准备知识
Tensorflow运算API
矩阵运算:tf.matmul(x, w)
平方:tf.square(error)
均值:tf.reduce_mean(error)
梯度下降API
tf.train.GradientDescentOptimizer(learning_rate):梯度下降优化
- learning_rate:学习率
- return:梯度下降op
简单的线性回归的实现
# 准备数据
x = tf.random_normal([200, 1], mean=1.2, stddev=0.6, name="x")
y = tf.matmul(x, [[0.5]]) + 0.8
# 建立线性回归模型
weight = tf.Variable(tf.random_normal([1, 1], mean=0, stddev=1.0), name="weight")
bais = tf.Variable(0.0, name="bais")
# 预测值
y_predict = tf.matmul(x, weight) + bais
# 损失函数,均方误差
loss = tf.reduce_mean(tf.square(y - y_predict))
# 梯度下降优化损失
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 初始化op
init_op = tf.global_variables_initializer()
# 运行
with tf.Session() as sess:
sess.run(init_op)
for i in range(200):
sess.run(train_op)
print("第%d次优化的权重为%f,偏置为%f" % (i, weight.eval(), bais.eval()))
部分运行结果:
第0次优化的权重为1.317120,偏置为-0.072556
第1次优化的权重为1.240519,偏置为-0.088773
第2次优化的权重为1.199426,偏置为-0.078846
第3次优化的权重为1.152779,偏置为-0.071317
第4次优化的权重为1.125252,偏置为-0.052198
第5次优化的权重为1.097908,偏置为-0.033999
第6次优化的权重为1.081992,偏置为-0.010126
...
第194次优化的权重为0.503366,偏置为0.795440
第195次优化的权重为0.503219,偏置为0.795541
第196次优化的权重为0.503130,偏置为0.795662
第197次优化的权重为0.503025,偏置为0.795741
第198次优化的权重为0.502987,偏置为0.795893
第199次优化的权重为0.502896,偏置为0.796023
建立事件文件
tf.summary.FileWriter("./temp/tf/summary/test", graph=sess.graph)
打开TensorBoard:
$ tensorboard --logdir="./temp/tf/summary/test"
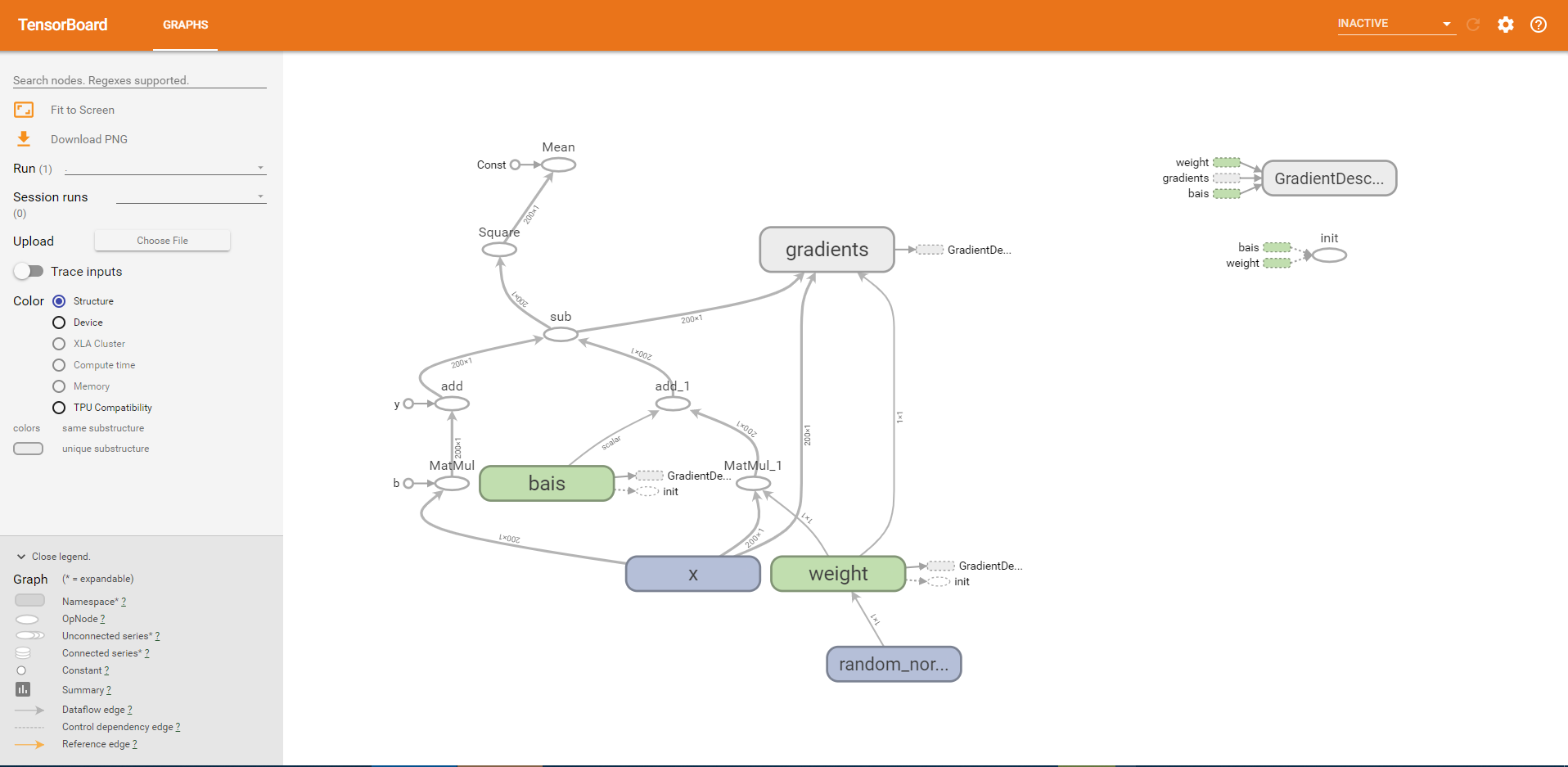
上图的图形比较乱,怎样才能更加的直观呢?
变量作用域
tensorflow提供了变量作用域和共享变量这样的概念,有几个重要的作用。
- 让模型代码更加清晰,作用分明
通过tf.variable_scope()创建指定名字的变量作用域
上例加上变量作用域
with tf.variable_scope("data"):
# 准备数据
x = tf.random_normal([200, 1], mean=1.2, stddev=0.6, name="x")
y = tf.matmul(x, [[0.5]]) + 0.8
with tf.variable_scope("model"):
# 建立线性回归模型
weight = tf.Variable(tf.random_normal([1, 1], mean=0, stddev=1.0), name="weight")
bais = tf.Variable(0.0, name="bais")
# 预测值
y_predict = tf.matmul(x, weight) + bais
with tf.variable_scope("loss"):
# 损失函数,均方误差
loss = tf.reduce_mean(tf.square(y - y_predict))
with tf.variable_scope("optimizer"):
# 梯度下降优化损失
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
再次观察图形:

增加变量显示
目的:观察模型的参数、损失值的变化情况
1、收集变量
-
tf.summary.scalar(name=’’,tensor) 收集对于损失函数和准确率等单值变量,name为变量的名字,tensor为值
-
tf.summary.histogram(name=‘’,tensor) 收集高维度的变量参数
-
tf.summary.image(name=‘’,tensor) 收集输入的图片张量能显示图片
2、合并变量写入事件文件
-
merged = tf.summary.merge_all()
-
运行合并:summary = sess.run(merged),每次迭代都需运行
-
添加:FileWriter.add_summary(summary,i),i表示第几次的值
收集上例中的损失、权重
# 收集tensor
tf.summary.scalar("losses", loss)
tf.summary.histogram("weights", weight)
# 定义合并tensor的op
merged = tf.summary.merge_all()
合并到事件流
# 运行合并的tensor
summary = sess.run(merged)
fw.add_summary(summary, i)


模型的保存与加载
在我们训练或者测试过程中,总会遇到需要保存训练完成的模型,然后从中恢复继续我们的测试或者其它使用。模型的保存和恢复也是通过tf.train.Saver类去实现,它主要通过将Saver类添加OPS保存和恢复变量到checkpoint。它还提供了运行这些操作的便利方法。
tf.train.Saver(var_list=None,max_to_keep=5)
- var_list:指定将要保存和还原的变量。它可以作为一个dict或一个列表传递.
- max_to_keep:指示要保留的最近检查点文件的最大数量。创建新文件时,会删除较旧的文件。如果无或0,则保留所有检查点文件。默认为5(即保留最新的5个检查点文件。)
自定义命令行参数
tf.app.run(),默认调用main()函数,运行程序。main(argv)必须传一个参数。
tf.app.flags,它支持应用从命令行接受参数,可以用来指定集群配置等。在tf.app.flags下面有各种定义参数的类型
- DEFINE_string(flag_name, default_value, docstring)
- DEFINE_integer(flag_name, default_value, docstring)
- DEFINE_boolean(flag_name, default_value, docstring)
- DEFINE_float(flag_name, default_value, docstring)
第一个也就是参数的名字,路径、大小等等。第二个参数提供具体的值。第三个参数是说明文档
tf.app.flags.FLAGS,在flags有一个FLAGS标志,它在程序中可以调用到我们前面具体定义的flag_name.