最近重构了一个服务,经过测试,发现一个奇怪的BUG,服务在机器A上消耗内存87G,在机器B上消耗内存66G,两者内存相差比较大,但是老服务则没有该问题。
我对该问题异常疑惑,同样的服务不可能会内存差异这么巨大,该服务调用了其他同事开发的动态库,但是老服务没有这种问题,说明与同事开发的动态库没有关系。
1.我初步怀疑是重构服务的代码与老服务设计有所不同,可能老服务里配置了什么环境变量之类的东西,用来关闭动态库的内存消耗,经过研究老服务代码,并未发现此类设计(因为我并没有通篇仔细阅读,可能存在偏差,我对老服务毫无研究,自认为短暂的看代码无法看出问题),但是还是尝试做了一些修改,保持和老代码一致,结果并没有解决问题。
2.通过多次测试,我发现一个现象,发现机器A上每个计算进程内存占用并不平均,机器B上每个计算进程占用内存却很平均,机器A占用的内存过多,更多的是这些不平均导致的。于是我想只要我能分析出来这些内存是哪里消耗的,是否就能解决问题呢。
3.开始分析进程内存
3.1 先观察内存分布情况,比较正常的进程和不正常的进程之间的差异,找出异常内存地址
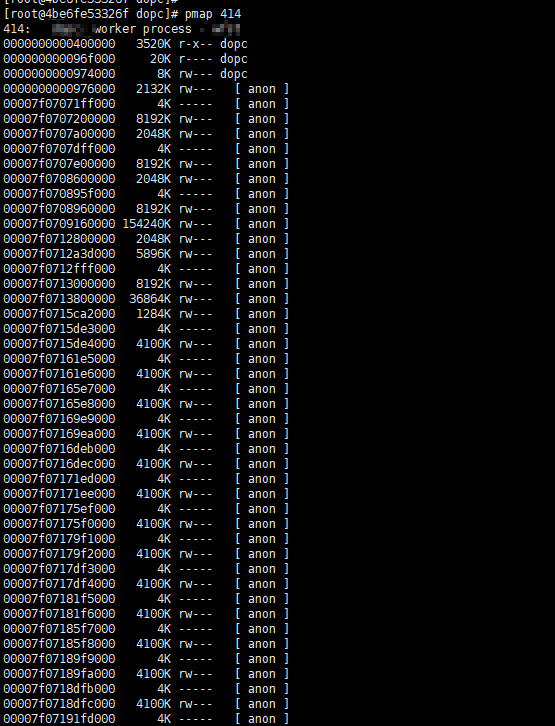
# pmap [pid]
pmap {pid}获取内存分布情况如下图可以看到内存占用比较大的heap区
3.2 保存不正常进程的堆栈信息(gdb在容器中使用的时候需要特权模式)
# gdb attach {pid}
执行(gdb)gcore命令dump生成core文件,注意会短暂的夯死主进程,coredump文件会保存在当前目录下。

3.3 分析不正常进程的堆栈信息
# gdb -c {core文件} {你的执行程序} (gdb)set height 0 (gdb)set logging on (gdb) x/612205568a 0x0000000005c2b000 x/612205568a 格式说明: 612205568=4782856*1024/8 (因为是64 bit所以要/8byte) a为gdb输出其中一种格式(可以参看gdb x现象内存数据根式说明)
通过以上分析,异常内存里全是0x0,无法看出任何异常
4. 仔细阅读代码并没有发现异常,采用排除法定位问题。
我注释掉动态库调用,发现机器A内存分布平均了,不再有异常问题,怀疑问题可能还是在动态库调用上,于是求助动态库开发同事帮忙分析,经过一个下午,动态库同事以可执行程序方式运行代码,没有出现内存异常增加问题,我观察到动态库开发同事运行的代码每个计算进程之间内存分布也是很平均的,动态库同事无法提供帮助。但是我觉得应该不是动态库的问题,无论老服务还是同事自己的测试程序都说明这一点,问题肯定出现在我的重构服务上。
5.回来继续分析自己重构服务,现在需要比较新老两个服务的不同点,一个个排除。既然与内存相关,我的重构服务使用了jemalloc来做内存管理,我决定先把jemalloc取消调用,再测试一下。结果发现内存降到跟老服务一模一样了,根本原因出现在jemalloc上。猜测jemalloc做了一些内存优化管理,提前申请了一些内存,但是在多进程场景下,这种申请内存变得太巨大了,引起内存异常增加问题。
6.查找jemalloc资料,关闭jemalloc内存分配,问题解决。
总结:
记录本次分析最主要原因是这个问题很奇怪,耗费了我3天时间,代价巨大,值得记录,但是重点不是关注jemalloc内存分配BUG,而是内存异常问题该如何分析,定位,重要的是过程并非结果。