numpy
列表变矩阵

几维 array.ndim
形状 array.shape 几行几列
多少元素 array.size
![]()
![]() 三行四列的矩阵
三行四列的矩阵
![]()
empyt 几乎接近于0的矩阵
arrange有序的数列或矩阵
![]()
![]()
![]()
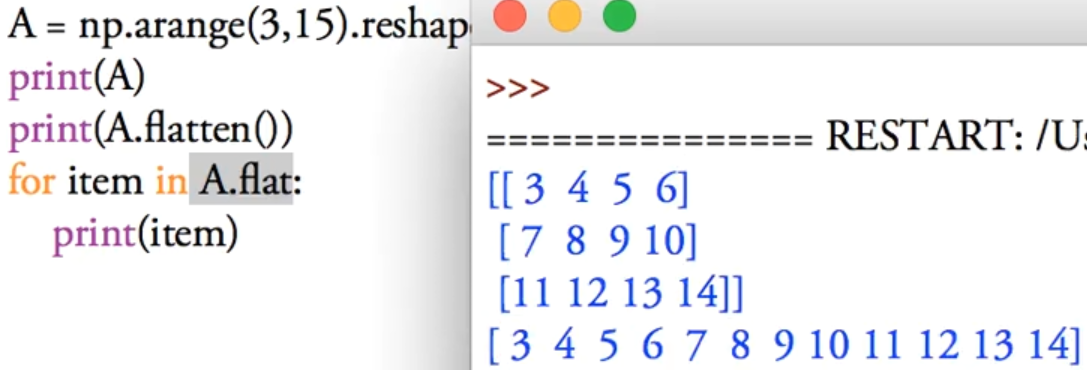
生成线段
1~10 5段的数列
![]()
![]()
![]()
平方 b**2
sin值 ![]()
判断大小返回值为Ture或False
矩阵的乘法

np.dot 矩阵的运算结果
![]() 2行4列 从0到1随机
2行4列 从0到1随机

左边axis=0 上边axis=1

![]()
 最大最小值的索引
最大最小值的索引
平均值
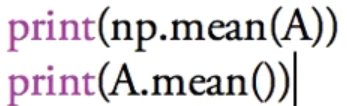
![]()
![]() 行进行计算
行进行计算
中位数
![]()
逐步累加
2、5、9、14、20 ......
![]()
累差(减)
第n+1前去第n 列会减少
![]()
找出不是0的数
![]() 按索引显示
按索引显示
![]()
np.sort(A) 逐行从小到大排序
转置
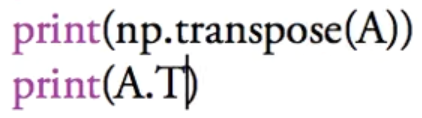
所有小于5的数都等于5所有大于9的数都等于9
![]()
A([2,1]) 2行1列的数
A([2,:]) :代表所有
A([:,1]) 第1列的所有数
A([1,1:3]) 第1行的从1到3的数
迭代列

合并
上下合并
![]()
左右合并
![]()
![]()
后面加了个维度
![]()
![]()
多个arange的合并
![]() 纵向
纵向
分割
![]() 纵向分割成2块 行(横着分就成纵了)
纵向分割成2块 行(横着分就成纵了)
![]() 横向分割3块
横向分割3块
纵向不等分割
![]()
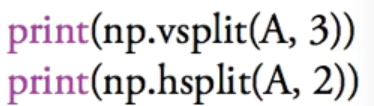
横向3块与纵向2块
numpy中赋值后改变都改变 连再一起
不关联 b=a.copy()
pandas
定义一个序列


![]()
index左边的标题 columns 上边的标题 不加的话默认0、1、2
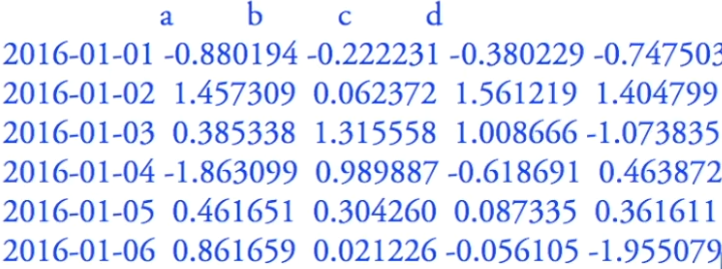
print(df.sort_index(axis=1, ascending=False)) ascending 倒的排序
左边是0 上边是1

print(df.sort_values(by='B')) 单行值进行排序
数据筛选
![]() 一列中的数据
一列中的数据
标签
# select by label: loc
print(df.loc['20130102'])
print(df.loc[:,['A','B']])
print(df.loc['20130102', ['A','B']])
索引
# select by position: iloc
print(df.iloc[3])
print(df.iloc[3, 1])
print(df.iloc[3:5,0:2])
print(df.iloc[[1,2,4],[0,2]])
二者结合
# mixed selection: ix
print(df.ix[:3, ['A', 'C']])
判断筛选
print(df[df.A > 8])
数据丢失处理
丢掉 print(df.dropna(axis=0, how='any')) # how={'any', 'all'}
变0 print(df.fillna(value=0))
缺少返回Ture print(pd.isnull(df))
True至少丢失了一个数据 np.any(df.isnull())==True)
导入导出
# read from
data = pd.read_csv('student.csv')
print(data)
# save to
data.to_pickle('student.pickle')
合并
# concatenating
# ignore index
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2, columns=['a','b','c','d'])
res = pd.concat([df1, df2, df3], axis=0, ignore_index=True)
# join, ('inner', 'outer')
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'], index=[1,2,3])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['b','c','d', 'e'], index=[2,3,4])
res = pd.concat([df1, df2], axis=1, join='outer') 没有的NaN 默认
res = pd.concat([df1, df2], axis=1, join='inner') 删除没有的
# append
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['b','c','d', 'e'], index=[2,3,4])
res = df1.append(df2, ignore_index=True)
res = df1.append([df2, df3])
s1 = pd.Series([1,2,3,4], index=['a','b','c','d'])
res = df1.append(s1, ignore_index=True)
merge
# consider two keys
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'], key1为标题,字典后面的都是数据
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(left)
print(right)
res = pd.merge(left, right, on=['key1', 'key2'], how='inner') # default for how='inner'没有的删除 outer为NaN # how = ['left', 'right', 'outer', 'inner']
res = pd.merge(left, right, on=['key1', 'key2'], how='left') 上面都有多出来一行
print(res)
# indicator
df1 = pd.DataFrame({'col1':[0,1], 'col_left':['a','b']})
df2 = pd.DataFrame({'col1':[1,2,2],'col_right':[2,2,2]})
print(df1)
print(df2)
res = pd.merge(df1, df2, on='col1', how='outer', indicator=True) #显示怎么样合并的如right_only
# give the indicator a custom name
res = pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column')#自定义名字
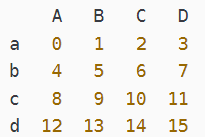
data.loc['a'] a行
data.iloc[0]
a列
data.loc[:,['A']]
data.iloc[:,[0]]
#ab AB
data.loc[['a','b'],['A','B']]
data.iloc[[0,1],[0,1]] #提取第0、1行,第0、1列中的数据
#所有数据
data.loc[:,:]
data.iloc[:,:]
#loc指定
data.loc[data['A']==0]