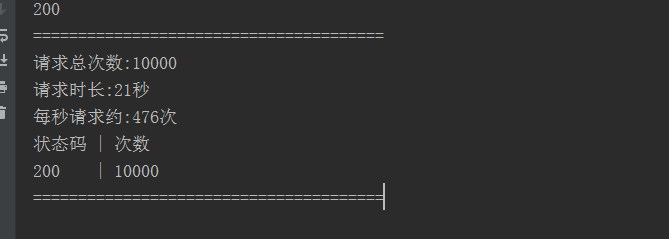
import requests import queue import threading import time status_code_list = [] exec_time = 0 class MyThreadPool: def __init__(self, maxsize): self.maxsize = maxsize self._pool = queue.Queue(maxsize) for _ in range(maxsize): self._pool.put(threading.Thread) def get_thread(self): return self._pool.get() def add_thread(self): self._pool.put(threading.Thread) def request_time(func): def inner(*args, **kwargs): global exec_time start_time = time.time() func(*args, **kwargs) end_time = time.time() exec_time = end_time-start_time return inner def get_url(url): global status_code_list,x headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36', } response = requests.get(url,headers=headers) code = response.status_code status_code_list.append(code) print(code) return code def get_count(_url='http://10.0.0.141',_count=100): ''' :param count: 每个线程请求的数量 ''' global status_code_list,url,count for i in range(count): get_url(url) def request_status(): count_num = len(status_code_list) set_code_list = set(status_code_list) status_dict = {} for i in set_code_list: status_dict[i] = str(status_code_list).count(str(i)) echo_str(count_num, set_code_list, status_dict) def echo_str(count_num,set_code_list,status_dict): print('=======================================') print('请求总次数:%s'%count_num) print('请求时长:%s秒'%int(exec_time)) second_request = count_num/int(exec_time) print('每秒请求约:%s次'%int(second_request)) print('状态码 | 次数') for k,v in status_dict.items(): print(str(k)+' | '+str(v)) print('=======================================') @request_time def run(url,thread_num=10,thread_pool=10): ''' :param thread_num: 总共执行的线程数(总的请求数=总共执行的线程数*没个线程循环请求的数量) :param thread_pool: 线程池数量 :param url: 请求的域名地址 ''' global x,status_code_list pool = MyThreadPool(thread_pool) for i in range(thread_num): t = pool.get_thread() obj = t(target=get_count) obj.start() obj.join() if __name__ == '__main__': count = 100 #单个线程的请求数 url = 'http://10.0.0.141' run(url,100,100) request_status()
#结果查看