CSV文件读取:
Csv文件格式如下:分别有2行三列。

访问代码如下:
f=open(r'E:py_prj est.csv','rb')
f_csv=csv.reader(f)
for f in f_csv:
print f
在这里f是一个元组,为了访问某个字段,需要用索引来访问对应的值,如f[0]访问的是first,f[1]访问的是second,f[2]访问的是third. 用列索引的方式很难记住。一不留神就会搞错。可以考虑用对元组命名的方式
这里介绍namedtuple的方法。
下面的例子中实现用namedtuple创建一个对象赋值给user。其中对象实例是user,包含了3个属性值,分别是name,age,height。通过赋值后得到u
就可以利用属性访问的方法u.name来访问各个属性
user=namedtuple('user',['name','age','height'])
u=user(name='zhf',age=20,height=180)
print u.name
这种方法也可以用到csv文件的读取上。代码修改如下
f=open(r'E:py_prj est.csv','rb')
f_csv=csv.reader(f)
heading=next(f_csv)
Row=namedtuple('Row',heading)
for row in f_csv:
row=Row(*row)
print row.first,row.second,row.third
这样访问起来就直观多了。那么用对象的方式看起来太复杂了点。可以用字典的方式么。也是可以的而且方法更加简洁。方法如下。
f=open(r'E:py_prj est.csv','rb')
f_csv=csv.DictReader(f)
for row in f_csv:
print row['first']
同样的写入也可以用csv.DictWriter()
Json数据:
Json和xml是网络世界上用的最多的数据交换格式。Json主要有以下特点:
1 对象表示为键值对,也就是字典的形式
2 数据又逗号分隔
3 花括号保存对象
4 方括号保存数组
操作json文件的方法如下:
data={'name':'zhf','age':30,'location':'china'}
f=open('test.json','w')
json.dump(data,f)
f=open('test.json','r')
print json.load(f)
在生成的json文件中格式如下:

可以看到json的这种键值结构在感官上比XML的结构要简单得多,也更一目了然。
我们还可以对json进行扩展。如下面的数据。在record的键值里面是一个数组,数组里面有2个字典数据
data={'name':'zhf','age':30,'location':'china','record':[{'first':'china','during':10},{'second':'chengdu','during':20}]}
可以看到json可以存储复杂的数据结构。当我们打印出来的时候。可以看到结构的可视化结果不怎么好。

我们可以用pprint的方法将结果打印出结构化的样子:pprint(json.load(f))
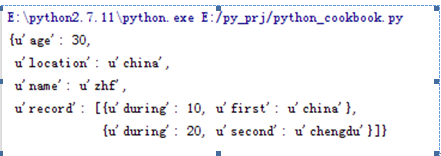
这样看起来就清晰直观多了
解析XML文件:
XML(eXtensible Markup Language)指可扩展标记语言,被设计用来传输和存储数据。XML和JSON两种文件格式是互联网上应用得最多的数据传输格式。Python解析XML有三种方法:一是xml.dom.*模块。二是xml.sax.*模块 三是xml.etree.ElementTree模块
首先介绍dom模块。一个DOM的解析器在解析一个XML文档的时候。一次性读取整个文档。把文档中的所有元素保存在内存中的一个树结构中。 可以看到这种方式比较适用于解析数据小的XML文档,否则会很耗内存。
比如下面的结构。<string-array>下面包括许多<item>。这个结构包含了北京市下面的地级市

解析代码如下:
def xml_try():
domtree=xml.dom.minidom.parse(r'D: est_sourcearrays.xml')
data=domtree.documentElement
city=data.getElementsByTagName('string-array')
for c in city:
print c.getAttribute('name')
cityname =c.getElementsByTagName('item')
for name in cityname:
print name.childNodes[0].data
首先用domtree.documentElement将XML文件所有内容录入。然后用getElementsByTagName读取所有tag名字为string-array的结构。然后在每个结构里面再进行具体的解析。遍历到子节点的时候用childNodes来访问最后的末端元素。getAttribute得到具体的属性。
同样的文件我们用ElementTree解析方法如下:首先查找所有的string-array节点。然后再其中查找所有的item节点。然后输出节点内容
from xml.etree.ElementTree import parse
def xml_try():
doc=parse(r'D: est_sourcearrays.xml')
for city in doc.findall('string-array'):
name=city.findall('item')
for n in name:
print n.text
如果我们想精准的查找某个节点结构。方法如下:
doc1=parse(r'D: est_source
ss20.xml')
for item in doc1.iterfind('channel/item/title'):
print item.text
xml结构如下:

上面是定位了最后一级的子节点。如果要定位到上面的父节点,然后查找所有的子节点的方法如下:
doc1=parse(r'D: est_source
ss20.xml')
for item in doc1.iterfind('channel/item'):
print item.findtext('title')
print item.findtext('link')
前面2种方法都是一次性的将XML文件所有数据读入,然后再来进行查找。这种方法优点是查找速度快,但是很耗内存。其实大多数的情况下我们只是查找特定的元素。一次性的全部读入。会导致很多不必要的数据被写入。如果可以边查找边判断的话,那么可以大大的节约内存,iterparse就是这样的方法:还是用之前的文档。
from xml.etree.ElementTree import iterparse
doc2=iterparse(r'D: est_source
ss20.xml',('start','end'))
for event,elem in doc2:
print 'the event is %s' % event
print elem.tag,elem.text
我们截取了一小部分的结果。

对应的XML结构

发现什么规律么,当遇到<title>的字符的时候,event就是start,当遇到</title>的时候event就是end. Iterparse返回2个元素,一个是event。一个是elem.这个elem就是位于start和end之间的元素。从上面的打印可以看到elem.tag,elem.text被打印了两次。这是由于在event为start的时候,打印了一次。在event为end的时候又被打印了一次。
我们可以修改代码如下,当只有在event为end的时候才输出text
doc2=iterparse(r'D: est_source
ss20.xml',('start','end'))
for event,elem in doc2:
print 'the event is %s' % event
if event == 'end':
print elem.tag,elem.text
既然iterparse能够扫描一个个的元素,并得到对应的text.那么我们就可以将这个函数转换为生成器。代码修改如下:
def xml_try(element):
tag_indicate=[]
doc2=iterparse(r'D: est_source
ss20.xml',('start','end'))
for event,elem in doc2:
if event == 'start':
tag_indicate.append(elem.tag)
if event == 'end':
if tag_indicate.pop() == element:
yield elem.text
if __name__=='__main__':
for r in xml_try('title'):
print r
在上面的代码中。当event为start的时候,记录此时的tag。当event为end的时候,比较记录的tag值和传入的element值。如果相当,则返回此时的elem.text. 在代码中我们传入的是title。得到的结果如下。

从上面几段代码可以看到,iterparse主要应用于比较大的xml文件。这种情况下如果一次性的读入所有数据形成树状结构,很耗内存。