2021-03-04
链接:https://www.zhihu.com/question/66200879/answer/870023448
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
自动求导 (Automatic Differentiation, AD) 的课程 (CS207),正好来回答一下。 其实不只是 TensorFlow,Pytorch 这些为深度学习设计的库用到 AD,很多物理,化学等基础科学计算软件也在大量的使用 AD。而且,其实TensorFlow、Pytorch 也并非只能用于deep learning,本质上他们是一种
Tensor computation built on a tape-based autograd system --引自Pytorch
自动求导分成两种模式,一种是 Forward Mode,另外一种是 Reverse Mode。一般的机器学习库用的后一种,原因后面说。
Forward Mode
基于的就是就基本的 链式法则 chain rule,
这个 Forward Mode 就是用 chain rule,像剥洋葱一样一层一层算出来
以
为例。 我们可以把他的计算图画出来。
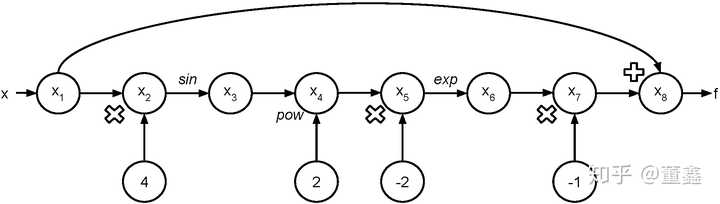
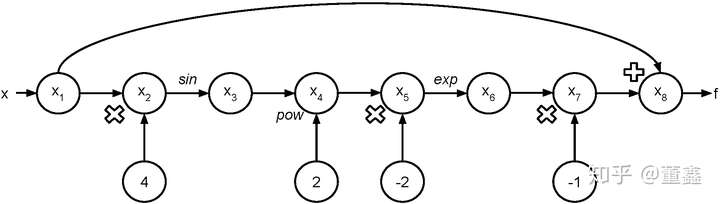
假如我要 计算 ,可以根据上面的图得到一个表格
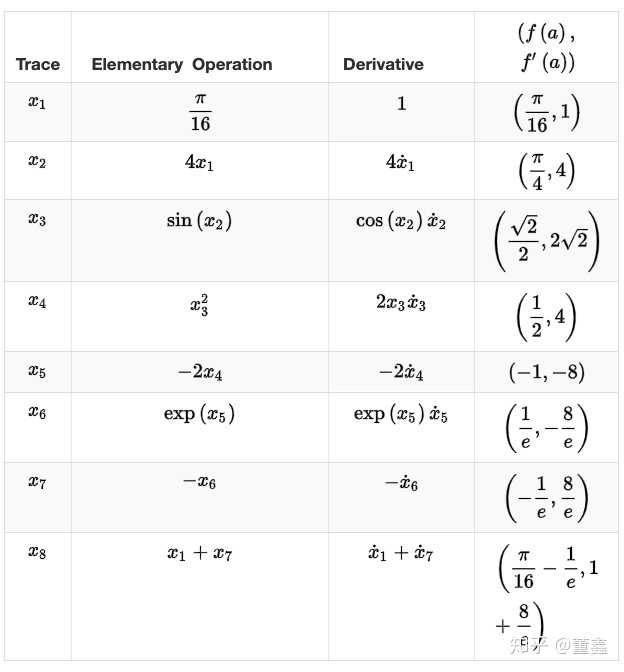
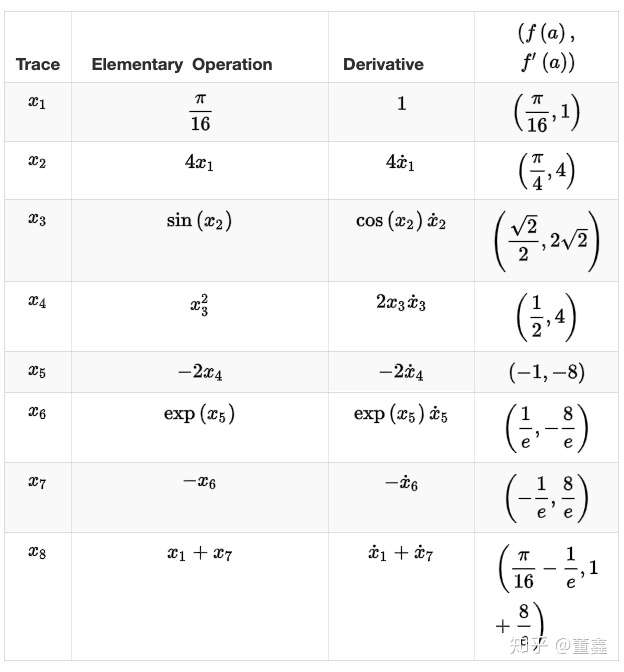
那么上面这个表里,每一步我们既要算 forward 的值 ,也要算 backward 的值
。
有没有办法同时把这两个值算出来呢?
首先引入一个新的概念,二元数。二元数其实跟复数差不多,也是一种实数的推广。我们回忆一下,一个复数可以写成这样的形式:
对于复数的理解,一个比较直观的例子就是。本来实数都是在一个实数轴(x轴)的。复部 相当于多了一个 y 轴出来。
那么二元数是这个亚子,
这个二元数很神奇的一个性质是,你带着他做运算,得出来的二元部 前面的系数,就是导数。举个栗子, 我们要求
我们可以把 ,所以
我们把上面的三角函数展开,
得到
可以看到,二元部 恰好就是原函数
的导数。
Reverse Mode
这个模式就比较简单和直接了。就是说,上面那个表里面,我每次只计算每个“小运算”的梯度(也是是那个图里面的每个节点),最后我再根据 chain rule 把“小运算”们的梯度串起来。其实 forward mode 和 reverse mode 并没有本质的区别,只是说,reverse mode在计算梯度先不考虑 chain rule,最后再用 chain rule 把梯度组起来。而前者则是直接就应用 chain rule 来算梯度。
下面总结一下 reverse mode 的流程:
- 创建计算图
- 计算前向传播的值及每个操作的梯度
- 这里没有
chain rule的事 - 比如这个操作是乘法 $x_3 = x_1*x_2$,那么我们只需要把
算出来就好了
- 反向计算梯度从最后一个节点(操作)开始:
- 根据
chain rule逐层推进 - 假如有多条求导路径,我们要把他们加起来,例如
举个栗子,我们要计算函数
在点 的导数
首先还是先把计算图画出来
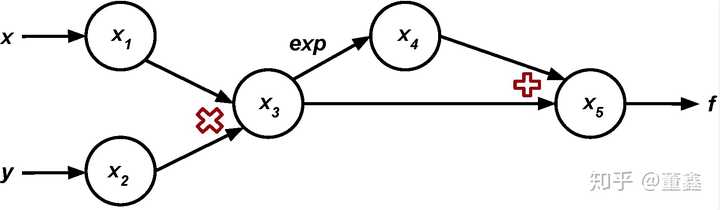
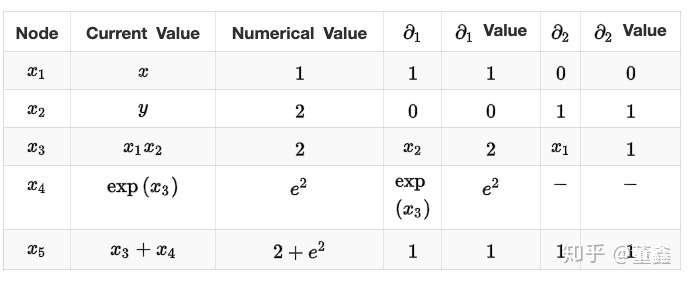
我们逐层的抽丝剥茧,
总结
- 可以很清楚的看到,在训练人工神经网络时常用的
backpropagation也是属于reverse mode的。 - 假如我们要计算的梯度的函数是
- 如果 n 是相对比较大的话,用
forward比较省计算 - 如果 m 是相对比较大的话,用
reverse比较省计算