1. pip install gym
可以看到,增强学习和监督学习的区别主要有以下两点:
1. 增强学习是试错学习(Trail-and-error),由于没有直接的指导信息,智能体要以不断与环境进行交互,通过试错的方式来获得最佳策略。
2. 延迟回报,增强学习的指导信息很少,而且往往是在事后(最后一个状态)才给出的,这就导致了一个问题,就是获得正回报或者负回报以后,如何将回报分配给前面的状态。
上篇我们提到增强学习学到的是一个从环境状态到动作的映射(即行为策略),记为策略π: S→A。而增强学习往往又具有延迟回报的特点: 如果在第n步输掉了棋,那么只有状态sn和动作an获得了立即回报r(sn,an)=-1,前面的所有状态立即回报均为0。所以对于之前的任意状态s和动作a,立即回报函数r(s,a)无法说明策略的好坏。因而需要定义值函数(value function,又叫效用函数)来表明当前状态下策略π的长期影响。
价值函数:第二行有错误多写了一个γ.
当一个策略取定,就是说Si,ai 这个数组取定.那么拟合下面这个等比函数.
其中ri表示未来第i步回报,
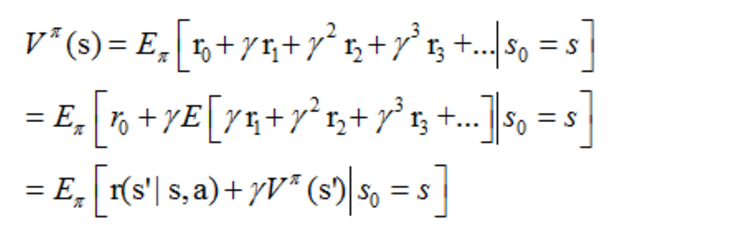
PageRank算法简介
http://blog.jobbole.com/71431/
1.基本方法是矩阵不停的乘法,一直到收敛
2.利用加个概率来更改迭代公式即可解决终止点问题和陷阱问题.
重新学机器学习:
https://blog.csdn.net/supercally/article/details/54754787
https://blog.csdn.net/Young_Gy/article/details/73485518


这里面的max是对a'来取得.因为s'已经取定了.
●对于bellman公式的理解.
这个Q表是2维的,行表示s取值,列表示a取值.
为什么是这个公式:r表示原来的Q(s,a),max(Q(s',a'))表示s'状态的最大价值.用这个价值来表示s'状态的价值.(这么做是合理的,
因为我们的决策是每一步按照百分之90的概率选最大的action.所以这个最大价值来替换价值是几乎必然事件).
所以他也就是Q(s,a)这一步走完会获得的reward.
●这个γ如果取1.那么根据决策一步一步迭代下去,更新完Q(s,a)之后就百分之90概率更新Q(s',a')百分之10概率更新一个randomQ(s',a)
把多步写一起就得到Q(s,a)=r+max(Q(s1,a1))+...+max(Q(s10,a10)).这种做法显然有问题.
因为Q(s9,a9)=r!+max(Q(s10,a10)),比如s10就是终点,给100分.那么第一次跑Q(s9,a9)就是100.因为初始值是0.
从而Q(s,a)基本是1000.但是如果问题非常大,跑了1万步才到,那么Q(s,a)就会非常大.溢出不溢出先不说,这种怎么大的数对于Q矩阵的含义
就会发生扭曲,跟我们原本的Q矩阵建立本质是冲突的.
ps:γ取0.显然不合理啊.那还学个屁.一直Q表都不动.
所以一般我们取γ是0.9
●双盘心得:其实腿越接近胸,越简单,可以用这个方法练习.双盘对神经练习非常爽.
头发:早睡,11点必须睡,想玩早上早起玩.不然总是枕头上有头发茬.
发现没事别上高速,挂率很高,不如做高铁