参考文献
%%%毒瘤大帝:http://olddrivertree.blog.uoj.ac/blog/4656
回滚莫队:https://wa-automaton.github.io/2019/06/20/一些奇怪的莫队技巧/
莫队的在线化改造:https://www.luogu.org/blog/shoko/moqueue
我认为讲得特别好的一个博客,大米饼:https://www.cnblogs.com/Paul-Guderian/p/6933799.html
新的一种树上莫队形式:https://www.cnblogs.com/zwfymqz/p/9223425.html
暴力大帝:分块
貌似我并没有写什么关于分块的题目。。。
那你些什么分块呀!
但是我因为被坑蒙拐骗标签所骗,做了两道分块题目,然后。。。
讲解
分块,意思就是对原来的块分块。
而每个块的大小我们设为(S),那么不就是大概有(frac{n}{S})块了吗。
然后有些题目我们可以通过维护块内的信息达到一个类似(O(nS+frac{n^2}{S}))的一个时间复杂度。
所以对于大部分的题目,我们的(S)取得是(sqrt{n}),这样子每个块的大小跟块的数量差不多,就能使复杂度达到一个均衡。
但是在莫队的一道卡常题我就乘了2.3。。。
应用
带插入求当前比它小的数字个数
假设要求你插入一个数,然后求出目前队列里面有多少个数字比它小。
有两种写法。(主要是后面需要用到这个)
首先肯定是要基于权值分块的。
1
这种写法是插入(O(1)),然后查询(O(sqrt{n}))。
用(cnt_{i})表示的是第(i)个块内有多少个数字。
然后在查询的时候,然后循环一遍前面的块,然后循环在当前块比他小的数字有多少个。
2
这种写法是插入(O(sqrt{n})),然后查询(O(1))。
用(cnt1_{i})表示的是前(i)个块有多少个数字,(cnt2_{i})表示的是(i)所在的当前块从(L)一直到(i)有多少个数字。
然后插入的时候维护一下,查询直接取就行了。(注意:在大多数情况下,在取答案的时候一般要判断这个位置是不是块头或者块尾)。
明明就是加了个前缀和,SB的博主竟然花了几分钟时间去想这个东西。
静态区间最大值
大佬:这难道不是一个RMQ就搞定的东西吗?
代码短,易骗分,似乎成了这个的标签。
你只需要维护块内的最大值,然后查询(l,r),设(be_{i})表示的是(i)所在的块的编号,那么查询(be_{l}+1->be_{r}-1)的最大值(也就是中间成型块的最大值),然后解决左右残渣的最大值。
当然,如果带修改的话,你可以无聊的给每个块套上两个堆,一个删除,一个插入的那种神仙堆,但是可以的话你还是打(splay)还是(fhq treap)吧。
这种骗分的神仙玩意还是少用为好。而且套上一个堆时间复杂度不就成了(O(nsqrt{n}log_{n}))了。。。一般是可以卡的。
给个图看看:
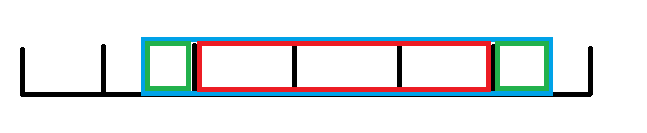
询问蓝色,红色的块,绿色的边角料。
练习(高能警告)
这些题目别看我了,我都是看了题解的,我没有这么强。。。
在线求区间逆序对
1s 500MB
给你一个长为n的排列,m次询问,每次查询一个区间的逆序对数,强制在线
输入格式
第一行两个数n,m
第二行n个数表示这个序列
之后m行,每行两个数表示查询的区间
本题强制在线,每次查询输入的数要xor上lastans,第一次询问默认lastans=0
输出格式
输出m行,每行一个数表示这次询问的答案
输入输出样例
输入 #1 复制
4 1
1 4 2 3
2 4
输出 #1 复制
2
说明/提示
n,m <= 100000
我们已经有了低于n^1.5的算法
Source By nzhtl1477
低于(n^{1.5})的复杂度不是分块更不是莫队做法,是来自遥远星球的,不是我们应该关注的东西。
强制在线呢QAQ,那么我们可以设(F[i][j])表示的是(i-j)块之间的逆序对数,(ff[i][j])表示的是前(i)个数字对于第(j)个块的逆序对数(注意:并不统计(i(L_j<=i<=R_j))对于第(j)块的逆序对数,同时(L,R)表示的是块的左右端点。
我们发现(F[i][j]=F[i][j-1]+F[i+1][j]-F[i+1][j-1]+ff[R_i][j]-ff[L_i-1][j])(容斥原理算出(i,j,i+1->j-1)内部的逆序对数并且算出(i,j)与(i+1->j-1)的逆序对数,同时用(ff)的容斥原理进一步算出(l,r)两个块的逆序对数)。
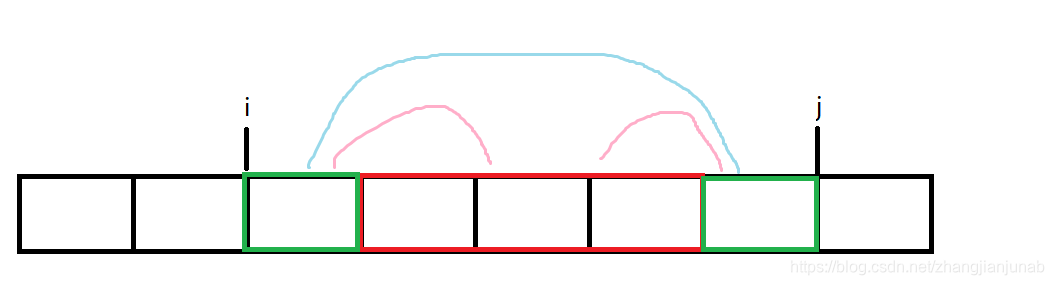
当然,这个公式只能计算(i!=j)的,那怎么办?对于(ff[i][i])我们怎么算?
我们继续定义(pre_i)表示的是(i)到(i)所在的块头的逆序对,(las_{i})则是到块尾。那么自然使用树状数组进行处理啦,时间复杂度(O(nlog_n)),而且(F[i][i])也可以在这里处理。
而(ff)怎么处理呢?对于每个块,我们都把块内排序同时对已经排序了的(1-n)的数字进行一遍归并排序,算出每个数字对于这个块的逆序对数,然后做一遍前缀和,一次为(n),那么不就是(nsqrt{n})了吗?
不会归并排序求逆序对?
首先你得会归并排序(不会上网搜吧。)
然后每当(a[l]>=b[r]),然后把(r)塞进去的时候,就可以算出(a)里面有多少个数字小于(b[r]),当然可以举一反三,只要思路过得去就行了。
下面求逆序对数大多数都是左右区间已经用(sort)排序,就用一次归并求出左右区间之间的贡献。
预处理处理完之后,就可以直接转到查询了。
对于每一个询问(l,r)。
在这里希望大家记住一个事情:对于区间(z),从其任意地方切成(x,y)两个区间,我们知道了(x,y)的逆序对数,那么(z)的逆序对数为(x,y)各自的逆序对数加上(x,y)相对的逆序对数。
- 当(l,r)在同一个块的时候。
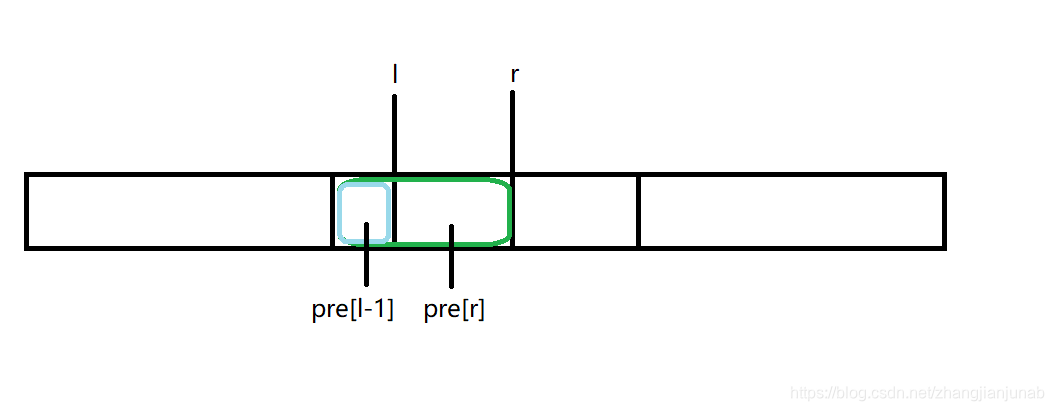
设(l,r)在(x)块
只需要用(pre_{r}-pre_{l-1}-)((L_x->l-1))和((l->r))的逆序对数(类似归并排序)就是答案了,而且是(sqrt{n})
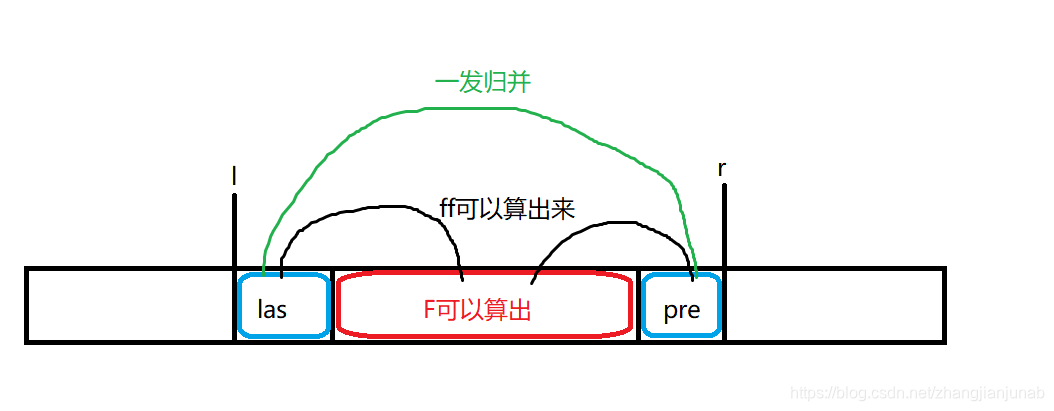
- 不在同一块
那也很好办,我们先(ans=F[be_l+1][be_r-1]+las_l+pre_r),然后对于左右的边角料,我们循环一遍中间的块并且通过(ff)算出这些边角料对这个块的逆序对数,然后再用类似归并排序的方法求互左右边角料的逆序对数。
不过我们再次把(ff)加起来,然后做了一遍二维前缀和(也就是类似在一个二维平面内求出制定矩阵的和)。
然后终于上上我们和蔼可亲的代码了:
//哎,真的是很从头卡到尾了。。。
#pragma GCC optimize(2)
#pragma GCC optimize(3)
#pragma GCC optimize("Ofast")
#pragma GCC optimize("inline")
#pragma GCC optimize("-fgcse")
#pragma GCC optimize("-fgcse-lm")
#pragma GCC optimize("-fipa-sra")
#pragma GCC optimize("-ftree-pre")
#pragma GCC optimize("-ftree-vrp")
#pragma GCC optimize("-fpeephole2")
#pragma GCC optimize("-ffast-math")
#pragma GCC optimize("-fsched-spec")
#pragma GCC optimize("unroll-loops")
#pragma GCC optimize("-falign-jumps")
#pragma GCC optimize("-falign-loops")
#pragma GCC optimize("-falign-labels")
#pragma GCC optimize("-fdevirtualize")
#pragma GCC optimize("-fcaller-saves")
#pragma GCC optimize("-fcrossjumping")
#pragma GCC optimize("-fthread-jumps")
#pragma GCC optimize("-funroll-loops")
#pragma GCC optimize("-fwhole-program")
#pragma GCC optimize("-freorder-blocks")
#pragma GCC optimize("-fschedule-insns")
#pragma GCC optimize("inline-functions")
#pragma GCC optimize("-ftree-tail-merge")
#pragma GCC optimize("-fschedule-insns2")
#pragma GCC optimize("-fstrict-aliasing")
#pragma GCC optimize("-fstrict-overflow")
#pragma GCC optimize("-falign-functions")
#pragma GCC optimize("-fcse-skip-blocks")
#pragma GCC optimize("-fcse-follow-jumps")
#pragma GCC optimize("-fsched-interblock")
#pragma GCC optimize("-fpartial-inlining")
#pragma GCC optimize("no-stack-protector")
#pragma GCC optimize("-freorder-functions")
#pragma GCC optimize("-findirect-inlining")
#pragma GCC optimize("-fhoist-adjacent-loads")
#pragma GCC optimize("-frerun-cse-after-loop")
#pragma GCC optimize("inline-small-functions")
#pragma GCC optimize("-finline-small-functions")
#pragma GCC optimize("-ftree-switch-conversion")
#pragma GCC optimize("-foptimize-sibling-calls")
#pragma GCC optimize("-fexpensive-optimizations")
#pragma GCC optimize("-funsafe-loop-optimizations")
#pragma GCC optimize("inline-functions-called-once")
#pragma GCC optimize("-fdelete-null-pointer-checks")
//听我解释不是你们想想的那样QAQ
#include<cstdio>
#include<cstring>
#include<cmath>
#include<algorithm>
#define N 100005
#define KUAI 810
#define KK 150
using namespace std;
inline char nc(){
static char buf[100000],*p1=buf,*p2=buf;
return p1==p2&&(p2=(p1=buf)+fread(buf,1,100000,stdin),p1==p2)?EOF:*p1++;
}
typedef long long LL;
int a[N],n,m,ls[N],what[N],tot;
inline bool cmp2(int x,int y){return a[x]<a[y];}//离散化只是为了树状数组做贡献
template <typename T>
inline void getz(T &x)
{
register char c=nc();register T f=1;x=0;
while(c<'0' || c>'9')c=='-'?f=-1:0,c=nc();
while(c>='0' && c<='9')x=(x<<3)+(x<<1)+(c^48),c=nc();
x*=f;
}//卡常快读肯定是需要的啦
struct pre_do
{
int x,id;
}li1[N],li2[N];
inline bool cmp(pre_do x,pre_do y){return x.x<y.x;}
int me1[KUAI],me2[KUAI];
int merge(int *x,int *y,register int lx,register int ly)
{
register int ans=0,l=1,r=1;
while(l<=lx && r<=ly)(x[l]<=y[r]/*严格写成<=*/)?(l++,ans+=r-1):(r++);//统计右边小于我的数字有多少
ans+=ly*(lx-l+1);
return ans;
}//归并排序求逆序对
int bst[N];
inline int lowbit(register int x){return x&-x;}
inline void change(register int x,register int f){while(x<=tot)bst[x]+=f,x+=lowbit(x);}
inline int findans(register int x)
{
register int ans=0;
while(x)ans+=bst[x],x-=lowbit(x);
return ans;
}
//标准的树状数组二连击
LL ff[N][KK]/*前i个数字能与第i个块产生多少的逆序对*/,F[KK][KK]/*块于块之间的逆序对数*/;//可以预处理出来。
int be[N],block,L[KK],R[KK];
int pre[N],las[N];
inline LL getf(register int l,register int r,register int ll,register int rr){return ff[r][rr]-ff[l-1][rr]-ff[r][ll-1]+ff[l-1][ll-1];}//二维前缀和
void init()
{
for(register int i=1;i<=n;++i)li1[i].x=a[i],li1[i].id=i,li2[i]=li1[i];//先赋值
sort(li1+1,li1+n+1,cmp);//排序
for(register int i=1;i<=be[n];++i)
{
register int l=1,r=L[i];
sort(li2+L[i],li2+R[i]+1,cmp);//块内排序
register int k=r;//表示块内与它相同的数字
while(k<R[i] && li2[k+1].x==li2[r].x)k++;
while(l<=n && r<=R[i])
{
if(li1[l].x<=li2[r].x)
{
(li1[l].id<L[i]/*li2[r].id*/)?ff[li1[l].id][i]+=r-L[i]:(li1[l].id>R[i]/*li2[r].id*/?ff[li1[l].id][i]+=R[i]-k+(k-r+1)*(li2[k].x!=li1[l].x)/*特殊处理li1[l].x==li2[r].x的情况*/:0);
l++;
}
else
{
r++;
while(k<R[i] && li2[k+1].x==li2[r].x)k++;
}
}
while(l<=n)
{
(li1[l].id<L[i]/*li2[r].id*/)?ff[li1[l].id][i]+=R[i]-L[i]+1:0;
l++;
}//这里指的是归并排序
/*
在这里警示大家,不要打注释内的这种打法,无法通过自己和自己归并算出自己对自己的贡献的!
因为即使你知道l和r的id比较,但是你无法知道后面的数字是不是都是大于或小于l的id的。
*/
for(register int j=1;j<=n;++j)ff[j][i]+=ff[j-1][i];
for(register int j=L[i]+1;j<=R[i];++j)change(ls[j-1],1),pre[j]=j-L[i]-findans(ls[j])+pre[j-1];
change(ls[R[i]],1);
LL x=F[i][i]=pre[R[i]];
for(register int j=L[i];j<R[i];++j)change(ls[j],-1),las[j]=x,x-=findans(ls[j]-1);//利用上一次的树状数组。说实话,SB的我是真的没想到
change(ls[R[i]],-1);
}
for(register int i=1;i<be[n];++i)
{
for(register int j=be[n]-i;j>=1;j--)
{
register int x=i+j;
F[j][x]=F[j+1][x]+F[j][x-1]-F[j+1][x-1]+ff[R[j]][x]-ff[L[j]-1][x];
}
}//求出F
for(register int i=1;i<=n;++i)
{
for(register int j=1;j<=be[n];++j)ff[i][j]+=ff[i][j-1];
}//二维前缀和预处理
}
int main()
{
getz(n);getz(m);block=sqrt(n)*2.35;//咳咳,前面说的就是在这里卡常的,交了贼多发
for(register int i=1;i<=n;++i){getz(a[i]);what[i]=i;}
sort(what+1,what+n+1,cmp2);
a[0]=a[what[1]]-1;
for(register int i=1;i<=n;++i)
{
ls[what[i]]=tot+=a[what[i]]!=a[what[i-1]];
be[i]=(i-1)/block+1;//所在的块
}//离散化
for(register int i=1;i<=be[n];++i)L[i]=R[i-1]+1,R[i]=R[i-1]+block;//L与R
R[be[n]]=n;/*结尾的块特判一下*/
init();
register LL last=0;
while(m--)
{
register LL x,y;getz(x);getz(y);x^=last;y^=last;
register int tx=be[x],ty=be[y],ed=R[tx];
if(tx==ty)//同块
{
register int l=0,r=0;
for(register int i=L[tx];i<=ed;++i)li2[i].id<x?me1[++l]=li2[i].x:((x<=li2[i].id && li2[i].id<=y)?me2[++r]=li2[i].x:0);//提前处理归并的数组
printf("%lld
",last=(pre[y]-pre[x-1]*(x!=L[tx])-merge(me1,me2,l,r)));
}
else
{
register int l=0,r=0;
for(register int i=L[tx];i<=ed;++i)li2[i].id>=x?me1[++l]=li2[i].x:0;//提前处理归并的数组
ed=R[ty];//听说调用次数少一点可以卡常QAQ
for(register int i=L[ty];i<=ed;++i)li2[i].id<=y?me2[++r]=li2[i].x:0;//提前处理归并的数组
printf("%lld
",last=F[tx+1][ty-1]+las[x]+pre[y]+merge(me1,me2,l,r)+getf(x,R[tx],tx+1,ty-1)+getf(L[ty],y,tx+1,ty-1));
}
}
return 0;
}
LXL大毒瘤
在线众数
2s 62.5MB
给你一个长为n的序列a,m次询问,每次查询一个区间的众数的出现次数,强制在线
输入格式
第一行两个数n,m
第二行n个数表示这个序列
之后m行,每行两个数表示查询的区间
本题强制在线,每次查询输入的数要xor上lastans,第一次询问默认lastans=0
输出格式
输出m行,每行一个数表示这次询问的答案
输入输出样例
输入 #1 复制
4 1
2 3 3 3
2 4
输出 #1 复制
3
说明/提示
n,m <= 500000,0 <= ai <= 1000000000
如果有人这题得到了低于nsqrtn复杂度的做法,请发表论文,让我们康康哦~
听说可能已经有了低于n^1.5的算法
Source By nzhtl1477
提前处理块与块之间的众数的出现次数,时间复杂度是(O(nsqrt{n}))
然后我们离散化一下,用vector按顺序储存每个权值的数字分别在数组中出现在哪里。
对于每个查询(l,r),照样直接找到中间成型块的答案(ans),处理边角料。
对于左边的边角料,从大往小循环,对于当前数字(x),假设(x)在(vector[x])的位置是(i)(这里从0开始),那么如果(vector[x][i+ans])如果存在并且小于等于(R_{be_r-1})的话,(ans++)。(也就是不断逼近答案)
对于右边的边角料,从小往大循环,对于当前数字(x),假设(x)在(vector[x])的位置是(i)(这里从0开始),那么如果(vector[x][i-ans])如果存在并且大于等于(l)的话,(ans++)。
其实也就是模拟不断往区间内添加数字的过程。
//这道题目主要是思路麻烦,但是代码上是没有太多的问题的。
#include<cstdio>
#include<cstring>
#include<cmath>
#include<algorithm>
#include<vector>
#define N 510000
#define KUAI 810
using namespace std;
int ff[KUAI][KUAI],L[KUAI],R[KUAI],be[N],block;
int n,m,a[N],ls[N],what[N],tot;
vector<int> qmq[N];int qwq[N];//表示每个点在vector中的位置
inline bool cmp(int x,int y){return a[x]==a[y]?(x<y):(a[x]<a[y]);}
int cnt[N];
inline int mymax(int x,int y){return x>y?x:y;}
int main()
{
scanf("%d%d",&n,&m);block=sqrt(n);
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);what[i]=i;
be[i]=(i-1)/block+1;
}
for(int i=1;i<=be[n];i++)L[i]=R[i-1]+1,R[i]=i*block;R[be[n]]=n;
sort(what+1,what+n+1,cmp);
a[0]=a[what[1]]-1;
for(int i=1;i<=n;i++)
{
int x=what[i];
qmq[ls[x]=tot+=(a[x]!=a[what[i-1]])].push_back(x);
qwq[x]=qmq[ls[x]].size()-1;
}
for(int i=1;i<=be[n];i++)
{
int x=i,mmax=0;//cnt[0]永远是0
memset(cnt+1,0,tot<<2);
for(int j=L[i];j<=n;j++)
{
mmax=mymax(++cnt[ls[j]],mmax);
if(j==R[x])ff[i][x]=mmax,x++;
}
}
int ans=0/*次数*/;
while(m--)
{
int l,r;scanf("%d%d",&l,&r);l^=ans;r^=ans;
l>r?l^=r^=l^=r:0;
int tx=be[l],ty=be[r];
ans=ff[tx+1][ty-1];
for(int i=R[tx];i>=l;i--)
{
int len=qmq[ls[i]].size()-1/*表示的是vector中的最大坐标*/,now=qwq[i]+ans;
ans+=(now<=len && qmq[ls[i]][now]<L[ty]/*相当于<=R[ty-1]*/);//更新答案。
}
for(int i=L[ty];i<=r;i++)
{
int now=qwq[i]-ans;
ans+=(now>=0 && qmq[ls[i]][now]>=l);//更新答案。
}
printf("%d
",ans);
}
return 0;
}
我经历了什么!!!!
莫队
一看就知道肯定会有一坨莫队形式。。。
普通莫队是由我们厉害的莫涛队长提出的(不是发明,只能说归纳了形式),然后其他的形式则由我们后人提出。
普通莫队
例题
博主大毒瘤,暴力的例题怎么是紫的!!!我怕不是被骗了!
题目描述
作为一个生活散漫的人,小Z每天早上都要耗费很久从一堆五颜六色的袜子中找出一双来穿。终于有一天,小Z再也无法忍受这恼人的找袜子过程,于是他决定听天由命……
具体来说,小Z把这N只袜子从1到N编号,然后从编号L到R(L 尽管小Z并不在意两只袜子是不是完整的一双,甚至不在意两只袜子是否一左一右,他却很在意袜子的颜色,毕竟穿两只不同色的袜子会很尴尬。
你的任务便是告诉小Z,他有多大的概率抽到两只颜色相同的袜子。当然,小Z希望这个概率尽量高,所以他可能会询问多个(L,R)以方便自己选择。
然而数据中有L=R的情况,请特判这种情况,输出0/1。
输入格式
输入文件第一行包含两个正整数N和M。N为袜子的数量,M为小Z所提的询问的数量。接下来一行包含N个正整数Ci,其中Ci表示第i只袜子的颜色,相同的颜色用相同的数字表示。再接下来M行,每行两个正整数L,R表示一个询问。
输出格式
包含M行,对于每个询问在一行中输出分数A/B表示从该询问的区间[L,R]中随机抽出两只袜子颜色相同的概率。若该概率为0则输出0/1,否则输出的A/B必须为最简分数。(详见样例)
输入输出样例
输入 #1 复制
6 4
1 2 3 3 3 2
2 6
1 3
3 5
1 6
输出 #1 复制
2/5
0/1
1/1
4/15
说明/提示
30%的数据中 N,M ≤ 5000;
60%的数据中 N,M ≤ 25000;
100%的数据中 N,M ≤ 50000,1 ≤ L < R ≤ N,Ci ≤ N。
小妖怪,我骗你干嘛,就是这样的。
思路点拨
求概率?那么就是区间内合法的情况(÷)所有的情况对吧,那么所有的情况可以直接组合数学算出来,然后合法的情况就是区间内所有相同的袜子的数量两两组合算出来的情况。
如:(1,1,2,2),那么总情况为:(4*(4-1)/2=6),然后有两个(1),(2*(2-1)/2=1),(2)同理,所以就是(1+1)/6=1/3$啦。
普通莫队解析
但是貌似我们每次暴力处理一个区间的话,时间复杂度是(O(n^2))的,不行!我们要逆天改命,我们发现了一个事情,就是当我们求出了区间(l,r)的信息的时候,是可以通过删除这个目前的值加上新的值来实现(l,r)指针的左右移动的,且每次移动的代价是(O(1))的,也就是说我们可以(O(1))从([l,r])转移到([l+1,r+1])甚至更多地方。
那么我们就可以对(l)进行排序,相同的话对(r)进行排序。
但是最坏情况下(r)的移动还是(n^2)级别的呢。
我们看样子需要更加快速的排序!!!!!
这个时候我们对于每个位置进行一个分块!
设块大为(S)。
先对(l)排序,当(l)在同一个块的时候就对(r)进行排序,那么对于每个块,(r)从小到大转移一遍,也就是说(r)的移动次数是(frac{n^2}{S})级别的。
但是(l)呢,我们知道(l)也是一遍从小到大,然后(n)次,但是在一个块内不是从大到小的,我们会发现一次块头一次块尾,我们就要为之贡献(2S)的移动次数了,但是我们发现对于以此查询的(l)移动,如果就在当前的块,最多移动(S),转移到下个块最多(2S),也就是(mS)级别的次数。
而(n=m),也就是说复杂度是(O(nS+frac{n^2}{S})),当(S=sqrt{n})时,时间复杂度最小到了(O(nsqrt{n}))。
那么我们只要从一开始维护(l,r),然后保证维护答案为(l->r(l<=r)),然后一直跳一直爽就行了。
代码
#include<cstdio>
#include<cstring>
#include<cmath>
#include<algorithm>
#define N 51000
using namespace std;
typedef long long LL;
int n,m,a[N];
struct question
{
int l,r,id;
}q[N];
struct node
{
LL l,r;
}ans[N];
LL cnt[N],an1/*分子*/,an2/*分母*/;
int be[N],lim;
inline bool cmp(question x,question y){return be[x.l]==be[y.l]?x.r<y.r:(x.l<y.l);}
inline void ser(int x,LL y/*原本的r-l+1*/,LL f){an1+=(cnt[a[x]]*2+f)*f-f;cnt[a[x]]+=f;an2+=(2*y+f)*f-f;}//f=1为插入一个颜色,f=-1为删除一个颜色
inline LL gcd(LL x,LL y){return !x?y:gcd(y%x,x);}
int main()
{
scanf("%d%d",&n,&m);lim=sqrt(n);
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
for(int i=1;i<=m;i++){scanf("%d%d",&q[i].l,&q[i].r);q[i].id=i;}
for(int i=1;i<=n;i++)be[i]=(i-1)/lim+1;
sort(q+1,q+m+1,cmp);
int l=1,r=0;
for(int i=1;i<=m;i++)
{
while(l>q[i].l)ser(l-1,LL(r-l+1),1),l--;
while(r<q[i].r)ser(r+1,LL(r-l+1),1),r++;
while(r>q[i].r)ser(r,LL(r-l+1),-1),r--;
while(l<q[i].l)ser(l,LL(r-l+1),-1),l++;
int x=q[i].id;
if(l==r){ans[x].l=0;ans[x].r=1;continue;}//l==r的时候要特判,不然的话an2=0
LL k=gcd(an1,an2);
ans[x].l=an1/k;ans[x].r=an2/k;
}
for(int i=1;i<=m;i++)printf("%lld/%lld
",ans[i].l,ans[i].r);
return 0;
}
终于看到比较友善的代码了QAQ。
适用范围
- 可以用一个较低的时间复杂度完成指针转移
- 支持离线!!!!!!
- 时间复杂度允许你卡过去。(有的大毒瘤出题人不会放莫队过的。)
- 没有任何的修改。
小结
但是莫队的形式是可以千变万化的,比如有一次我就想到了一种思路,就是对于(l)到了新的块的询问,我们是可以清空结果,并且让(l=r-1),也是一种新的莫队形式,因为是暴力,且复杂度证明存在巨大的发挥空间,所以莫队可以衍生出许多打法(常数小不小就是一回事了),当然,莫队的常数一般都很小的。
甚至有的衍生版本多了个名字:回滚莫队。
当然,如果你闲的没事干,你可以试试把莫队发展到更多的指针,没说不可以。二维莫队
带修莫队
不是说莫队不支持修改吗,啊啊啊。
我说的是普通莫队QMQ。
例题
2s 500MB
墨墨购买了一套N支彩色画笔(其中有些颜色可能相同),摆成一排,你需要回答墨墨的提问。墨墨会向你发布如下指令:
1、 Q L R代表询问你从第L支画笔到第R支画笔中共有几种不同颜色的画笔。
2、 R P Col 把第P支画笔替换为颜色Col。
为了满足墨墨的要求,你知道你需要干什么了吗?
输入格式
第1行两个整数N,M,分别代表初始画笔的数量以及墨墨会做的事情的个数。
第2行N个整数,分别代表初始画笔排中第i支画笔的颜色。
第3行到第2+M行,每行分别代表墨墨会做的一件事情,格式见题干部分。
输出格式
对于每一个Query的询问,你需要在对应的行中给出一个数字,代表第L支画笔到第R支画笔中共有几种不同颜色的画笔。
输入输出样例
输入 #1 复制
6 5
1 2 3 4 5 5
Q 1 4
Q 2 6
R 1 2
Q 1 4
Q 2 6
输出 #1 复制
4
4
3
4
说明/提示
对于30%的数据,n,m≤10000
对于60%的数据,n,m≤50000
对于所有数据,n,m≤133333
所有的输入数据中出现的所有整数均大于等于1且不超过10^6。
本题可能轻微卡常数
带修莫队讲解
本题中会发现转移也是(O(1))的,离散化都不用。
带修改怎么办,啊啊啊啊。
难道我大莫队党竟歇菜于带修?伤风筋骨贴
不不不,只要功夫深,铁杵磨成针。
在暴力之下在大佬的创新下,发现只要多加一个时间的指针就可以了,也就是加个跳的指针为时间!我们排序也是,只是当(l)在同一个块的时候,看看(r)是不是也在同一个块,如果在,就按(tim)排序,否则按(r)排序。
设块的大小为(S),修改(t)次,查询(m)次,(n)个点。
那么(l)指针的移动次数为(mS)次,这可以不用说了,但是(r)这就让我们很为难了。
会发现,当固定一个(l)块的时候,(r)会从小到大移动(n)次,也就是说如果有(frac{n^2}{S^2})个询问的话时间复杂度最高会去到(O(frac{n^2}{S})),这时我们假设每个询问(l)均匀的分布在了每个块,(r)在(l)在同个块的情况下均匀分布在每个块(不是的话时间复杂度会更小),此后每加一个询问,在最坏情况下,会对(r)造成(S)的移动次数。(因为固定了(l,r)在一个块中),那么移动次数最大就是(mS+frac{n^2}{S})。
而(tim)的移动次数就特别好计算了,当(l)和(r)分别位于不同块的时候,就是有(frac{n^2}{S^2})种情况,那么也就是说我们的(tim)移动次数的级别是(frac{n^2t}{S^2})的。
当(n=m=t)时,时间复杂度就为:(O(nS+frac{n^3}{S^2}))(这里(frac{n^2}{S})被省略是因为(frac{n^2}{S}<frac{n^3}{S^2})),有大佬证明过,当(S=n^{frac{2}{3}})时,时间复杂度最小,为(n^{frac{5}{3}})。(其实已经比(n^2)小巨多了,不信你在计算器试试(100000))其实时间复杂度的证明你只要证证(nS=frac{n^3}{S^2})就可以证出来了。
代码
// luogu-judger-enable-o2
//被你发现啦!!!
#include<cstdio>
#include<cstring>
#include<cmath>
#include<algorithm>
#define N 210000
#define M 1100000
using namespace std;
inline int getz()
{
int x=0,f=1;char c=getchar();
while(c>'9' || c<'0')c=='-'?f=-1:0,c=getchar();
while('0'<=c && c<='9')x=(x<<3)+(x<<1)+(c^48),c=getchar();
return x*f;
}
struct change
{
int x,old,now;
}chan[N];int clen;
struct node
{
int l,r,tim,id;
}qu[N];int len,an[N];
int cnt[M],ans;
int be[N],block;
int a[N],n,m;
inline void bian(int x,int f){cnt[x]+=f;ans+=((cnt[x]-f==0)!=(cnt[x]==0))*f;}
inline bool cmp(node x,node y){return be[x.l]==be[y.l]?(be[x.r]==be[y.r]?x.tim<y.tim:x.r<y.r):x.l<y.l;}//ÅÅÐò
int main()
{
n=getz();m=getz();block=pow(n,0.666666);//这里可以直接打2.0/3
for(int i=1;i<=n;i++)
{
a[i]=getz();
be[i]=(i-1)/block+1;
}
for(int i=1;i<=m;i++)
{
char st[10];int x,y;scanf("%s",st);x=getz();y=getz();
if(st[0]=='R')chan[++clen].x=x,chan[clen].old=a[x],chan[clen].now=a[x]=y;
else qu[++len].l=x,qu[len].r=y,qu[len].tim=clen,qu[len].id=len;
}
sort(qu+1,qu+len+1,cmp);
int l=1,r=0,tim=clen;
for(int i=1;i<=len;i++)
{
while(qu[i].tim<tim)
{
int x=chan[tim].x;
if(l<=x && x<=r)bian(a[x],-1),bian(chan[tim].old,1);
a[x]=chan[tim].old;
tim--;
}//时间节点跑一跑
while(qu[i].tim>tim)
{
tim++;
int x=chan[tim].x;
if(l<=x && x<=r)bian(a[x],-1),bian(chan[tim].now,1);
a[x]=chan[tim].now;
}//跑一跑
while(qu[i].l<l)bian(a[--l],1);
while(qu[i].l>l)bian(a[l++],-1);
while(qu[i].r>r)bian(a[++r],1);
while(qu[i].r<r)bian(a[r--],-1);
an[qu[i].id]=ans;
}
for(int i=1;i<=len;i++)printf("%d
",an[i]);
return 0;
}
小结
使用范围:其实就比普通莫队多了个支持修改。
树上莫队
例题
题目描述
给定一个n个节点的树,每个节点表示一个整数,问u到v的路径上有多少个不同的整数。
输入格式
第一行有两个整数n和m(n=40000,m=100000)。
第二行有n个整数。第i个整数表示第i个节点表示的整数。
在接下来的n-1行中,每行包含两个整数u v,描述一条边(u,v)。
在接下来的m行中,每一行包含两个整数u v,询问u到v的路径上有多少个不同的整数。
输出格式
对于每个询问,输出结果。 贡献者:つるまる
输入输出样例
输入 #1 复制
8 2
105 2 9 3 8 5 7 7
1 2
1 3
1 4
3 5
3 6
3 7
4 8
2 5
7 8
输出 #1 复制
4
4
思路点拨
转移怕不是个(cnt+)离散化就能搞定的事情,但是我们还缺一个能在树上跑的莫队。
难道不行了吗!这么好的紫题就没了,还想装逼来着。
树上莫队讲解
莫队为什么不能支持树上?
怎么可能不支持在树上。
我们只是需要在树上找到一种分块的方式使得满足在平常序列那样的复杂度罢了。
首先(l,r)分别表示的是根节点到(l,r)这两条路径的信息,同时如果这个路径有的点重合了,就相当于用容斥原理把这个信息给踢出去,所以我们要设一个(used)表示这个点是否被走过,如果被走过现在又走一遍,要么两条路径重合,要么一条路径回溯了,这两种情况都可以(DEL),岂不美哉。
在这里,我们设块的大小为(S)。
做一遍DFS,询问到(x)就把(x)放到栈里面,并且存一个(now)表示(x)这个点在栈里面的位置是在哪里,如果询问完一个儿子以后,看看目前栈的长度(-now≥S)的话,那么我们就把栈里面目前堆顶的节点到(now+1)全部放到一个块内,然后到最后会把(x)号节点以及(x)中暂未分块的儿子一起传到父亲。
另外别忘记DFS完后,对栈里面剩余节点分个块,栈里面至少有根节点。
效果图我是不会告诉你们为什么这张图片如此生动形象的:
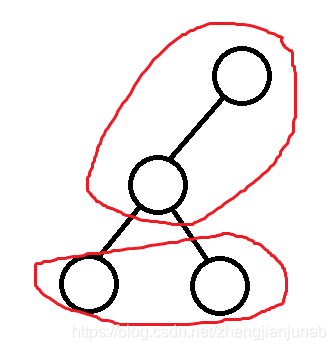
那么块内的节点加上块内所有节点的最近公共祖先(这个祖先不在块内),最多是(S)级别的,因为假设现在栈内有(now+S-1)个点,又来了(S)个点,那么分块便会分出一个(2S-1)个点,乃极限也,加上祖先,就是最多为(2S)个点。
最坏为链状,也就是说一次操作对于(l)的最坏影响也就是移动(S)级别次,且两个临近块之间必有一条边连接两个块,也就是说块之间的移动也是(S)级别的,也就是(mS)级别次。
但是(r)呢?当(l)在一个固定的块时,我们要保证(r)上下跳反复跳完树内所有节点且复杂度尽量小,我们就想到可以用DFS序排序,由于一个子树内的DFS序是一段连续的数列,也就是说查询这串序列的时候只会进入这个点一次,同时在退出这个点的时候不会再进入,每个点进一次出一次,那不就是(n)级别的吗,而且因为块内每个点互相之间只需要(S)次移动就可以到达,所以自然就是(O(frac{n^2}{S})),
当(n=m),总时间复杂度为(O(nS+frac{n^2}{S})),当(S=sqrt{n})时,时间复杂度最小,为(O(nsqrt{n}))。
于是我们就愉快的!!!!!!
AC
WA了QAQ。
哪里出现了问题???
难道博主讲了个假的树上莫队!我还是去看别的博主的吧。
别别别,我们其实可以发现当(l,r)到根节点的两条路径不重合部分其实不包括(lca(l,r)),所以我们需要每次查询结果的时候把(lca)特别的加进去,事后再弄出来。
但是又如何把(l)跳到(l_1)呢?
其实我们只要先让(l)往上跳到(lca(l_1,l)),然后再往下跳到(l_1)就行了。
代码
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<cmath>
#define N 41000
#define NN 81000
#define M 110000
using namespace std;
inline void getz(int &x)
{
x=0;int f=1;char c=getchar();
while(c>'9' || c<'0')c=='-'?f=-1:0,c=getchar();
while(c>='0' && c<='9')x=(x<<3)+(x<<1)+(c^48),c=getchar();
x*=f;
}
struct node
{
int y,next;
}tr[NN];int trlen,last[N];
inline void ins(int x,int y){int now=++trlen;tr[now].y=y;tr[now].next=last[x];last[x]=trlen;}
int st[25][NN],dep[N],in[N]/*这个东西还能代替DFS序呢*/,out[N],zz,lo2[NN],fa[N];//LCA?我采用ST表解决LCA
int n,m;
struct question
{
int l,r,id;
}qu[M];int len;
int a[N],ls[N],what[N],lsc;//离散化
int cnt[N];int ans=0,an[M];
int be[N],block,blen,sta[N],top;
bool turn[N];//目前是否为访问状态
void dfs(int x)
{
st[0][++zz]=x;in[x]=zz;
sta[++top]=x;int now=top;
for(int k=last[x];k;k=tr[k].next)
{
int y=tr[k].y;
if(!dep[y])
{
dep[y]=dep[x]+1;fa[y]=x;
dfs(y);
st[0][++zz]=x;
if(top-now>block)//分块
{
blen++;
while(top!=now)be[sta[top--]]=blen;
}
}
}
out[x]=zz;
}
inline int myminz(int x,int y){return dep[x]<dep[y]?x:y;}
void yuchuli()
{
dep[1]=1;dfs(1);
if(!be[1])//其实这里去掉跟不去掉都没关系,当时脑抽了,现在又强迫症。
{
blen++;
while(top>0)be[sta[top--]]=blen;
}
for(int i=2;i<=zz;i++)lo2[i]=lo2[i>>1]+1;
for(int i=1;i<=lo2[zz];i++)
{
for(int j=zz-(1<<i)+1;j>=1;j--)st[i][j]=myminz(st[i-1][j],st[i-1][j+(1<<(i-1))]);
}
}
inline int lca(int x,int y)
{
int tx=out[x],ty=in[y];
if(tx>ty)tx^=ty^=tx^=ty;
int k=lo2[ty-tx+1];
return myminz(st[k][tx],st[k][ty-(1<<k)+1]);
}
inline bool cmp1(question x,question y){return (be[x.l]==be[y.l])?(in[x.r]<in[y.r]):(be[x.l]<be[y.l]);}
inline bool cmp2(int x,int y){return a[x]<a[y];}
inline void sur(int x,int f){f==0?f=-1:0;cnt[x]+=f;ans+=((cnt[x]==0)!=(cnt[x]-f==0))*f;}//当f=1为添加,当f=0为删除
int main()
{
// freopen("std.in","r",stdin);
// freopen("vio.out","w",stdout);
getz(n);getz(m);block=sqrt(n);
for(int i=1;i<=n;i++)
{
getz(a[i]);
what[i]=i;
}
for(int i=1;i<n;i++)
{
int x,y;getz(x);getz(y);
ins(x,y);ins(y,x);
}
yuchuli();
sort(what+1,what+n+1,cmp2);
a[0]=-999999999;for(int i=1;i<=n;i++)ls[what[i]]=(a[what[i]]==a[what[i-1]])?lsc:++lsc;
for(int i=1;i<=m;i++)
{
len++;
getz(qu[i].l);getz(qu[i].r);
qu[i].id=i;
}
sort(qu+1,qu+m+1,cmp1);
int l=0,r=0;
for(int i=1;i<=m;i++)
{
int ll=qu[i].l,rr=qu[i].r, _lca=dep[lca(l,ll)];
int tt=dep[l]-_lca;
while(tt--)sur(ls[l],turn[l]^=1),l=fa[l];
//往上跳
tt=dep[ll]-_lca;int now=l=ll;
while(tt--)sur(ls[now],turn[now]^=1),now=fa[now];//下跳
//跳l
_lca=dep[lca(r,qu[i].r)];
tt=dep[r]-_lca;
while(tt--)sur(ls[r],turn[r]^=1),r=fa[r];
//上
tt=dep[rr]-_lca;now=r=rr;
while(tt--)sur(ls[now],turn[now]^=1),now=fa[now];//下
//跳r
now=lca(l,r);
sur(ls[lca(l,r)],1);//添加lca
an[qu[i].id]=ans;
sur(ls[lca(l,r)],0);//再次删除lca
//其实可以直接打个going函数把两个弄成一个,因为这两个跳l,r的其实是差不多的。
}
for(int i=1;i<=m;i++)printf("%d
",an[i]);
return 0;
}
小结
小谈另类树上莫队
其实还有一种树上莫队形式,是预处理出一种神仙的序列,然后在这个序列上面跳,这个序列是用DFS一遍树构造的,进去时候放个节点,出来时候放个节点,其实就是欧拉序,然后顺便记录一下(st,ed)(进去的下标,出来的下标),当然序列是(n)级别的个数,应该就是(2n)。
然后分情况考虑(假设(st[x]<st[y]),也就是先到(x)后到(y)):
PS:摘自自为风月马前卒大佬的博客。
分情况讨论
若lca(x,y)=x,这时(x,y)在一条链上,那么(st[x])到(st[y])这段区间中,有的点出现了两次,有的点没有出现过,这些点都是对答案没有贡献的,我们只需要统计出现过11次的点就好
比如当询问为(2,6)时,((st[2],st[6])=2,3,4,4,5,5,6),(4,5)这两个点都出现了两次,因此不统计进入答案
若lca(x,y)≠x,此时(x,y)位于不同的子树内,我们只需要按照上面的方法统计(ed[x]到st[y])这段区间内的点。
比如当询问为(4,7)时,((ed[4],st[7])=4 5 5 6 6 3 7)。大家发现了什么?没错!我们没有统计(lca),因此我们需要特判(lca)
说实话,我还是习惯大米饼写的方法,常数小,代码量也差不多,这种普通莫队的方法只是通过另类的方法解决了一些树上莫队遇到的一些问题。
适用范围
树上莫队适用范围:和普通莫队一样。
回滚莫队
我的妈耶,回滚莫队!怕不是过去再回来的莫队!!!竟然如此的神仙?
例题
这道题目可以在bzoj上双倍经验QMQ

思路点拨
如果是让你知道重要性的总和,你是肯定会做的,甚至可以快速的(A)掉他,但是求最大值就受不了了,但是我们其实可以搞一个可以删除的堆,就是会多个(log),只是谁都不想看到的事情。
但是我们又看到了莫队的时间复杂度(O(nsqrt{n})),也就是说这是个挺松的复杂度,那么我们是否可以相出一种普通莫队的新形式呢?
回滚莫队讲解
我们发现最大值其实只要不要删除就可以了,也就是说(l,r)不会往内移,而不会往外移,于是就神奇起来了。
我们发现了一种方法,设块大小为(S)。
像原来那样排序以后,对于(be_l==be_r)的询问而言,我们可以直接暴力做掉,也就是每次询问的级别为(S)。
不同块呢?我们照样可以做,也就是对于(l,r)指针,我们固定了(l=R_{be_l}),而(r)一开始等于(l-1),然后每次移动(r),根据排序,(r)只会增加(只要你不打奇偶分块QAQ)。(r)移动完后,记录下现在的信息,然后在(l)移动后更新完信息再等于原来只移动(r)的信息。
到了新的块,我们只要对目前的信息memset一下,我们就一下子搞定了这件事情。
(r)只会单调增加,同时对于每个询问,(l)只会移动(S)次。
也就是说(r)为(O(frac{n^2}{S})),(l)为(O(mS))。
当(n=m)时,老套路,(S=sqrt{n})。
当然这套题需要记录的信息不是整个数组,而是一个数字。
而我们的数组信息可以直接顺藤摸瓜删回去。
谁给我加个修改卡掉他(加个修改必然会涉及到删除操作)
代码
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<cmath>
#define N 110000
using namespace std;
typedef long long LL;
struct question
{
LL l,r,id;
}qu[N];
LL be[N],block;
inline bool cmp(question x,question y){return (be[x.l]==be[y.l])?(x.r<y.r):(x.l<y.l);}
LL ans,an[N];
LL a[N],n,m;
LL what[N],ls[N],ys[N],lsc;
LL cnt[N];
inline bool cmp2(LL x,LL y){return a[x]<a[y];}
inline LL mymax(LL x,LL y){return x>y?x:y;}
inline LL mymin(LL x,LL y){return x<y?x:y;}
inline void sur(LL x,LL f){ans=mymax(ans,ys[x]*(cnt[x]+=f));}
int main()
{
scanf("%lld%lld",&n,&m);block=sqrt(n);
for(LL i=1;i<=n;i++){scanf("%lld",&a[i]);be[i]=(i-1)/block+1;what[i]=i;}
sort(what+1,what+n+1,cmp2);
for(LL i=1;i<=n;i++)
{
if(a[what[i]]!=a[what[i-1]])ys[++lsc]=a[what[i]];
ls[what[i]]=lsc;
}
for(LL i=1;i<=m;i++)
{
LL x,y;scanf("%lld%lld",&x,&y);
if(x>y)x^=y^=x^=y;
qu[i].l=x;qu[i].r=y;qu[i].id=i;
}
sort(qu+1,qu+m+1,cmp);
LL l,r,now=1/*解决的是现在到哪里了。*/,ed=be[n];
for(LL i=1;i<=ed;i++)
{
if(now>m)break;
if(be[qu[now].l]>i)i=be[qu[now].l];
while(be[qu[now].r]==i/*两个都是这个块的*/)//之所以没有打now<=m是因为如果超出了会自动退出
{
LL x=qu[now].r;
for(LL j=qu[now].l;j<=x;j++)sur(ls[j],1);
an[qu[now].id]=ans;
for(LL j=qu[now].l;j<=x;j++)sur(ls[j],-1);//利用回溯清除
now++;ans=0;//方便下次
}
if(be[qu[now].l]==i)
{
l=mymin(block*i,n);r=l-1;
while(be[qu[now].l]==i)
{
while(r<qu[now].r)sur(ls[++r],1);
LL old=ans;
while(l>qu[now].l)sur(ls[--l],1);
an[qu[now++].id]=ans;
for(LL j=mymin(block*i,n)-1;j>=l;j--)sur(ls[j],-1);//还是注意这里是要回溯的,我们只保存了ans的信息
ans=old;l=mymin(block*i,n);
}
while(l<=r)sur(ls[l++],-1);ans=0;
}
}
for(LL i=1;i<=m;i++)printf("%lld
",an[i]);
return 0;
}
小结
回滚莫队适用范围:
- 首先必须满足普通莫队的性质。
- 询问不适合维护删除或者添加后的(ans)。
- 记录信息以及集成信息可以在小于(S)的时间内完成,或者在不影响时间复杂度的情况下。(这道题目记录信息(O(1)),同时恢复信息因为要删回去,所以是(O(S))的)
二次离线莫队
记住这个毒瘤的东西,我们以后一定要把这个东西痛殴一万遍。
例题
时间限制
1.00s
内存限制
40.00MB ~ 500.00MB
珂朵莉给了你一个序列a,每次查询给一个区间[l,r]
查询l≤i<j≤r,且ai⊕aj的二进制表示下有k个11的二元组(i,j)的个数。⊕是指按位异或。
输入格式
第一行三个数表示n,m,k
第二行n个数表示序列a
之后m行,每行两个数l,r表示一次查询
输出格式
输出m行,每行一个数表示查询的结果
输入输出样例
输入 #1 复制
5 5 2
3 4 8 0 2
4 5
3 5
1 4
2 5
1 5
输出 #1 复制
0
1
2
3
4
说明/提示
对于5%的数据,为样例
对于30%的数据,1≤n,m≤5000
对于50%的数据,空间限制为512MB
思路点拨
这道题目貌似用莫队的话转移是(O(n))的,那岂不是时间复杂度就到了(O(n^2sqrt{n})),没事,比(O(n^3))还少了不少,这不就是莫队的最大优化空间了?
不不不,你并不能以这么慢的时间复杂度AC这道题目,于是我们需要更快的时间复杂度,难道有更神奇的黑科技吗。
题目是不是写了个二次离线?二次离线,是什么神仙玩意?
离线再离线,怕不是要上天了?
说是点拨,实际吐槽
二次离线莫队讲解
我们发现每次添加一个数字的时候,我们需要对目前里面的所有数字都异或一遍,然后看看符不符合要求。
但是我们调整一种方法,每次询问只是处理出([l,r])转移到([l+k,r+k](k∈Z))(也就是(k)为整数)后变化的值,最后在从前往后加一遍得出答案,也许我们会发现对于普通莫队,这种并不是很需要,但是这是二次离线,我们在第二次离线时算的只是单对于一次询问的贡献。
但是我们又发现我们可以通过类似查分的方式把这个数字对答案的贡献分成两类,假设目前是([l,r])扩展到([l,r+1]),所以就是(r+1)对([1,r])符合要求的对数减去(r+1)对([1,l-1])符合要求的对数。
写成较为书面:
也就是信息支持加减性QAQ。
仔细观察,发现对于任意一个(x),我们都可以预处理出(f(x,[1,x-1]))。(处理方式等会说)。
而(f(r+1,[1,l-1]))则更为复杂,我们总不可能在莫队的时候处理吧。
那我们只能在莫队之后处理了,所以我们对于([l,r])转移到([l,r+k])改变了的答案,我们可以先得出(f(r+1,[1,r]))的贡献值,然后记录([r+1,r+k])对于([1,l-1])的贡献,而这个我们是可以在后面统一处理的,等会说QMQ。
当时莫队有四种移动指针的方式:
(r++:f(r+1,[l,r])=f(r+1,[1,r])-f(r+1,[1,l-1]))
(r--:f(r,[l,r-1])=f(r,[1,r-1])-f(r,[1,l-1]))
(l--:f(l-1,[l,r])=f(l-1,[1,r])-f(l-1,[1,l-1]))
(l++:f(l,[l+1,r])=f(l,[1,r])-f(l,[1,l]))
注意一点,(r--)和(l++)的那个贡献是要减的,因为是删除,以及我们可以发现一点就是为什么有时候是(f(x,[1,x]))有时候(f(x,[1,x-1]))?
TMD的。素质素质。自己又不能对自己有贡献你就不能发现(f(x,[1,x])=f(x,[1,x-1]))。
那么开始讲讲如何处理(f(x,[1,x-1])),我们可以提前预处理出(16383)以内有(k)个(1)的数字,而且当(k>14)时直接输出(0)没因为总的数字最多只能有(14)个(1),其实我们可以发现异或有一条性质:(x⊕y=z)那么(y⊕z=x),所以我们只需要处理出所有的数字,然后对于([1,x-1])的每个数字我们都与处理出来的数字集(⊕)一遍,对(⊕)出来的值在(t)数组中(++),最后取(t[a[x]])即为答案((a[x])表示的是(x)的数字)。
那么预处理的时间复杂度是多少呢,(C_{x}^{y})表示在(x)中选(y)个数字有多少种方案,那么时间复杂度就是(O(nC^{k}_{14}))。
你以为这个时间复杂度很大?当(k=7),(C^{k}_{14})最大,为(3432),(C^{k}_{14}=frac{14!}{(14-k)!k!}),这就是计算公式。好像看了一下确实会T耶QAQ
异或的常数也是十分的小的,所以我们可以认为这个时间复杂度大,但是常数很小。(:雾
而在二次离线处理第二个(f)的贡献的时候,我们又要怎么处理才能使得处理总时间最小呢?
我们也一样可以处理([1,x]),然后用(vector)储存有多少对数字是求对([1,x])的贡献的,然后对这些数字依次循环一遍,然后加一下(t)。(注意:当(k=0)时我们要特判一下如果目前循环的这个数字的下标小于等于(x)的话,我们要减一消去他对于自己的贡献)。
而我们循环的总次数自然就是莫队的移动次数,因为我们证明过莫队的移动次数也是(nsqrt{n})的,所以第二次离线的时间复杂度自然就是(nsqrt{n})了,所以总的时间复杂度就是(O(nsqrt{n}+nC^{k}_{14})),常数也是挺小的呢。
代码
#include<cstdio>
#include<cstring>
#include<cmath>
#include<vector>
#include<algorithm>
#define N 110000
using namespace std;
typedef long long LL;
struct question
{
LL l,r,id;
}qu[N];
struct node
{
LL l,r,f/*f表示编号,同时也表示正负*/;
node(LL ll,LL rr,LL ff){l=ll;r=rr;f=ff;}
};LL ans[N];
vector<node>v[N];
LL cal[21000];//满足条件的数字
LL n,m,k,block,be[N],a[N];
LL t[21000],pr[N]/*pr[i]表示的是i对于1-(i-1)的贡献*/;
inline bool cmp(question x,question y){return be[x.l]==be[y.l]?(x.r<y.r):(x.l<y.l);}
inline LL calc(LL x)//统计有多少个1
{
LL y=1,cnt=0;
while(y<=x)y&x?cnt++:0,y<<=1;
return cnt;
}
int main()
{
scanf("%lld%lld%lld",&n,&m,&k);block=sqrt(n);
if(k>14)
{
for(LL i=1;i<=m;i++)printf("0
");
return 0;
}
for(LL i=1;i<=n;i++)
{
scanf("%lld",&a[i]);
be[i]=(i-1)/block+1;
}
for(LL i=1;i<=m;i++){scanf("%lld%lld",&qu[i].l,&qu[i].r);qu[i].id=i;}
sort(qu+1,qu+m+1,cmp);
for(LL i=0;i<=16383;i++)
{
if(calc(i)==k)cal[++cal[0]]=i;
}//提前预处理出有k个1的数字
for(LL i=1;i<n;i++)
{
for(LL j=1;j<=cal[0];j++)t[a[i]^cal[j]]++;//利用异或的性质
pr[i+1]=t[a[i+1]];
}
LL l=qu[1].l,r=l-1;
for(LL i=1;i<=m;i++)//第一次离线,莫队
{
LL L=qu[i].l,R=qu[i].r,id=qu[i].id;
if(l<L)v[r].push_back(node(l,L-1,-id/*携带编号同时传递正负*/));
while(l<L)ans[id]+=pr[l++];
if(l>L)v[r].push_back(node(L,l-1,id));
while(l>L)ans[id]-=pr[--l];
if(r<R)v[l-1].push_back(node(r+1,R,-id));
while(r<R)ans[id]+=pr[++r];
if(r>R)v[l-1].push_back(node(R+1,r,id));
while(r>R)ans[id]-=pr[r--];
}
memset(t,0,sizeof(t));
for(LL i=1;i<=n;i++)
{
for(LL j=1;j<=cal[0];j++)t[a[i]^cal[j]]++;//当前是[1,i]区间的
LL siz=v[i].size();
for(LL j=0;j<siz;j++)
{
LL l=v[i][j].l,r=v[i][j].r,id=v[i][j].f,f=id>0?1:-1;id*=f;
for(LL x=l;x<=r;x++)
{
LL tmp=t[a[x]];
if(!k && x<=i)tmp--;//这里要特判
ans[id]+=tmp*f/*有正贡献以及负贡献*/;
}
}
}
for(LL i=1;i<=m;i++)ans[qu[i].id]+=ans[qu[i-1].id];//最后统一加一遍
for(LL i=1;i<=m;i++)printf("%lld
",ans[i]);
return 0;
}
优化
我们发现代码里面的莫队部分我们的(l,r)是慢慢移动然后加上(pr)的,但是其实我们是可以做一遍前缀和,省略掉时间的,但是因为时间卡的松,就没有去注意。
小结
这个二次离线莫队我目前没有找到支持修改的方法。。。
适用范围:
- 维护的信息可以进一次差分。
- 差分后的两个信息一个信息可以预处理,另外的一个信息通过第二次在线能够以移动次数级别的时间搞定。
- 还要满足普通莫队的一些性质。
在线莫队
莫队的在线化改造。莫队:我不离线啦,JOJO
例题
Description
墨墨购买了一套N支彩色画笔(其中有些颜色可能相同),摆成一排,你需要回答墨墨的提问。墨墨会像你发布如下指令: 1、 Q L R代表询问你从第L支画笔到第R支画笔中共有几种不同颜色的画笔。 2、 R P Col 把第P支画笔替换为颜色Col。为了满足墨墨的要求,你知道你需要干什么了吗?
Input
第1行两个整数N,M,分别代表初始画笔的数量以及墨墨会做的事情的个数。第2行N个整数,分别代表初始画笔排中第i支画笔的颜色。第3行到第2+M行,每行分别代表墨墨会做的一件事情,格式见题干部分。
Output
对于每一个Query的询问,你需要在对应的行中给出一个数字,代表第L支画笔到第R支画笔中共有几种不同颜色的画笔。
Sample Input
6 5
1 2 3 4 5 5
Q 1 4
Q 2 6
R 1 2
Q 1 4
Q 2 6
Sample Output
4
4
3
4
HINT
对于100%的数据,N≤10000,M≤10000,修改操作不多于1000次,所有的输入数据中出现的所有整数均大于等于1且不超过10^6。
2016.3.2新加数据两组by Nano_Ape
Source
思路点拨
也许我们是时候需要考虑一下如何在线莫队了。
用在做强制在线的题目。
其实这种方法更形象一点的应该叫分块,因为莫队的移动变在线以后不能保证次数在(sqrt{n})级别了。
但是为什么不放在分块呢?
因为大众也比较喜欢叫强制在线莫队。
但是我们要知道这种做法是在分块里面揉上了莫队的思想。
在线改造讲解
我们可以发现莫队,其实主要就是可以在合法时间内转移过来,那么我们是不是只需要设立一些特征点,在合法时间内处理出特征点的信息,然后利用特征点的区间在转移到我们想要的区间。(也就是分块中的中间整块然后处理边角料罢了。)
那么我们首先是设特征点之间的长度为(S),然后我们处理出(1)(也就是第一个特征点)到第(i)个特征点之间的(cnt)数组,那么我们就可以利用类似前缀和的方式得出到底每种颜色有多少个了,同时设(ans[i][j])表示的是第(i)个特征点到第(j)个特征点之间有多少个不同的颜色。
我们对于(l,r)要怎么查询呢?
当(l,r)位于两个同样的特征点之间,直接暴力。
不是,那么我们只要找到左边离(l,r)最近的特征点,然后用(ans)知道了目前的答案,我们现在就可以中规中矩的把两个特征点一起左跳到(l,r),然后再用一个临时数组(CNT)(存的是那些颜色减少了,那些颜色增加了,因为不好在(cnt)中直接改。貌似也可以,改完再改回去就行了。)以及原来就有的(cnt),得出每种颜色是否有改变过。
时间复杂度为:(O(mS+frac{n^2}{S})),当(m=n)时,(S)取(sqrt{n})时最小,为(O(nsqrt{n})),当然那个分数是预处理时间复杂度,那个(mS)自然就是询问复杂度了。
但是我们并不能支持修改?怎么办,我们发现每次修改修改一下(cnt)就行了,但是(ans)我们不能直接改,复杂度会跑满,我们可以等到需要的时候再把(ans)更新到我们目前的时间(这种做法并不会降低时间复杂度,只会降低常数),我们只要用(tim[i][j])表示(i)特征点的信息到(j)特征点的(ans)目前已经更新到的时间,至于更新的方法。
由于我们很难知道以前时间的(cnt),所以我们选择的是用现在的(cnt)以及临时数组(CNT)一步步推回到那个时间段的(cnt),并且在中途不断更新答案。
注意:上面的(CNT)每次用完之后不要(memset),而是用类似回溯的方法删回去清(0)
设(t)为修改次数,由于每次修改只修改(cnt),所以时间复杂度(O(frac{nt}{S})),但是最坏情况下每个(ans)都会更新到(t),所以修改的总时间复杂度是:(O(frac{nt}{S}+frac{n^2t}{S^2}))
当(n=m=t)时,总的时间复杂度为(O(nS+frac{n^3}{S^2})),当(S=n^{frac{2}{3}})时,时间复杂度最小为(O(n^{frac{5}{3}}))
理论上来讲常数会比较多,应该比原来的带修莫队快,但是因为要回溯以及各种杂七杂八的部分,导致代码较长,时间也是差不多的。(可能是我的写法比较丑吧)。
代码
#include<cstdio>
#include<cstring>
#include<cmath>
#define N 10050
#define NN 20100//颜色在离散化之后有可能是n+m
#define SN 80
using namespace std;
struct change
{
int x,las,pos;
}chan[N];int clen,tim[SN][SN];
int cnt[SN][NN],CNT[NN],ans[SN][SN];
int block,be[N],seg[SN],blen;
int mp[1100000],a[N],tot,n,m;
inline int getnum(int l,int r,int x){return cnt[r][x]-cnt[l][x]+(a[seg[l]]==x);}
int main()
{
scanf("%d%d",&n,&m);block=pow(n,2.0/3);
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);
if(!mp[a[i]])mp[a[i]]=++tot;
a[i]=mp[a[i]];
}
seg[blen=1]=1;
for(int i=1;i<=n;i++)
{
if(i-seg[blen]==block)seg[++blen]=i;
be[i]=blen;
}
for(int i=1;i<=n;i++)
{
CNT[a[i]]++;
if(i==seg[be[i]])
{
int x=be[i];
for(int j=1;j<=tot;j++)cnt[x][j]=CNT[j];
}
}
for(int i=1;i<=blen;i++)
{
memset(CNT+1,0,tot<<2);
int tmp=i+1,zans=0;
for(int j=seg[i];j<=n;j++)
{
CNT[a[j]]++;if(CNT[a[j]]==1)zans++;
if(j==seg[tmp])ans[i][tmp]=zans,tmp++;
}
}
memset(CNT+1,0,tot<<2);
//长长的预处理。
while(m--)
{
int l,r;char st[20];scanf("%s%d%d",st,&l,&r);
if(st[0]=='R')
{
chan[++clen].x=l;
if(!mp[r])mp[r]=++tot;
chan[clen].pos=r=mp[r];//离散化一下
for(int i=be[l]+!(l==seg[be[l]]);i<=blen;i++)cnt[i][a[l]]--,cnt[i][r]++;
chan[clen].las=a[l];a[l]=r;
}
else
{
int tx=be[l],ty=be[r];
if(tx==ty)//在这里为什么没有尝试去用while呢?因为这样子的话还要去管这个区间内的修改,也就只有四行代码,但是能省一点点时间,而且还不用考虑这么多,此乐何极。
{
int zans=0;
for(int i=l;i<=r;i++)if(++CNT[a[i]]==1)zans++;
printf("%d
",zans);
for(int i=l;i<=r;i++)--CNT[a[i]];
}
else
{
if(tim[tx][ty]!=clen)
{
for(int i=clen;i>tim[tx][ty];i--)
{
if(chan[i].x>=seg[tx] && chan[i].x<=seg[ty])ans[tx][ty]-=(++CNT[chan[i].las]+getnum(tx,ty,chan[i].las)==1),ans[tx][ty]+=(--CNT[chan[i].pos]+getnum(tx,ty,chan[i].pos)==0);
}
for(int i=clen;i>tim[tx][ty];i--)if(chan[i].x>=seg[tx] && chan[i].x<=seg[ty])--CNT[chan[i].las],++CNT[chan[i].pos];//清空临时数组
tim[tx][ty]=clen;
}
int zans=ans[tx][ty],x=seg[tx],y=seg[ty];
//之前我这里写成了zans-=(--CNT[a[x++]]+getnum(tx,ty,a[x-1/*前面x++了*/])==0);本地没有问题,但是不同的机子可能就不同,所以不要合起来写。
while(x<l)--CNT[a[x++]],zans-=(CNT[a[x-1]]+getnum(tx,ty,a[x-1])==0);
while(y<r)++CNT[a[++y]],zans+=(CNT[a[y]]+getnum(tx,ty,a[y])==1);
printf("%d
",zans);
x=seg[tx];y=seg[ty];
while(x<l)++CNT[a[x++]];
while(y<r)--CNT[a[++y]];
}
}
}
return 0;
}
小结
如果不带修改的话,我们强制在线复杂度不变,但是我们的空间相对于普通莫队多了一个(sqrt{n})级别,如果支持修改,在复杂度不变的情况下,我们的在线莫队会多(n^{frac{1}{3}})的空间。
适用范围:
- 空间适合。(你谷的数颜色就是范围大,导致MLE过不去,才选择了bzoj的题目)
- 支持前缀和或者另外一些维护区间的方法,以及维护信息支持加减性质。
- 满足普通莫队的性质。
再度深入探究
但是如果不满足第二条的话其实也有一种方法,就是直接储存特征点之间的信息,空间复杂度:(O(n^{frac{5}{3}})),同时也只有在问道的时候更新(cnt),且我们发现不同块的话,如果不能用(CNT)在莫队部分维护额外信息得出答案的话,那么其实我们可以直接在(cnt)上面改,只要改完可以再改回去就行了(改不回去的话说明不支持普通莫队的性质)。
当然还是要谈谈改不会去这个坑的,如果说题目不能支持删除,那么如果信息可以在短时间内完成记录与继承的话,我们可以把像回滚莫队的手段,将(l)等于右边离他最近的特征点,然后先记录目前的(cnt),更新完之后再继承回去,如果记录与继承时间复杂度大的话你用莫队干嘛,TMD。。。就这样貌似任意一个莫队都做不了这种事情吧!(不排除博主菜)
而且这样子的话时间复杂度不会变动,但是貌似就真的尝出了分块的味道。。。
优化
谁说莫队不能优化,我大莫队党也有卡常技巧!
奇偶分块
其实某些代码里面也许你已经发现了排序中有个&(1)
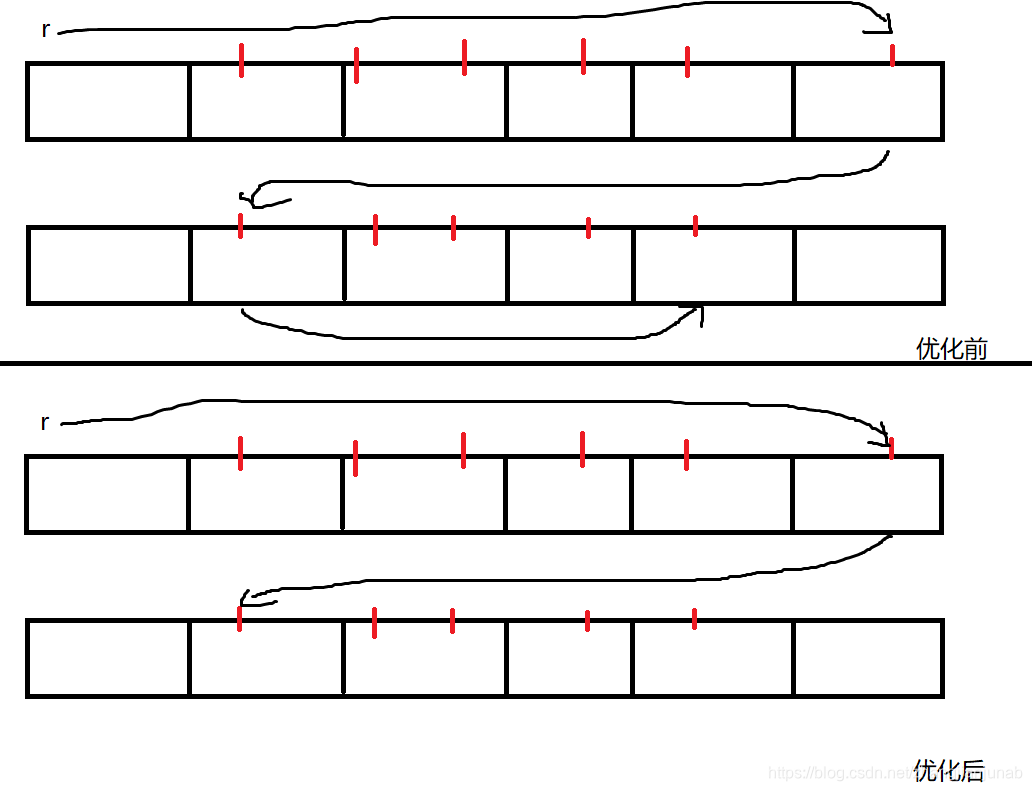
我们其实可以发现每次(l)到了一个新的块,我们的(r)都要跑回去,这时候也许你会说,那对于每个新的(l)块,我们都让(r=l-1),然后(memset)重新开始,memset那你还不如跑回来我们还有个更好的方法,(l)所在块为奇数(r)从小到大排,为偶数从大到小排,让(r)从大回到小的过程尽量不浪费。
(但是如果有一个块没有(l)你也当有了?对,我们就当有了,好吧好偷懒,如果我们花时间去管这些,没准更慢了就是偷懒,一遍O(n)就可以处理的事情,当然如果你想的话你可以再开个数组表示有(l)存在的块从小到大排一遍,再给个新编号,进一步优化,但是优化空间已经很小,代码量也有好几行,一般不回去打的。)
其中第一个矩阵表示(l)在第一个块,第二个矩阵表示(l)在第二个块。
代码:
inline bool cmp(question x,question y){return be[x.l]==be[y.l]?(x.r<y.r):(x.l<y.l);}//原来
inline bool cmp(question x,question y){return be[x.l]==be[y.l]?((be[x.l]&1)?x.r<y.r:x.r>y.r):(x.l<y.l);}//现在
树上莫队的DFS序也可以这么干,而且更厉害的是带修莫队的(r)与(tim)也都可以这么干((r)优化是按块从大到小排)。回滚莫队的那位你还是算了吧。
开头直接跳到指定位置
我们一开始的(l,r)可以让他们直接跳到我们想要的位置,如普通莫队中的:(l=qu[1].l,r=l-1)和树上莫队的(l=qu[1].l,r=l),但是带修中的(tim)不要这么干。
空间优化!分组查询
例题
时间限制
4.00s
内存限制
500.00MB
背景:
galgame情节。
题目描述
您正在打galgame,然后突然发现您今天太颓了,于是想写个数据结构题练练手: 一个长为 n 的序列 a。
有 m 个询问,每次询问三个区间,把三个区间中同时出现的数一个一个删掉,问最后三个区间剩下的数的个数和,询问独立。 注意这里删掉指的是一个一个删,不是把等于这个值的数直接删完,比如三个区间是 [1,2,2,3,3,3,3] , [1,2,2,3,3,3,3] 与 [1,1,2,3,3],就一起扔掉了 1 个 1,1 个 2,2 个 3。
输入格式
第一行两个数表示 n , m。
第二行 n个数表示 a[i]。
之后 m 行,每行 6 个数 l1 , r1 , l2, r2 , l3 , r3 表示这三个区间。
输出格式
对于每个询问,输出一个数表示答案。
输入输出样例
输入 #1 复制
5 2
1 2 2 3 3
1 2 2 3 3 4
1 5 1 5 1 5
输出 #1 复制
3
0
说明/提示
Idea:nzhtl1477,Solution:nzhtl1477,Code:nzhtl1477,Data:nzhtl1477
n , m <= 100000 , 1 <= a[i] <= 1000000000
思路点拨
没想到吧,这个优化有例题,到底是什么毒瘤优化?还有例题的?
讲解
这道题目我们首先要考虑如何AC,知道思路之后我们才能对其进行优化。
这道题目许多人一看就知道可能需要加个(bitset),其实可就是这样,但是要怎么套(bitset)呢。
我们可以把询问拆一下:(f([l1,r1],[l2,r2],[l3,r3])=(r3-l3+r2-l2+r1-l1+3)-)三个区间共同的数字个数*3。
也就是说我们需要处理出三个区间内共同的数字。
如果没有重复的数字的话我们可以考虑用莫队处理出三个(bitset),然后就是(bitset)&后的(1)个数,说起来容易,分析一下时间复杂度:(m)个询问,离散化后(bitset)大小为(n/32),所以每个询问&两次就是(nm/16),但是算到极限发现是(6)亿,我们还有一个O2吗,常数小肯定是过的了的,而莫队的时间复杂度还是(O(nsqrt{n})),还是很小的。
但是关键是可以有重复的数字啊,所以我们要想个办法,使得(bitset)可以判断多个重复的数字。
其实我们可以在离散化的时候每个数字的离散值设为小于等于这个数字的数字有多少个,记为(ls_i),然后在莫队我们用(cnt)表示每个数字的出现次数,记为(cnt_i)(表示离散值为(i))的数字出现了多少个,然后假设离散值为(i)的数字被发现了(cnt_i)次,那么只需要在(bitset)里面让下标为(i-cnt_i)的位置设为(1)(没有(+1)是因为(bitset)x下标从(0)开始)。
刚好就可以使得所有数字都被找到的情况下,(bitset)为(1)的个数为(1),同时两个(bitset)&完之后自动把多出的颜色个数给去掉。
其实学过后缀数组的就知道,这个过程很像那个桶排序设置(cnt)数组然后不断(--)插数的过程。
于是我们就愉快的处理掉了同样的数的情况。
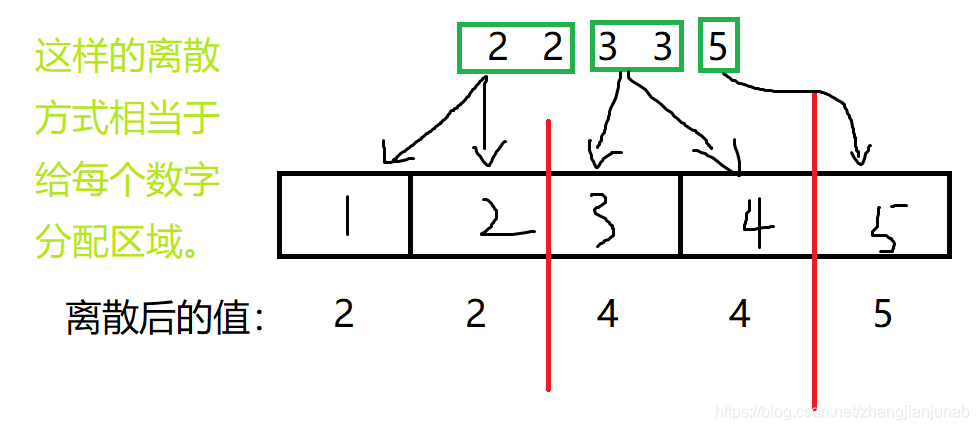
于是我们愉快的打了(bitset<100005> an[100005];)并且交了上去。
看了了一个暗灰的(MLE)。╰_╯博主你是不是又教了我们个假的思路!!!
不不不。你看看内存,才(500MB),怎么能任由你挥霍呢?谁叫你不看完博客。
于是我们打开了(calc),在里面敲了起来(bitset)里面八个位置才算一个字节,于是我们快速敲了起来:(500/(100000/8/1024/1024)=41943.04),只能开着呢大的(bitset)!那么我们该怎么办?
一个很好的方法就是分组询问,我们可以设一个(chuli),然后每次莫队完之后就与(an)&一下(预处理的时候要对所以的(an)用一下(set())或者在后面我们对第一个(bitset)直接处理),然后(an)总共设了(34000),我们对于(100000)个询问从前往后分别跑三次莫队,这样子的话会增大莫队的常数(那一坨(bitset)&的常数还是没有变化的,只是莫队被反复调用罢了)。
也就是说我们可以利用分组询问缩小我们一些需要记录下来的信息,只不过可能需要牺牲常数(分的组数越多常数越大)。
代码
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<cmath>
#include<bitset>
#define N 100010
#define NN 210000
#define FEN 34000//分组查询组数
#define FF 34010
#define KUAI 410
using namespace std;
inline void getz(int &x)
{
x=0;char c=getchar();
while(c>'9' || c<'0')c=getchar();
while('0'<=c && c<='9')x=(x<<3)+(x<<1)+(c^48),c=getchar();
}
bitset<N> ans[FF];
bitset<N> chuli;
int cnt[N],an[FF];
int be[N],blo;
struct question
{
int x,y,id;
}qu[NN]/*34000*3>100010*/;int qlen;
inline bool cmp1(question x,question y){return be[x.x]==be[y.x]?(be[x.x]&1?x.y<y.y:x.y>y.y):x.x<y.x;}//奇偶分块
int n,m,a[N],ls[N],what[N];
bool used[FF];//每个询问是否有被&过
inline bool cmp2(int x,int y){return a[x]<a[y];}
inline int mymin(int x,int y){return x<y?x:y;}
inline void add(int x){cnt[x]++;chuli[x-cnt[x]/*x-cnt[x]+1-1*/]=1;}
inline void del(int x){chuli[x-cnt[x]/*x-cnt[x]+1-1*/]=0;cnt[x]--;}
int main()
{
getz(n);getz(m);blo=sqrt(n);
for(int i=1;i<=n;i++){getz(a[i]);what[i]=i;be[i]=(i-1)/blo+1;}
sort(what+1,what+n+1,cmp2);
a[0]=a[what[1]]-1;int now=1;
for(int i=1;i<=n;i++)
{
if(a[what[i]]!=a[what[i-1]])
{
for(int j=now;j<i;j++)ls[what[j]]=i-1;
now=i;
}
}
for(int i=now;i<=n;i++)ls[what[i]]=n;//神奇的离散法则
int ed;
while(m)//分组查询,这里最多为三组
{
qlen=0;ed=mymin(FEN,m);m-=ed;
for(int i=1;i<=ed;i++)
{
an[i]=0;int x,y;
for(int j=1;j<=3;j++)
{
getz(x);getz(y);x>y?x^=y^=x^=y:0;
qu[++qlen].x=x;qu[qlen].y=y;qu[qlen].id=i;
an[i]+=y-x+1;
}
used[i]=false;
}//前面的预处理
sort(qu+1,qu+qlen+1,cmp1);
chuli.reset();memset(cnt,0,sizeof(cnt));
int l=qu[1].x,r=l-1;
for(int i=1;i<=qlen;i++)
{
while(r<qu[i].y)add(ls[++r]);
while(l>qu[i].x)add(ls[--l]);
while(r>qu[i].y)del(ls[r--]);
while(l<qu[i].x)del(ls[l++]);
if(!used[qu[i].id])ans[qu[i].id]=chuli,used[qu[i].id]=true;
else ans[qu[i].id]&=chuli;
}
for(int i=1;i<=ed;i++)printf("%d
",an[i]-ans[i].count()*3);
}
return 0;
}
注意事项
(一下内容不包括树上莫队)对于这里面大部分代码的(l,r)指针的移动是错误的,我们应该先处理(l--,r++),然后再处理(l++,r--),不然会很容易导致(r<l),然后导致维护的是([r,l-1])的信息,有些信息会直接出错,比如(=)的信息,但是异或的信息大多不会出锅,因为先异或后异或是差不多的,而在二次离线里面,我们更是无法想象维护信息的错误会带来哪些毁灭性的打击(数据水我没有意见)。
进阶:各种组合
树上带修莫队其实也很简单,判断点是否走过用(used)就行了,后面也有题目。
树上二次离线莫队:树上莫队的贡献将以链的形式呈现,所以我们的二次离线需要用DFS实现,应该是可以的,只不过不是(l,r),大部分应该是(l,lca(l,r))的组合,但是我们还有(used)需要处理,我的(idea)是根据(used)分段处理,可以发现分的段数是常数级别的(发现(l)或者(r)移动的时候最多分成(4)段),第二种写法的话我们也是可以直接二次离线的,只是细节要注意,所以这种题一般写第二种吧。过于毒瘤。
树上在线莫队:这个我貌似真不知道怎么改。
练习
树上带修莫队
题面
题面还是算了,自己看吧
思路
这种东西一看就知道树上带修,还能干吗。。。
代码
//重新整理一遍,对于每个点,他的义务就是把所有子树分块了,然后参与到父亲的分块中
//树形带修莫队感觉一直都是
#include<cstdio>
#include<cstring>
#include<cmath>
#include<algorithm>
#define N 110000
#define NN 210000
#define KUAI 410
#define LO 20
using namespace std;
typedef long long LL;
struct node
{
int y,next;
}bi[NN];int blen,last[N];
inline void ins(int x,int y){blen++;bi[blen].y=y;bi[blen].next=last[x];last[x]=blen;}
//边目录
int st[NN][LO],lo2[NN],in[N],out[N],dep[N],fa[N],tot;//ST表专用
inline int dmin(int x,int y){return dep[x]<dep[y]?x:y;}//ST表专用
int be[N],blo,siz/*块的个数,别问我为什么是siz,因为习惯了*/,sta[N],top/*树上莫队要分块*/;//玄学分块大法
void dfs(int x)
{
st[in[x]=++tot][0]=x;sta[++top]=x;int now=top;
for(int k=last[x];k;k=bi[k].next)
{
int y=bi[k].y;
if(!dep[y])
{
dep[y]=dep[x]+1;fa[y]=x;
dfs(y);
st[++tot][0]=x;
if(top-now>=blo)
{
++siz;while(top>now)be[sta[top--]]=siz;
}//成功分块
}
}
out[x]=tot;
}
void pre_do()//分块与ST表LCA预处理
{
dep[1]=1;dfs(1);
++siz;while(top)be[sta[top--]]=siz;//此时此刻,所有分块完毕
for(int i=2;i<=tot;i++)lo2[i]=lo2[i>>1]+1;
for(int i=1;i<=lo2[tot];i++)
{
for(int j=tot-(i<<1)+1;j>=1;j--)st[j][i]=dmin(st[j][i-1],st[j+(1<<(i-1))][i-1]);
}//ST表处理完毕
}
inline int lca(int x,int y)
{
int tx=out[x],ty=in[y];tx>ty?tx^=ty^=tx^=ty:0;
int k=lo2[ty-tx+1];
return dmin(st[tx][k],st[ty-(1<<k)+1][k]);
}
struct question
{
int x,y,tim,id;
}qu[N];int qlen;
inline bool cmp(question x,question y){return be[x.x]==be[y.x]?(be[x.y]==be[y.y]?x.tim<y.tim:in[x.y]<in[y.y]/*DFS序*/):(be[x.x]<be[y.x]);}
LL an[N];//答案
//问题
struct change
{
int x,old,now;
}ch[N];int clen;
//修改
LL vv[N],ww[N];
int n,m,q,a[N];//点,边,询问,颜色
//统计答案
LL ans=0/*用于存入答案。*/,cnt[N]/*每个颜色的品尝次数*/;
bool used[N];//是否走过
inline void sur(int x,int f){cnt[x]+=(f==0?f=-1:1);ans+=vv[x]*(ww[cnt[x]]-ww[cnt[x]-f]);}//f=1为添加,0为删除
inline void going(int &x,int y)//由x跑向y
{
int dlca/*变量名前有个斜杠*/=dep[x]-dep[lca(x,y)];
while(dlca>0)sur(a[x],used[x]^=1),x=fa[x],dlca--;
dlca=dep[y]-dep[x];x=y;
while(dlca>0)sur(a[y],used[y]^=1),y=fa[y],dlca--;
}
int main()
{
scanf("%d%d%d",&n,&m,&q);blo=pow(n,2.0/3);
for(int i=1;i<=m;i++)scanf("%lld",&vv[i]);
for(int i=1;i<=n;i++){scanf("%lld",&ww[i]);ww[i]+=ww[i-1];}
for(int i=1;i<n;i++)
{
int x,y;scanf("%d%d",&x,&y);
ins(x,y);ins(y,x);
}
pre_do();
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
for(int i=1;i<=q;i++)
{
int ty,x,y;scanf("%d%d%d",&ty,&x,&y);
if(!ty)ch[++clen].x=x,ch[clen].old=a[x],ch[clen].now=a[x]=y;
else qu[++qlen].x=x,qu[qlen].y=y,qu[qlen].tim=clen,qu[qlen].id=qlen;
}
sort(qu+1,qu+qlen+1,cmp);//直接排序处理好
int l=qu[1].x,r=l,tim=clen;
for(int i=1;i<=qlen;i++)
{
//十分注意,判断一个点是否在路径上不需要疯狂lca,你只需要一个used
while(qu[i].tim>tim)
{
tim++;
if(used[ch[tim].x])sur(ch[tim].old,0),sur(ch[tim].now,1);
a[ch[tim].x]=ch[tim].now;
}
while(qu[i].tim<tim)
{
if(used[ch[tim].x])sur(ch[tim].now,0),sur(ch[tim].old,1);
a[ch[tim].x]=ch[tim].old;tim--;
}
going(l,qu[i].x);going(r,qu[i].y);
int _lca=lca(l,r);
sur(a[_lca],1);
an[qu[i].id]=ans;
sur(a[_lca],0);
}
for(int i=1;i<=qlen;i++)printf("%lld
",an[i]);
return 0;
}
是真的裸,应该是个紫题吧。
Ynoi大毒瘤题
题面
给你一个长为n的序列a,m次询问,每次查询一个区间的逆序对数
输入格式
第一行两个数n,m
第二行n个数表示这个序列
之后m行,每行两个数表示查询的区间
输出格式
输出m行,每行一个数表示这次询问的答案
输入输出样例
输入 #1 复制
4 1
1 4 2 3
2 4
输出 #1 复制
2
说明/提示
n,m <= 100000,0 <= ai <= 1000000000
我们已经有了低于n^1.5的算法
Source By nzhtl1477
不要痴迷在CDQ啦,醒醒,这是莫队!!!
思路
这道题目我们又发现转移是(O(n))的,怎么办?二次离线!!!
我们继续用(f(x,[l,r]))表示的是(x)对于区间([l,r])能做出的逆序对数。
当然逆序对数还是要注意一件事情,就是位置的不同,求的也就不同,有时候是求区间中有多少个大于的,有时候又是小于,要注意一下。
代码
#include<cstdio>
#include<cstring>
#include<cmath>
#include<algorithm>
#include<vector>
#define N 110000
#define KUAI 410
using namespace std;
typedef long long LL;
inline int mymin(int x,int y){return x<y?x:y;}
inline int mymax(int x,int y){return x>y?x:y;}
int be[N],block;
struct node
{
int x,l,r;
node(int xx,int ll,int rr){x=xx;l=ll;r=rr;}
};
/*
这里讲讲权值分块的方法。
这里的方法是O(sqrtn)的修改,O(1)的查询
sum[i]表示的是第1到i块的数字有多少个。
fen[i]表示的是在i所在的块内,块头到i已经有多少个数字。
这里指的有多少个数字指的是被添加的数字,可重复添加统一数字。
修改很简单
*/
int fen[N],blo,sum[KUAI];//权值分块
int n,m,a[N],what[N],ls[N],tot;
inline void ins(int x,int f)//传说中的修改
{
int tx=(x-1)/blo+1;
for(int i=(tot-1)/blo+1;i>=tx;i--)sum[i]+=f;
for(int i=mymin(tx*blo,tot);i>=x;i--)fen[i]+=f;
}
inline int getsum1(int x)/*求比他小的数字*/{return sum[(x-1)/blo]+fen[x-1]*(x%blo!=1);}//别忘记特判x为块的边界的情况
inline int getsum2(int x){return sum[(tot-1)/blo+1]-sum[(x-1)/blo]-fen[x];}//求比他大的数字
//9行的树状数组,你值得拥有
int bst[N];
inline int lowbit(int x){return x&-x;}
inline void change(int x,int f){while(x<=tot)bst[x]+=f,x+=lowbit(x);}
inline int findans(int x)
{
int ans=0;
while(x)ans+=bst[x],x-=lowbit(x);
return ans;
}
vector<node> move[N];
struct question
{
int l,r,id;
}qu[N];
inline bool cmp(question x,question y){return (be[x.l]==be[y.l])?(x.r<y.r):(x.l<y.l);}
LL an[N];int sum1[N]/*1-l比l小的数字*/,sum2[N]/*1-l比l大的数字*/;
inline bool cmp2(int x,int y){return a[x]<a[y];}
int main()
{
scanf("%d%d",&n,&m);block=sqrt(n);
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);what[i]=i;
be[i]=(i-1)/block+1;
}
sort(what+1,what+n+1,cmp2);
for(int i=1;i<=n;i++)
{
if(a[what[i]]!=a[what[i-1]])tot++;
ls[what[i]]=tot;
}
blo=sqrt(tot);
//预处理
for(int i=2/*默认第一个数字的逆序对数为0*/;i<=n;i++)
{
change(ls[i-1],1);
sum1[i]=findans(ls[i]-1);//小于的数字
sum2[i]=i-findans(ls[i])-1;//大于的数字
}
for(int i=2;i<=n;i++)change(ls[i-1],-1);
for(int i=1;i<=m;i++)
{
scanf("%d%d",&qu[i].l,&qu[i].r);qu[i].id=i;
if(qu[i].l>qu[i].r)qu[i].l^=qu[i].r^=qu[i].l^=qu[i].r;
}
sort(qu+1,qu+m+1,cmp);
int l=qu[1].l,r=l-1;
for(int i=1;i<=m;i++)//其实这里有个可以优化的地方,就是可以把sum加起来,也就是前缀和的前缀和,这样做可以快速得到几个前缀和的和,但是我已经A了QMQ
{
//其实这里也存在错误,就是l--,r++应该比r--更快的移动,但是已经A了QMQ。
int L=qu[i].l,R=qu[i].r,id=qu[i].id;
if(R<r)move[l-1].push_back(node(id,R+1,r));
while(R<r)an[id]-=sum2[r--];
if(r<R)move[l-1].push_back(node(-id,r+1,R));
while(r<R)an[id]+=sum2[++r];
if(L<l)move[r].push_back(node(id,L,l-1));
while(L<l)an[id]-=sum1[--l];
if(l<L)move[r].push_back(node(-id,l,L-1));
while(l<L)an[id]+=sum1[l++];
}
//v[0]自动忽略贡献
for(int i=1;i<=n;i++)//注意,因为这里只有n次插入,但是有nsqrtn的查询,所以要使用权值分块中sqrt(n)插入的做法。
{
ins(ls[i],1);
int siz=move[i].size();
for(int j=0;j<siz;j++)
{
l=move[i][j].l,r=move[i][j].r;int id=move[i][j].x,f=id>0?1:-1;id*=f;
if(r<i)//求的是1-i区间内比[l,r]小的数字
{
for(int j=l;j<=r;j++)an[id]+=getsum1(ls[j])*f;
}
else//求的是1-i区间内比[l,r]大的数字,没有等于i的情况
{
for(int j=l;j<=r;j++)an[id]+=getsum2(ls[j])*f;
}
}
}
for(int i=1;i<=m;i++)an[qu[i].id]+=an[qu[i-1].id];//加起来
for(int i=1;i<=m;i++)printf("%lld
",an[i]);
return 0;
}
又是树上带修莫队
题面
Description
Haruna每天都会给提督做早餐! 这天她发现早饭的食材被调皮的 Shimakaze放到了一棵
树上,每个结点都有一样食材,Shimakaze要考验一下她。
每个食材都有一个美味度,Shimakaze会进行两种操作:
1、修改某个结点的食材的美味度。
2、对于某条链,询问这条链的美味度集合中,最小的未出现的自然数是多少。即mex值。
请你帮帮Haruna吧。
Input
第一行包括两个整数n,m,代表树上的结点数(标号为1~n)和操作数。
第二行包括n个整数a1...an,代表每个结点的食材初始的美味度。
接下来n-1行,每行包括两个整数u,v,代表树上的一条边。
接下来m 行,每行包括三个整数
0 u x 代表将结点u的食材的美味度修改为 x。
1 u v 代表询问以u,v 为端点的链的mex值。
Output
对于每次询问,输出该链的mex值。
Sample Input
10 10
1 0 1 0 2 4 4 0 1 0
1 2
2 3
2 4
2 5
1 6
6 7
2 8
3 9
9 10
0 7 14
1 6 6
0 4 9
1 2 2
1 1 8
1 8 3
0 10 9
1 3 5
0 10 0
0 7 7
Sample Output
0
1
2
2
3
HINT
1<=n<=5*10^4
1<=m<=5*10^4
0<=ai<=10^9
思路
我们需要思考的是如何处理出最小的没有被添加的数字,我们其实可以把所有数字离散化,不过离散化的话如果排序后相邻两个数字的差的绝对值大于(1)的话,那么后面也都不用了,设为(-1),只要前面的数字真正有离散值,后面的数字遇到不添加就是了。
讲讲我的思路:每次找到一个数字,可以添加就添加到树状数组里面去,然后在查询的时候利用在树状数组跳倍增的思路(log)快速找到第一个没有被添加的数字。(其实我现在才发现貌似树状数组加倍增可以像线段树一样跳区间呢。)
更快的思路:我们其实可以发现查询(n)次,然后插入(nsqrt{n})次,所以我们其实可以用权值分块代替树状数组,而且复杂度小个(log),果然暴力数据结构有时候也是好的QAQ。
代码
#include<cstdio>
#include<cstring>
#include<cmath>
#include<algorithm>
#include<queue>
#define N 51000
#define NN 110000
using namespace std;
//边目录
struct bian
{
int y,next;
}tr[NN];int trlen,last[N];
inline void ins(int x,int y){int now=++trlen;tr[now].y=y;tr[now].next=last[x];last[x]=now;}
//ST表
int st[30][NN],in[N],out[N],dep[N],fa[N],lo2[NN],zz;
//分块
int block,blen,be[N],sta[N],top;
//遍历
void dfs(int x)
{
st[0][++zz]=x;in[x]=zz;
sta[++top]=x;int now=top;
for(int k=last[x];k;k=tr[k].next)
{
int y=tr[k].y;
if(!dep[y])
{
dep[y]=dep[x]+1;fa[y]=x;
dfs(y);
st[0][++zz]=x;
if(top-now>=block)//细节
{
++blen;
while(top!=now)be[sta[top--]]=blen;
}
}
}
out[x]=zz;
}
inline int myminz(int x,int y){return dep[x]<dep[y]?x:y;}
inline int lca(int x,int y)
{
int tx=out[x],ty=in[y];
if(tx>ty)tx^=ty^=tx^=ty;
int k=lo2[ty-tx+1];
return myminz(st[k][tx],st[k][ty-(1<<k)+1]);
}
void chuli()
{
dep[1]=1;dfs(1);
if(!be[1])
{
++blen;
while(top>1)be[sta[top--]]=blen;
}
for(int i=2;i<=zz;i++)lo2[i]=lo2[i>>1]+1;
for(int i=1;i<=lo2[zz];i++)
{
for(int j=zz-(1<<i)+1;j>=1;j--)st[i][j]=myminz(st[i-1][j],st[i-1][j+(1<<(i-1))]);
}
}
//修改与问题
struct change
{
int x,old,now;
}ch[N];int tim;
struct question
{
int l,r,id,tim;
}qu[N];int qlen;
inline bool cmp(question x,question y){return (be[x.l]==be[y.l])?(be[x.r]==be[y.r]?(x.tim<y.tim):in[x.r]<in[y.r]):(be[x.l]<be[y.l]);}
//统计答案区
int bst[NN],blim,cnt[NN];//通过树状数组知道哪个数字是未出现的最小的自然数。
inline int lowbit(int x){return x&-x;}
inline void change(int x,int y)
{
while(x<=blim)
{
bst[x]+=y;
x+=lowbit(x);
}
}
inline int findans()//找到最小的自然数
{
int x=1;
bool bk=1;//可以继续
while(x+lowbit(x)-1<=blim)
{
if(bst[x]<lowbit(x)){bk=false;break;}
x+=lowbit(x);
}
if(bst[x]<lowbit(x))bk=0;
if(bk)
{
int y=lowbit(x);
while(x<blim)
{
while(x+y>blim)y>>=1;
x+=y;
if(bst[x]<lowbit(x))break;
}
}
int l=x-lowbit(x)+1,r=x;
while(l!=r)
{
int mid=(l+r)/2;
if(bst[mid]<lowbit(mid))r=mid;
else l=mid+1;
}
return l;
}
int an[N];bool turn[N];//是否走过。
inline void sur(int x,int f)
{
f==0?f=-1:0;
if(x)
{
cnt[x]+=f;
if((cnt[x]==0)!=(cnt[x]-f==0))change(x,f);
}
}
//普通+离散化
int n,m,a[NN],ls[NN],what[NN],ys[NN],lsc;
inline bool cmp2(int x,int y){return a[x]<a[y];}
inline void going(int &x,int y)//由x跳到y
{
int dlca=dep[lca(x,y)];
int tt=dep[x]-dlca;
while(tt--)sur(ls[x],turn[x]^=1),x=fa[x];
tt=dep[y]-dlca;x=y;
while(tt--)sur(ls[y],turn[y]^=1),y=fa[y];
}
//O(log)
int main()
{
scanf("%d%d",&n,&m);block=pow(n,0.4);
for(int i=1;i<=n;i++){scanf("%d",&a[i]);what[i]=i;}
for(int i=1;i<n;i++)
{
int x,y;scanf("%d%d",&x,&y);
ins(x,y);ins(y,x);
}
chuli();
for(int i=1;i<=m;i++)
{
int x,y,z;scanf("%d%d%d",&x,&y,&z);
if(x==0)tim++,ch[tim].x=y,a[n+tim]=z,what[n+tim]=n+tim;
else
{
qlen++;
qu[qlen].l=y;qu[qlen].r=z;qu[qlen].tim=tim;qu[qlen].id=qlen;
}
}
int nt=n+tim;
sort(what+1,what+nt+1,cmp2);
lsc=1;/*使得0也被加进来*/
for(int i=1;i<=nt;i++)
{
int x=a[what[i]],y=a[what[i-1]];
if(x==y)ls[what[i]]=lsc;
else if(x==y+1)ls[what[i]]=++lsc,ys[lsc]=x;
else {ys[++lsc]=y+1;break;}//确定
}
for(int i=1;i<=tim;i++)ch[i].old=ls[ch[i].x],ch[i].now=ls[ch[i].x]=ls[n+i];//加上修改的离散化
ys[blim=++lsc]=ys[lsc-1]+1;//代表最大的限制
//这里为什么要+1,因为有可能所有的数字都是连续的,所以没有空余的,而且这并不会影响其他情况的结果
sort(qu+1,qu+qlen+1,cmp);
int l=0,r=0,ti=tim;
for(int i=1;i<=m;i++)
{
while(ti>qu[i].tim)
{
if(turn[ch[ti].x])sur(ch[ti].now,0),sur(ch[ti].old,1);
ls[ch[ti].x]=ch[ti].old;ti--;
}
while(ti<qu[i].tim)
{
ti++;ls[ch[ti].x]=ch[ti].now;
if(turn[ch[ti].x])sur(ch[ti].old,0),sur(ch[ti].now,1);
}
going(l,qu[i].l);
going(r,qu[i].r);
sur(ls[lca(l,r)],1);
an[qu[i].id]=ys[findans()];
sur(ls[lca(l,r)],0);
}
for(int i=1;i<=qlen;i++)printf("%d
",an[i]);
return 0;
}
未完待续的坑
- 如果能想到二次离线莫队支持修改的思路就放上去吧,我感觉我是真的菜QAQ,但是以我目前的思路来看,二次离线带修莫队应该是不存在的,就暂时咕咕一段时间吧。