在前面的2章中,我们开发了一个自己的web服务器,在这一章节学习如何让http server处理多个http请求。
在这一章的测试中要用到curl命令。在Linux中curl是一个利用URL规则在命令行下工作的文件传输工具,可以说是一款很强大的http命令行工具。它支持文件的上传和下载,是综合传输工具
首先来看下代码:
import socket
SERVER_ADDRESS=(HOST,PORT)='',8888
REQUEST_QUEUE_SIZE=5
def handle_request(client_connection):
request=client_connection.recv(1024)
print request.decode()
http_response='HTTP/1.1 200 OK'
'Hello world '
client_connection.sendall(http_response)
def server_forever():
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind((HOST, PORT))
listen_socket.listen(REQUEST_QUEUE_SIZE)
print 'Serving HTTP on port {port}...'.format(port=PORT)
while True:
client_connection,client_address=listen_socket.accept()
handle_request(client_connection)
client_connection.close()
if __name__=="__main__":
server_forever()
运行后在终端运行:curl http://127.0.0.1:8888/hello后会看到反馈的HTTP页面
root@zhf-maple:/home/zhf/桌面# curl http://127.0.0.1:8888/hello
HTTP/1.1 200 OK
Hello World!
但这是一个迭代式服务器(iterative server),还只能一次处理一个客户端请求。只有在处理完当前客户端请求之后,它才能接收新的客户端连接。这样,有些客户端就必须要等待自己的请求被处理了,而对于流量大的服务器来说,等待的时间就会特别长。我们可以把代码修改下来测试下。在handle_request中添加time.sleep(20), 这就表示在处理完一个请求后,需要等待20秒后才会去处理下一个链接。
def handle_request(client_connection):
request=client_connection.recv(1024)
print request.decode()
http_response=b"""
HTTP/1.1 200 OK
Hello World! """
client_connection.sendall(http_response)
time.sleep(20)
在2个终端上执行curl http://127.0.0.1:8888/hello,在第一个终端打印出信息后,在第二个终端上执行,并没有立即显示出信息。而是到20秒以后才显示出来

通过这个测试可以证明我们的http server是线性工作的,一次只能处理一个请求。那么如何让服务器处理多个请求呢。这就需要用到多线程的原理。下面我们就开始讲解如何进行多线程工作
首先介绍下套接字:
套接字是通信端点(communication endpoint)的抽象形式,可以让一个程序通过文件描述符(file descriptor)与另一个程序进行通信。在本文中,我只讨论Linux/Mac OS X平台上的TCP/IP套接字。其中,尤为重要的一个概念就是TCP套接字对(socket pair)。TCP连接所使用的套接字对是一个4元组(4-tuple),包括本地IP地址、本地端口、外部IP地址和外部端口。一个网络中的每一个TCP连接,都拥有独特的套接字对。IP地址和端口号通常被称为一个套接字,二者一起标识了一个网络端点。
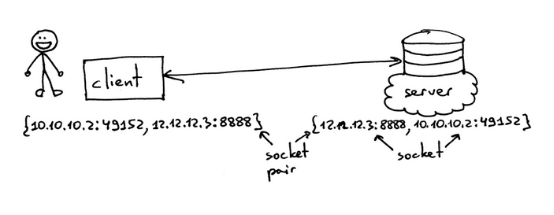
因此,{10.10.10.2:49152, 12.12.12.3:8888}元组组成了一个套接字对,代表客户端侧TCP连接的两个唯一端点,{12.12.12.3:8888, 10.10.10.2:49152}元组组成另一个套接字对,代表服务器侧TCP连接的两个同样端点。构成TCP连接中服务器端点的两个值分别是IP地址12.12.12.3和端口号8888,它们在这里被称为一个套接字(同理,客户端端点的两个值也是一个套接字)。
服务器创建套接字并开始接受客户端连接的标准流程如下:
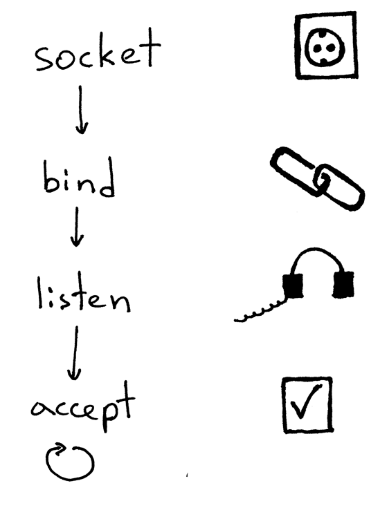
1服务器创建一个TCP/IP套接字。通过下面的Python语句实现:listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
2服务器可以设置部分套接字选项(这是可选项,但你会发现上面那行服务器代码就可以确保你重启服务器之后,服务器会继续使用相同的地址)。listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
3 然后,服务器绑定地址。绑定函数为套接字指定一个本地协议地址。调用绑定函数时,你可以单独指定端口号或IP地址,也可以同时指定两个参数,甚至不提供任何参数也没问题。listen_socket.bind(SERVER_ADDRESS)
4 接着,服务器将该套接字变成一个侦听套接字:
listen_socket.listen(REQUEST_QUEUE_SIZE)
listen方法只能由服务器调用,执行后会告知服务器应该接收针对该套接字的连接请求。
完成上面四步之后,服务器会开启一个循环,开始接收客户端连接,不过一次只接收一个连接。当有连接请求时,accept方法会返回已连接的客户端套接字。然后,服务器从客户端套接字读取请求数据,在标准输出中打印数据,并向客户端返回消息。最后,服务器会关闭当前的客户端连接,这时服务器又可以接收新的客户端连接了。
要通过TCP/IP协议与服务器进行通信,客户端需要作如下操作:
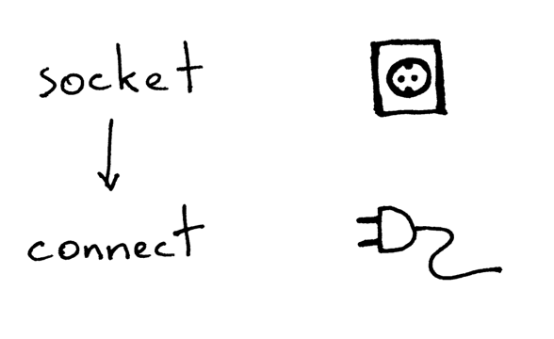
下面这段示例代码,实现了客户端连接至服务器,发送请求,并打印响应内容的过程:
import socket
# create a socket and connect to a server
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect(('localhost', 8888))
# send and receive some data
sock.sendall(b'test')
data = sock.recv(1024)
print(data.decode())
在创建套接字之后,客户端需要与服务器进行连接,这可以通过调用connect方法实现:
sock.connect(('localhost', 8888))
客户端只需要提供远程IP地址或主机名,以及服务器的远程连接端口号即可。
你可能已经注意到,客户端不会调用bind和accept方法。不需要调用bind方法,是因为客户端不关心本地IP地址和本地端口号。客户端调用connect方法时,系统内核中的TCP/IP栈会自动指定本地IP地址和本地端口。本地端口也被称为临时端口(ephemeral port)。
进程:
什么是进程?进程就是正在执行的程序的一个实例。举个例子,当服务器代码执行的时候,这些代码就被加载至内存中,而这个正在被执行的服务器的实例就叫做进程。系统内核会记录下有关进程的信息——包括进程ID,以便进行管理。所以,当你运行迭代式服务器webserver3a.py或webserver3b.py时,你也就开启了一个进程。
通过ps命令,我们可以查找到程序运行的PID,然后通过kill -9 20420的方式杀死这个进程
root@zhf-maple:/home/zhf/桌面# ps -aux | grep webserver3
zhf 20420 0.0 0.1 36440 9436 ? S 07:08 0:00 /usr/bin/python2.7 /home/zhf/py_prj/web_server/webserver3.py
root@zhf-maple:/home/zhf/桌面# kill -9 20420
从ps命令的结果,我们可以看出你的确只运行了一个Python进程webserver3b。进程创建的时候,内核会给它指定一个进程ID——PID。在UNIX系统下,每个用户进程都会有一个父进程(parent process),而这个父进程也有自己的进程ID,叫做父进程ID,简称PPID。在本文中,我默认大家使用的是BASH,因此当你启动服务器的时候,系统会创建服务器进程,指定一个PID,而服务器进程的父进程PID则是BASH shell进程的PID。
在python shell中执行如下代码就可以得到PID和PPID
>>> import os
>>> os.getpid()
24074
>>> os.getppid()
19706
文件描述符:
文件描述符指的就是当系统打开一个现有文件、创建一个新文件或是创建一个新的套接字之后,返回给进程的那个正整型数。系统内核通过文件描述符来追踪一个进程所打开的文件。当你需要读写文件时,你也通过文件描述符说明。Python语言中提供了用于处理文件(和套接字)的高层级对象,所以你不必直接使用文件描述符来指定文件,但是从底层实现来看,UNIX系统中就是通过它们的文件描述符来确定文件和套接字的。
一般来说,UNIX shell会将文件描述符0指定给进程的标准输出,文件描述富1指定给进程的标准输出,文件描述符2指定给标准错误。
>>> import sys
>>> sys.stdin
<open file '<stdin>', mode 'r' at 0x7f4de4c4b0c0>
>>> sys.stdin.fileno()
0
>>> sys.stdout.fileno()
1
>>> sys.stderr.fileno()
2
在linux下一切都是文件,当我们用socket创建一个套接字的时候,获得是一个套接字对象,而不是一个正数,但我们还是可以通过fileno()的方式来直接访问这个套接字的文件描述符。
>>> import socket
>>> sock=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
>>> sock.fileno()
3
在前面的例子中,通过time.sleep(20)让服务器处理完一个请求后睡眠20秒,但是在睡眠期间,我们依然能通过curl命令进行第二次请求,而且服务器也未拒绝。这其中的原因就是套接字中的listen函数,以及使用的BACKLOG参数,来看下listen函数的说明
在代码中,BACKLOG参数被设置为REQUEST_QUEUE_SIZE=5,BACKLOG决定了外部连接请求的队列大小,在代码中被设置为5,因此在服务器进行睡眠的时候,第二个curl命令依然能够连接服务器,是因为连接队列仍然有足够的位置

介绍完了套接字,进程,文件描述符,现在我们可以来进行多进程服务器的开发了。在linux系统中,开发并发服务器的最简单方法就是调用函数fork().在python中当然也内置了fork函数,如果是在windows环境中fork是不起作用的,这个时候就需要用到multiprocessing
1.fork()调用后会创建一个新的子进程,这个子进程是原父进程的副本.子进程可以独立父进程外运行.
2.fork()是一个很特殊的方法,一次调用,两次返回.
3.fork()它会返回2个值,一个值为0,表示在子进程返回;另外一个值为非0,表示在父进程中返回子进程ID.
来看下fork测试的代码:
import time
import os
try:
pid=os.fork()
if pid !=0:
print 'from the parent,the pid is %s' % os.getpid()
else:
print 'from child, the pid is %s' % os.getpid()
except BaseException,e:
print e
time.sleep(30)
运行结果,分别打印出父,子进程的pid。父进程的pid是28217,子进程的pid是28218
/usr/bin/python2.7 /home/zhf/py_prj/web_server/test.py
from the parent,the pid is 28217
from child, the pid is 28218
在终端中运行命令ps -ef | grep test.py也可以看到test.py的两个进程。其中第二个test.py的父进程ppid就是第一个进程的pid
zhf 28217 3056 0 08:06 ? 00:00:00 /usr/bin/python2.7 /home/zhf/py_prj/web_server/test.py
zhf 28218 28217 0 08:06 ? 00:00:00 /usr/bin/python2.7 /home/zhf/py_prj/web_server/test.py
那么接下来通过fork函数来改造之前的服务器端代码:
def server_forever():
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind((HOST, PORT))
listen_socket.listen(REQUEST_QUEUE_SIZE)
print 'Serving HTTP on port {port}...'.format(port=PORT)
print 'Parent PID(PPID):{pid} '.format(pid=os.getpid())
while True:
client_connection,client_address=listen_socket.accept()
pid=os.fork() #复制进程
if pid == 0: #子进程
listen_socket.close() #关闭掉copy子进程的连接
handle_request(client_connection)
client_connection.close()
os._exit(0)
else: #父进程
client_connection.close() #关闭掉父进程
此时在2个终端上运行访问的命令,可以看到没有任何延迟产生。服务器可以处理多个客户端的请求。

从上面代码中可以看到在父进程中也同步关闭了套接字。client_connection.close()那为什么父进程关闭了套接字之后,子进程却仍然能够从客户端套接字中读取数据呢?答案就在下面的图片里
\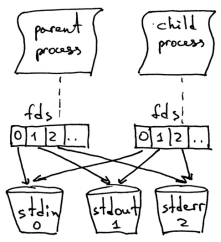
系统内核根据文件描述符计数(descriptor reference counts)来决定是否关闭套接字。系统只有在描述符计数变为0时,才会关闭套接字。当你的服务器创建一个子进程时,子进程就会获得父进程文件描述符的副本,系统内核则会增加这些文件描述符的计数。在一个父进程和一个子进程的情况下,客户端套接字的文件描述符计数为2。当上面代码中的父进程关闭客户端连接套接字时,只是让套接字的计数减为1,还不够让系统关闭套接字。子进程同样关闭了父进程侦听套接字的副本(listen_socket.close()),因为子进程不关心要不要接收新的客户端连接,只关心如何处理连接成功的客户端所发出的请求。服务器父进程的角色:它现在所做的只是接收来自客户端的新连接,fork一个子进程来处理该客户端的请求,然后回到循环的起点,准备接受新的客户端连接
从wireshark抓包来看,首先进行了TCP三次握手,然后是HTTP数据获取,最后等到20秒以后,服务器发送FIN的结束连接.

接下来,我们看看如果不关闭父进程和子进程中的重复套接字描述,会发生什么情况.代码修改如下:
def server_forever():
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind((HOST, PORT))
listen_socket.listen(REQUEST_QUEUE_SIZE)
print 'Serving HTTP on port {port}...'.format(port=PORT)
print 'Parent PID(PPID):{pid} '.format(pid=os.getpid())
clients=[]
while True:
client_connection,client_address=listen_socket.accept()
clients.append(client_connection)
pid=os.fork()
if pid == 0:
listen_socket.close()
handle_request(client_connection)
client_connection.close()
os._exit(0)
else:
print len(clients)
# client_connection.close() #注释掉父进程关闭连接
我们看到,curl命令打印了并行服务器的响应内容,但是并没有结束,而是继续挂死。服务器出现了什么不同情况吗?服务器不再继续睡眠60秒:它的子进程会积极处理客户端请求,处理完成后就关闭客户端连接,然后结束运行,但是客户端的curl命令却不会终止。

我们来抓包看下具体的流程.对比下修改前的数据,可以发现在HTTP流程之后,服务器并没有发送FIN报文.因此TCP连接也就一直存在着并没有断掉

那么为什么curl命令会没有结束运行呢?原因在于重复的文件描述符(duplicate file descriptor)。当子进程关闭客户端连接时,系统内核会减少客户端套接字的计数,变成了1。服务器子进程结束了,但是客户端套接字并没有关闭,因为那个套接字的描述符计数并没有变成0,导致系统没有向客户端发送终止包(termination packet,用TCP/IP的术语来说叫做FIN),也就是说客户端仍然在线。但是还有另一个问题。如果你一直运行的服务器不去关闭重复的文件描述符,服务器最终就会耗光可用的文件服务器,在服务器上运行ulimit -a命令可以看到open files的最大为1024,这代表服务器进程可以使用的文件描述符最大为1024
root@zhf-maple:/home/zhf/桌面# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 31173
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 31173
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
如果有超过1024个客户端接入进来的话,那么整个服务器将崩溃.
我们通过ps -auxw | grep -i python | grep -v grep的命令查看进程,发现在webserver3.py中有两个进程的状态为z.Z代表是僵尸进程.僵尸进程是无法杀死的.通过kill -9的命令也无法杀死

到底什么是僵尸进程,服务器又为什么会创建这些进程?僵尸进程其实是已经结束了的进程,但是它的父进程并没有等待进程结束,所以没有接收到进程结束的状态信息。当子进程在父进程之前退出,系统就会将子进程变成一个僵尸进程,保留原子进程的部分信息,方便父进程之后获取。系统所保留的信息通常包括进程ID、进程结束状态和进程的资源使用情况。如果服务器不处理好这些僵尸进程,系统就会堵塞.现在我们来总结下刚才学习的要点:
如果你不关闭重复的文件描述符,由于客户端连接没有中断,客户端程序就不会结束
(2)如果你不关闭重复的文件描述符,你的服务器最终会消耗完可用的文件描述符(最大打开文件数)
(3)当你fork一个子进程后,如果子进程在父进程之前退出,而父进程又没有等待进程,并获取它的结束状态,那么子进程就会变成僵尸进程。
(4)僵尸进程也需要消耗资源,也就是内存。如果不处理好僵尸进程,你的服务器最终会消耗完可用的进程数(最大用户进程数)。
(5)你无法杀死僵尸进程,你需要等待子进程结束。
那么该如何杀死掉僵尸进程呢,具体方法如下:
当子进程退出的时候,系统内核会发送一个SIGCHLD信号.父进程可以设置一个信号处理函数,用于异步检测SIGCHLD事件,然后再调用wait函数.等待子进程结束并获取结束状态,这样就可以避免产生僵尸进程.
这里先介绍下wait函数:
进程一旦调用了 wait,就立即阻塞自己,由wait自动分析是否当前进程的某个子进程已经退出,如果让它找到了这样一个已经变成僵尸的子进程,wait 就会收集这个子进程的信息, 并把它彻底销毁后返回;如果没有找到这样一个子进程,wait就会一直阻塞在这里,直到有一个出现为止。
那么现在代码修改如下:
import socket
import time
SERVER_ADDRESS=(HOST,PORT)='',8888
REQUEST_QUEUE_SIZE=5
import os
import signal
def handle_request(client_connection):
request=client_connection.recv(1024)
print request.decode()
http_response=b"""
HTTP/1.1 200 OK
Hello World! """
client_connection.sendall(http_response)
time.sleep(20)
def grim_reaper(signum,frame):
pid,status=os.wait()
print 'Child {pid} terminated with status {status} '.format(pid=pid,status=status)
def server_forever():
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind((HOST, PORT))
listen_socket.listen(REQUEST_QUEUE_SIZE)
print 'Serving HTTP on port {port}...'.format(port=PORT)
print 'Parent PID(PPID):{pid} '.format(pid=os.getpid())
signal.signal(signal.SIGCHLD,grim_reaper)
while True:
client_connection,client_address=listen_socket.accept()
pid=os.fork()
if pid == 0:
listen_socket.close()
handle_request(client_connection)
client_connection.close()
os._exit(0)
else:
client_connection.close()
运行后,系统报如下错误
/usr/bin/python2.7 /home/zhf/py_prj/web_server/webserver3.py
Serving HTTP on port 8888...
Parent PID(PPID):11888
GET / HTTP/1.1
Host: 127.0.0.1:8888
User-Agent: curl/7.55.1
Accept: */*
Child 11891 terminated with status 0
Traceback (most recent call last):
File "/home/zhf/py_prj/web_server/webserver3.py", line 45, in <module>
server_forever()
File "/home/zhf/py_prj/web_server/webserver3.py", line 32, in server_forever
client_connection,client_address=listen_socket.accept()
File "/usr/lib/python2.7/socket.py", line 206, in accept
sock, addr = self._sock.accept()
socket.error: [Errno 4] Interrupted system call
这个错误是在调用listen_socket.accept的时候被停止的.这是因为子进程退出时,父进程被阻塞在accept函数调用的地方,但是子进程的退出导致了SIGCHLD事件,这也激活了信号处理函数。信号函数执行完毕之后,就导致了accept系统函数调用被中断,为什么父进程会被阻塞呢,这是因为在子进程退出前,wait调用不会返回,这样父进程就被阻塞而不能执行
那么代码需要修改如下:
def server_forever():
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind((HOST, PORT))
listen_socket.listen(REQUEST_QUEUE_SIZE)
print 'Serving HTTP on port {port}...'.format(port=PORT)
print 'Parent PID(PPID):{pid} '.format(pid=os.getpid())
signal.signal(signal.SIGCHLD,grim_reaper)
while True:
try:
client_connection, client_address = listen_socket.accept()
except IOError,e:
code,msg=e.args
if code == errno.EINTR: #增加对异常的处理
continue
else:
raise
pid=os.fork()
if pid == 0:
print os.getpid()
listen_socket.close()
handle_request(client_connection)
client_connection.close()
os._exit(0)
else:
client_connection.close()
在这里使用到了对errno.EINTR的处理.socket中accept是慢系统调用,在信号产生时会中断其调用并将errno设置为EINTR.
EINTR错误的产生:当阻塞于某个慢系统调用的一个进程捕获某个信号且相应信号处理函数返回时,该系统调用可能返回一个EINTR错误。例如:在socket服务器端,设置了信号捕获机制,有子进程,当在父进程阻塞于慢系统调用时由父进程捕获到了一个有效信号时,内核会致使accept返回一个EINTR错误(被中断的系统调用)。
那么什么是慢系统调用呢:
对于那些可能永远阻塞的函数,我们可以称之为慢系统调用,多数网络支持的函数都属于这一类,比如没有客户连接到服务器,那么服务器对与accept的返回没有保证。
最后我们还需要优化下grim_reaper函数,当有大量的进程同时产生的时候,会触发一大波的SIGCHLD信号发送至父进程,这会导致某些进程无法进入队列,从而导致几个僵尸进程出现.那么解决办法是采用waitpid方法.grim_reaper函数修改如下
def grim_reaper(signum,frame):
while True:
try:
pid, status = os.waitpid(-1, os.WNOHANG)
except OSError,e:
return
if pid == 0:
return
waitpid有两个参数,一个是PID,一个是options参数
pid>0时,只等待进程ID等于pid的子进程,不管其它已经有多少子进程运行结束退出了,只要指定的子进程还没有结束,waitpid就会一直等下去。
pid=-1时,等待任何一个子进程退出,没有任何限制,此时waitpid和wait的作用一模一样。
pid=0时,等待同一个进程组中的任何子进程,如果子进程已经加入了别的进程组,waitpid不会对它做任何理睬/
pid<-1时,等待一个指定进程组中的任何子进程,这个进程组的ID等于pid的绝对值。
options:options提供了一些额外的选项来控制waitpid,目前在Linux中只支持WNOHANG和WUNTRACED两个选项.如果使用了WNOHANG参数调用waitpid,即使没有子进程退出,它也会立即返回,不会像wait那样永远等下去。
waitpid的返回值有3种情况:
1、当正常返回的时候,waitpid返回收集到的子进程的进程ID;
2、如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0;
3、如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;