版本:虚拟机下安装的ubuntu14.04(64位),hadoop-2.6.0
下面是hadoop2.6.0的官方英文教程:
hadoop下载地址:
http://mirror.bit.edu.cn/apache/hadoop/common/
选择hadoop-2.6.0.tar.gz这个二进制文件
安装之前首先考虑的是hadoop的版本问题,hadoop-1x和hadoop-2x其实完全是两个东西,生产环境下多采用hadoop1.2.1-这是一个稳定的版本。而hadoop-2x版本更适合做实验。
其次hadoop2.6.0本地库文件是64位的,而hadoop2.4.0本地库是32位的。如果跟系统版本不匹配,运行hadoop例子时会出现:
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable(这个错误也可能是其他原因导致的,我遇到的是其他原因,后面会说解决办法)
最后是hadoop的三种模式:单机、伪分布、全分布。其中全分布模式至少需要三个节点。
1.安装前准备
一、添加hadoop用户组和hadoop用户
创建hadoop用户组:sudo addgroup hadoop
创建hadoop用户: sudo adduser -ingroup hadoop hadoop
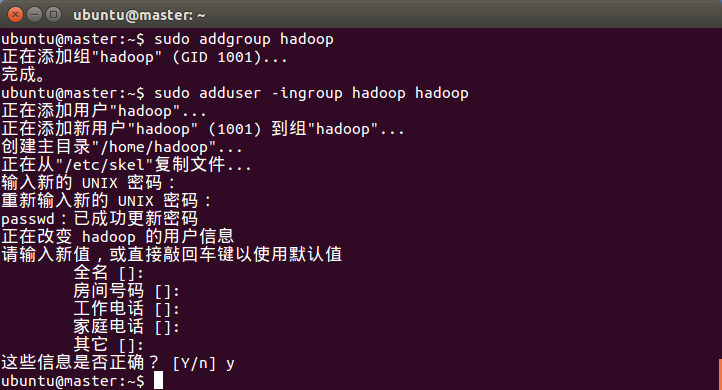
添加结果如下(其中通过系统设置设置hadoop账户类型为管理员):

进入hadoop用户的账号
二、安装ssh
安装命令:sudo apt-get install openssh-server
启动服务:sudo /etc/init.d/ssh start
查看服务是否启动:ps -e | grep ssh

设置免密码登录,生成私钥和公钥:ssh-keygen -t rsa -P ""
默认会在/home/hadoop/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥。(.ssh文件是隐藏文件,CTRL+H 显示隐藏文件)
将公钥追加到authorized_keys中:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
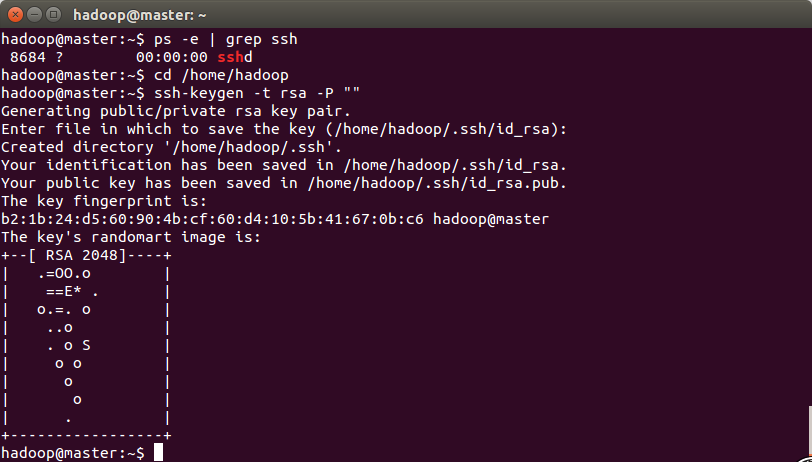
然后用ssh连接自己:ssh localhost。如果还是需要密码,则没有成功。
三、安装java jdk和配置环境变量
安装openjdk命令:sudo apt-get install openjdk-7-jdk
然而openjdk东西比较少,可以安装oraclejdk:(推荐安装Java-7-oracle)

sudo add-apt-repository ppa:webupd8team/java sudo apt-get update sudo apt-get install oracle-java7-installer
最后通过:java -version查看是否安装成功,并显示java版本。
查看JAVA_HOME位置:sudo update-alternatives --config java

我的结果是/usr/lib/jvm/java-7-oracle/bin/jre/java。配置环境变量只写到java-7-oracle。
配置环境变量:
命令:sudo gedit ~/.bashrc (配置.bashrc文件,或者.profile文件)
在文件末尾加入(第二行JAVA_HOME和第三行HADOOP_INSTALL安装路径改成自己的)#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-7-oracle export HADOOP_INSTALL=/usr/local/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib" #HADOOP VARIABLES END
使环境变量设置立即生效(重新注销或者重启都行):source ~/.bashrc
2.hadoop配置
我的hadoop安装路径/usr/local/hadoop,下载的文件解压缩后的文件名改成了hadoop。给hadoop文件夹及其文件夹所有文件提高权限!
hadoop配置文件放在{HADOOP安装路径}/etc/hadoop文件夹下:需要修改hadoop-env.sh,core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml五个文件。
1.hadoop-env.sh文件,在末尾添加(第一行JAVA_HOME和第二行HADOOP_PREFIX(hadoop安装路径)改成自己的)
export JAVA_HOME=/usr/lib/jvm/java-7-oracle export HADOOP_PREFIX=/usr/local/hadoop export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib:$HADOOP_PREFIX/lib/native"
注意第三行的HADOOP_OPTS,如果没有这一项运行会有:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable的错误提示。如果你是32位的系统,运行hadoop2.6.0还需要重新编译本地库。本地库路径为:{hadoop安装路径}/lib/natives。
查看本地库版本命令:file /usr/loacl/hadoop/lib/native/libhadoop.so.1.0.0

(32位)libhadoop.so.1.0.0: ELF 32-bit LSB shared object, Intel 80386, version 1 (SYSV), dynamically linked, not stripped
(64位)libhadoop.so.1.0.0: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, not stripped
查看系统位数:uname -a,如果有x86_64就是64位的,没有就是32位的。
2.core-site.xml文件,在末尾<configuration></configuration>中间添加内容,最后:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.
</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
其中前一部分的hadoop.tmp.dir参数官方教程里没有,如果没有配置临时文件会默认生成在:根目录/tmp/hadoop-hadoop中,但是重启系统后内容会重新删掉,会有意想不到的问题出现!!注意修改路径.
3.mapred-site.xml是没有的,有一个mapred-site.xml.template文件将其改名为mapred-site.xml就好。同样在末尾<configuration></configuration>中间添加内容,最后:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.yarn-site.xml文件,在末尾<configuration><!-- Site specific YARN configuration properties --></configuration>添加内容,最后:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5.hdfs-site.xml文件,在末尾<configuration></configuration>中间添加内容,最后:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
</configuration>
后面两个dfs.name.dir,dfs.datanode.data.dir参数官网教程没有(注意修改路径),新建dfs和tmp文件夹并不必须,hadoop启动后会自动生成。
3.hadoop运行
- 格式化hdfs:/usr/local/hadoop$ bin/hdfs namenode -format
/usr/local/hadoop$ bin/hdfs namenode -format
当出现:INFO common.Storage: Storage directory /home/hadoop/tmp/dfs/name has been successfully formatted.表示成功。只需要格式化一次。

- hadoop启动,执行:/usr/local/hadoop$ sbin/start-all.sh




4.WordCount验证
- dfs下创建input目录
/usr/local/hadoop$ bin/hadoop fs -mkdir -p input
- 运行例子:
(1)复制一些文件到HDFS目录/usr/<usrname>下:/usr/local/hadoop$ hadoop fs -copyFromLocal README.txt input
(2)运行:/usr/local/hadoop$ hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.4.0-sources.jar org.apache.hadoop.examples.WordCount input output
(3)运行完毕后,查看单词统计结果 /usr/local/hadoop$ hadoop fs -cat output/*

- 关闭hadoop:/usr/local/hadoop$ bin/stop-all.sh
/usr/local/hadoop$ bin/stop-all.sh
至此搭建完成。