filename') 获取文件/目录信息
1 >>> os.stat('newtouch') 2 3 os.stat_result(st_mode=33188, st_ino=1048593, st_dev=51713, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1453442450, st_mtime=1453442450, st_ctime=1453442500)
os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/"
1 >>> os.sep 2 3 '/' 4 5 >>>
os.linesep 输出当前平台使用的行终止符,win下为" ",Linux下为" "
1 >>> os.linesep 2 3 ' '
os.pathsep 输出用于分割文件路径的字符串
1 >>> os.pathsep 2 3 ':'
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
1 >>> os.name 2 3 'posix'
os.system("pwd") 运行shell命令,直接显示
1 >>> os.system('pwd') 2 3 /python 4 5 0
os.environ
1 >>> os.environ 2 3 environ({'_': '/usr/bin/python3', 'SSH_CONNECTION': 省略n个字符
os模块其他语法:
1 os.path模块主要用于文件的属性获取, 2 os.path.abspath(path) 返回path规范化的 3 os.path.split(path) 将path分割成目录和文件名二元组返回 4 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 5 os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素 6 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False 7 os.path.isabs(path) 如果path是绝对路径,返回True 8 os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False 9 os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False 10 os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 11 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 12 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
sys模块 用于提供对解释器相关的操作
1 sys.argv 命令行参数List,第一个元素是程序本身路径 2 sys.modules 返回系统导入的模块字段,key是模块名,value是模块 3 sys.exit(n) 退出程序,正常退出时exit(0) 4 sys.version 获取Python解释程序的版本信息 5 sys.maxint 最大的Int值 6 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 7 sys.platform 返回操作系统平台名称 8 sys.stdout.write('please:') 9 val = sys.stdin.readline()[:-1] 10 sys.modules.keys() 返回所有已经导入的模块名 11 sys.modules.values() 返回所有已经导入的模块 12 sys.exc_info() 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息 13 sys.exit(n) 退出程序,正常退出时exit(0) 14 sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0 15 sys.version 获取Python解释程序的 16 sys.api_version 解释器的C的API版本 17 sys.version_info 18 ‘final’表示最终,也有’candidate’表示候选,serial表示版本级别,是否有后继的发行 19 sys.displayhook(value) 如果value非空,这个函数会把他输出到sys.stdout,并且将他保存进__builtin__._.指在python的交互式解释器里,’_’ 代表上次你输入得到的结果,hook是钩子的意思,将上次的结果钩过来 20 sys.getdefaultencoding() 返回当前你所用的默认的字符编码格式 21 sys.getfilesystemencoding() 返回将Unicode文件名转换成系统文件名的编码的名字 22 sys.setdefaultencoding(name)用来设置当前默认的字符编码,如果name和任何一个可用的编码都不匹配,抛出 LookupError,这个函数只会被site模块的sitecustomize使用,一旦别site模块使用了,他会从sys模块移除 23 sys.builtin_module_names Python解释器导入的模块列表 24 sys.executable Python解释程序路径 25 sys.getwindowsversion() 获取Windows的版本 26 sys.copyright 记录python版权相关的东西 27 sys.byteorder 本地字节规则的指示器,big-endian平台的值是’big’,little-endian平台的值是’little’ 28 sys.exc_clear() 用来清除当前线程所出现的当前的或最近的错误信息 29 sys.exec_prefix 返回平台独立的python文件安装的位置 30 sys.stderr 错误输出 31 sys.stdin 标准输入 32 sys.stdout 标准输出 33 sys.platform 返回操作系统平台名称 34 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 35 sys.maxunicode 最大的Unicode值 36 sys.maxint 最大的Int值 37 sys.version 获取Python解释程序的版本信息 38 sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0
二、时间模块
1)time.localtime([secs]):将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
>>> time.localtime()
time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=14, tm_min=14, tm_sec=50, tm_wday=3, tm_yday=125, tm_isdst=0)
>>> time.localtime(1304575584.1361799)
time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=14, tm_min=6, tm_sec=24, tm_wday=3, tm_yday=125, tm_isdst=0)
2)time.gmtime([secs]):和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
>>>time.gmtime()
time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=6, tm_min=19, tm_sec=48, tm_wday=3, tm_yday=125, tm_isdst=0)
3)time.time():返回当前时间的时间戳。
>>> time.time()
1304575584.1361799
4)time.mktime(t):将一个struct_time转化为时间戳。
>>> time.mktime(time.localtime())
1304576839.0
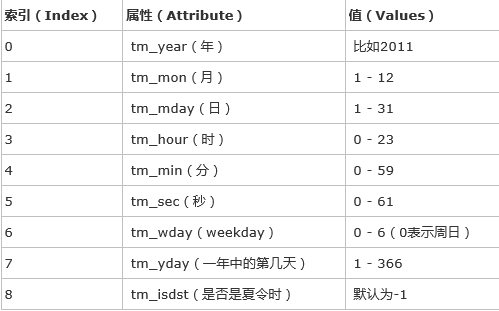
1、datetime()函数返回从1970年1月1日以来的秒数,这是一个浮点数
1 print(datetime.date.today()) #输出格式 2016-01-26 2 3 print(datetime.date.fromtimestamp(time.time()-864400) ) #2016-01-16 将时间戳转成日期格式 4 5 current_time = datetime.datetime.now() # 6 7 print(current_time) #输出2016-01-26 19:04:30.335935 8 9 print(current_time.timetuple()) #返回struct_time格式 10 11 12 13 #datetime.replace([year[, month[, day[, hour[, minute[, second[, microsecond[, tzinfo]]]]]]]]) 14 15 print(current_time.replace(2014,9,12)) #输出2014-09-12 19:06:24.074900,返回当前时间,但指定的值将被替换 16 17 18 19 str_to_date = datetime.datetime.strptime("21/11/06 16:30", "%d/%m/%y %H:%M") #将字符串转换成日期格式 20 21 new_date = datetime.datetime.now() + datetime.timedelta(days=10) #比现在加10天 22 23 new_date = datetime.datetime.now() + datetime.timedelta(days=-10) #比现在减10天 24 25 new_date = datetime.datetime.now() + datetime.timedelta(hours=-10) #比现在减10小时 26 27 new_date = datetime.datetime.now() + datetime.timedelta(seconds=120) #比现在+120s 28 29 print(new_date)
2、time
1 print(time.clock()) #返回处理器时间,3.3开始已废弃 2 print(time.process_time()) #返回处理器时间,3.3开始已废弃 3 print(time.time()) #返回当前系统时间戳 4 print(time.ctime()) #输出Tue Jan 26 18:23:48 2016 ,当前系统时间 5 print(time.ctime(time.time()-86640)) #将时间戳转为字符串格式 6 print(time.gmtime(time.time()-86640)) #将时间戳转换成struct_time格式 7 print(time.localtime(time.time()-86640)) #将时间戳转换成struct_time格式,但返回 的本地时间 8 print(time.mktime(time.localtime())) #与time.localtime()功能相反,将struct_time格式转回成时间戳格式 9 #time.sleep(4) #sleep 10 print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将struct_time格式转成指定的字符串格式 11 print(time.strptime("2016-01-28","%Y-%m-%d") ) #将字符串格式转换成struct_time格式
三、日志模块
1、简单日志打印
1 #导入日志模块 2 import logging 3 #简单级别日志输出 4 logging.debug('[debug 日志]') 5 logging.info('[info 日志]') 6 logging.warning('[warning 日志]') 7 logging.error('[error 日志]') 8 logging.critical('[critical 日志]')
输出:
1 WARNING:root:[warning 日志] 2 ERROR:root:[error 日志] 3 CRITICAL:root:[critical 日志]
可见,默认情况下python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,
这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET)
默认的日志格式为:
日志级别:Logger名称:用户输出消息。
2、灵活配置日志级别,日志格式,输出位置
1 logging.basicConfig(level=logging.DEBUG, 2 format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s', 3 datefmt='%a, %d %b %Y %H:%M:%S', 4 filename='log.log', 5 filemode='w') 6 7 logging.debug('debug message') 8 logging.info('info message') 9 logging.warning('warning message') 10 logging.error('error message') 11 logging.critical('critical message')
日志文件:

在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename: 用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode: 文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format: 指定handler使用的日志显示格式。
datefmt: 指定日期时间格式。(datefmt='%a, %d %b %Y %H:%M:%S',%p)
level: 设置rootlogger(后边会讲解具体概念)的日志级别
stream: 用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。
若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s 用户输出的消息
3.Logger,Handler,Formatter,Filter的概念
logging.basicConfig()(用默认日志格式(Formatter)为日志系统建立一个默认的流处理器(StreamHandler),
设置基础配置(如日志级别等)并加到root logger(根Logger)中)这几个logging模块级别的函数,
另外还有一个模块级别的函数是logging.getLogger([name])(返回一个logger对象,如果没有指定名字将返回root logger)
1).logging库提供了多个组件:Logger、Handler、Filter、Formatter。
Logger 对象提供应用程序可直接使用的接口,
Handler 发送日志到适当的目的地,
Filter 提供了过滤日志信息的方法,
Formatter 指定日志显示格式。
# 创建一个logger
logger = logging.getLogger()
#创建一个带用户名的logger
logger1 = logging.getLogger('liuyao')
#设置一个日志级别
logger.setLevel(logging.INFO)
logger1.setLevel(logging.INFO)
#创建一个handler,用于写入日志文件
fh = logging.FileHandler('log.log')
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
# 定义handler的输出格式formatter
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 给logger添加handler
#logger.addFilter(filter)
logger.addHandler(fh)
logger.addHandler(ch)
# 给logger1添加handler
#logger1.addFilter(filter)
logger1.addHandler(fh)
logger1.addHandler(ch)
#给logger添加日志
logger.info('logger info message')
logger1.info('logger1 info message')
输出:
1 2016-02-03 21:11:38,739 - root - INFO - logger info message 2 2016-02-03 21:11:38,740 - liuyao - INFO - logger1 info message 3 2016-02-03 21:11:38,740 - liuyao - INFO - logger1 info message
对于等级:
1 CRITICAL = 50 2 FATAL = CRITICAL 3 ERROR = 40 4 WARNING = 30 5 WARN = WARNING 6 INFO = 20 7 DEBUG = 10 8 NOTSET = 0
四、序列化 json,pickle
用于序列化的两个模块
-
json,用于字符串 和 python数据类型间进行转换
-
pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load

字典转字符串是序列化用dump
字符串转字典是反序列化用load
反序列化load元素里面必须用双引号""
更加适合跨语言,字符串,基本数据类型
pickle,python所有类型类型的序列化,仅适用于python
五、生成器,迭代器
1、生成器
从Python2.2起,生成器提供了一种简洁的方式帮助返回列表元素的函数来完成简单和有效的代码。
定义:一个函数调用时返回一个迭代器,那这个函数就叫做生成器(generator),如果函数中包含yield语法,那这个函数就会变成生成器
它基于yield指令,允许停止函数并立即返回结果。
此函数保存其执行上下文,如果需要,可立即继续执行。.
1 def func(): 2 print(1111) 3 yield 1 4 print(2222) 5 yield 2 6 print(3333) 7 yield 3 8 print(4444) 9 ret = func() 10 # for i in ret: 11 # print(i) 12 r1= ret.__next__() 13 print(r1) 14 15 r2= ret.__next__() 16 print(r2) 17 18 r3= ret.__next__() 19 print(r3) 20 21 r4= ret.__next__() 22 print(r4)
作用:
这个yield的主要效果呢,就是可以使函数中断,并保存中断状态,中断后,代码可以继续往下执行,过一段时间还可以再重新调用这个函数,从上次yield的下一句开始执行。
(1)迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,知道所有的元素被访问完结束。迭代器只能往前不会后退.
(2) 对于原生支持随机访问的数据结构(如tuple、list),迭代器和经典for循环的索引访问相比并无优势,反而丢失了索引值(可以使用内建函数 enumerate()找回这个索引值)。但对于无法随机访问的数据结构(比如set)而言,迭代器是唯一的访问元素的方式。另外,迭代器的一大优点是不要求事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代到某个元素时才计算该元素,而在这之前或之后,元素可以不存在或者被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如几个G的文件,或是斐波那契数列等等。迭代器更大的功劳是提供了一个统一的访问集合的接口,只要定义了__iter__()方法对象,就可以使用迭代器访问。
迭代器提供两种方法:
(1)__next__() 返回迭代器的下一个元素
1 def myrange(arg): 2 start = 0 3 while True: 4 if start > arg: 5 return 6 yield start 7 start += 1 8 ret =myrange(2) 9 r = ret.__next__() 10 print(r) 11 r = ret.__next__() 12 print(r) 13 r = ret.__next__() 14 print(r) 15 r = ret.__next__() 16 print(r) 17 18 19 输出: 20 0 21 1 22 2 23 如果有第四个就报错
(2)__iter__()返回迭代器对象本身
1 names = iter(['liu','yao','sb']) 2 print(names.__iter__()) 3 输出: 4 <list_iterator object at 0x00000000006DB6D8>