摘要
基于方面的情感分析(ABSA)主要涉及三个子任务:方面项提取、观点项提取和方面级情感分类,通常以单独或联合的方式处理。然而,以前的方法没有很好地利用三个子任务之间的交互关系,也没有有针对性地利用易于获得的文档级别标记为域/情感知识,这限制了它们的性能。然而,以前的方法没有很好地利用三个子任务之间的交互关系,也没有有针对性地利用易于获得的文档级别标记为域/情感知识,这限制了它们的性能。为了解决这些问题,我们提出了一种用于端到端ABSA的迭代多知识转移网络(IMKTN)。首先,通过ABSA子任务之间的交互关联,我们的IMKTN通过使用精心设计的路由算法,将任务特定知识从三个子任务中的任意两个子任务转移到令牌级别的另一个子任务,即三个子任务中的任意两个子任务将帮助第三个子任务。首先,通过ABSA子任务之间的交互关联,我们的IMKTN通过使用精心设计的路由算法,将任务特定知识从三个子任务中的任意两个子任务转移到令牌级别的另一个子任务,即三个子任务中的任意两个子任务将帮助第三个子任务。另一方面,我们的IMKTN有针对性地将文档级知识,即特定领域和情感相关知识,转移到方面级子任务,以进一步提高相应的性能。在三个基准数据集上的实验结果证明了该方法的有效性和优越性。
1介绍
基于方面的情感分析(ABSA)越来越受到社会的关注,它包括三个子任务:方面术语提取(AE)、意见术语提取(OE)和方面级情感分类(SC)。前两个子任务分别提取出现在一个句子中的方面术语和观点术语。SC子任务是判断提取出来的方面项的情感极性。
大多数现有研究通常单独处理每个任务(Tang等人,2016年;Wang等人,2016b;Hu等人,2019b),或将OE作为AE或SC的辅助任务(Wang等人,2017年;Li等人,2018b;He等人,2019年),其中这些单独的方法需要管道化或集成在一起以供实际使用。最近,一些研究指出,与单独的方法相比,联合方法可以实现有希望的性能,其中只有两个子任务是耦合的,例如(AE,OE) (AE,SC)。最近,Chen和Qian(2020)专注于建模互动关系,即双向AE↔OE,单向AE→SC和单向OE→SC用一个协作学习的框架,为了进一步增强这些子任务,由于方面级数据有限,一些研究人员寻求外部可访问的文档级语料库(包含特定领域/情感相关知识),作为一个更好的例子,他等人(2019)将文档级领域特定知识和情感相关知识合并在一起,以增强AE和SC子任务,这两种知识是没有差别的。尽管有效,但我们认为上述方法不足以对端到端ABSA任务产生令人满意的结果,因为1)它们仅耦合了两个子任务或没有建模三个子任务之间的所有双向交互关系(AE↔OE、AE↔SC和OE↔SC)和2)粗略使用文档级特定领域/情感相关知识,无法有效的发挥它们的优势。
首先,三个方面级子任务之间的交互关系是相互协作的。例如,在“The fish is verydelicious”这句话中,意见术语“delicious”表明,方面术语“鱼”的情绪极性为正,表明它们之间存在较强的互动关系。相反,鉴于方面术语“鱼”及其情绪极性为正,句子中的单词“美味”而不是其他单词(例如,“非常”)将很容易提取为意见术语。因此,三个方面级子任务之间的双向关系密切相关,并且它们可以增量地相互促进,如图1的左部分所示。
其次,应该有针对性地利用包含特定领域和情感相关知识的文档级语料库来增强ABSA的三个方面级子任务。事实上,大多数不同的领域具有不同的方面和观点术语(Peng等人,2018),而情感极性(即积极、消极和中性)通常是领域不变的。例如,方面术语“鱼”和观点术语“美味”反映了不同领域的特定特征,表明它们属于餐厅领域而不是笔记本电脑领域。相反,特定于领域的属性可以帮助区分这些方面和观点术语与其他领域或背景词(例如,“非常”)。因此,应该有针对性地利用特定领域的知识来帮助识别方面术语和意见术语,而不是判断情绪极性。 同时,情绪相关知识应以有利于SC子任务而不是AE和OE子任务为目标,如图1右侧所示。
因此,我们提出了一种迭代多知识转移网络(IMKTN),通过在ABSA任务的令牌级和文档级转移知识来充分利用交互关系。部分受胶囊网络通过特征聚类区分不同特征的优势启发(Sabour等人,2017),我们设计了一种新的路由算法,可以在三个方面级子任务之间相互传递任务特定知识,如图1左部分所示。此外,IMKTN采用更细粒度的方法,有针对性地将文档级知识传输到方面级子任务。来自领域分类子任务的知识仅用于AE和OE子任务,而来自文档级情感分类子任务的知识仅用于SC子任务。所有多知识转移过程都是迭代进行的,以充分利用所有任务中的知识来增强ABSA任务。
我们提出了一种用于ABSA任务的迭代多知识转移网络,该网络通过使用精心设计的路由算法,将任务特定知识从三个方面级子任务中的任意两个转移到第三个方面级子任务,从而很好地利用交互关系。
我们提出了一种更细粒度的方法来有针对性地传递文档级知识,以进一步增强方面级任务。
我们的方法3显著优于现有方法,并在三个基准数据集上取得了最新的结果,即SemEval14(Restaurant14和Laptop14)(Pontiki等人,2014)和SemEval15(Restaurant15)(Pontiki等人,2015)。
2任务定义
在本节中,我们制定了方面级任务和文档级任务,其中文档级任务被视为改进方面级任务的辅助任务。
方面级任务
接下来(Chen和Qian,2020),ABSA任务被制定为三个序列标记子任务。给定一个输入句子S={wi},有n个单词:对于方面提取子任务,我们的目标是推断一个目标级的句子,Yae ={yaei }, where yaei ∈ Yae = {BA, IA, O},代表方面的起始位置和终止位置和其他位置。对于目标提取子任务,Yoe = {yoei },where yoei ∈ Yoe = {BP, IP, O},对于情感分析子任务,Ysc = {ysci }ni=1, whereysci ∈ Ysc = {pos, neg, neu}。
文档级任务
这项工作包含两个文档级子任务:域分类(DDC)和情感分类(DSC)。对于具有m个句子的输入文档D={S1,S2,…,Sm},DDC和DSC旨在预测域标签Yddc∈ {笔记本电脑,餐厅}和情感标签Ydsc∈ Ysc。
3模型
IMKTN由四个部分组成,(1)共享编码器,用于提取n-gram特征;(2)任务特定层,用于捕获句子的表示,(3)方面级知识转移,包括三个路由块,用于在方面级子任务之间充分传输知识,以相互加强;(4)文档级知识转移,用于有针对性地将环形文档级知识转移到相应的方面级任务。最后,为下一次迭代聚合多源信息。
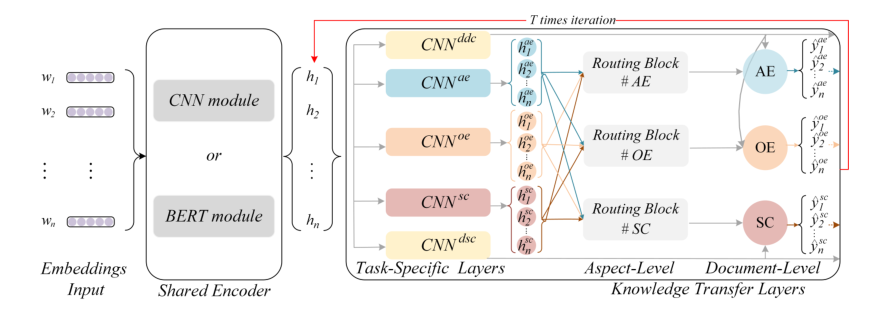
为了充分利用三个方面级子任务之间的任务间相关性进行相互促进,它们的知识通过“路由块”相互传递。此外,来自CNNddc的知识仅转移到AE和OE子任务。来自CNNdsc的知识仅传输到SC子任务。总之,所有多知识转移过程都是迭代进行的,以充分利用所有子任务中的知识来增强ABSA任务。
3.1共享编码器
我们使用两个模块来提取句子特征,我们采用CNN作为特征提取器和一个更强大的模型Bert作为骨干,编码器由三个方面级任务和两个文档级任务共享,以提供公共功能。
3.2任务特定层
基于共享编码器,我们设计了三个方面级别的任务特定层,旨在分别生成方面相关知识、观点相关知识和情感相关知识。两个文档级特定任务层,分别用于生成特定于领域的特征和情感特征。
3.3方面级情感知识转移
我们设计了一个方面级知识转移层,由三个路由块组成,以充分利用三个方面级子任务之间的任务间知识。
Routing Block(路由块)
路由块用于在方面级子任务之间传递知识,如图2的“路由块”部分所示。例如Routing Block #SC,它的内部结构如图3所示。AE和OE的知识通过我们的路由算法传输到SC以提高其性能。AE和OE的知识通过我们的路由算法传输到SC以提高其性能。在传统的路由算法(Sabour等人,2017年)中,高级胶囊位于预定义的固定数量中,例如类别的总数。在我们的任务中,高级胶囊是动态数字,数字由句子长度决定。为此,我们提出了一种新的路由算法,下面将对此进行详细阐述。

这种路由算法和胶囊网络原理相同,先初始化参数bj|i ,底层胶囊的输出uj|i表示将向量表示hioe与特殊设计的转换矩阵Wp相乘的结果,通过bj|i经过softmax计算底层胶囊和高层胶囊之间的耦合系数cj|i,高层胶囊的计算:cj|i*uj|i 得到sj,之后通过挤压函数得到输出,再根据第9行的式子更新bj|i,用于下一次高层胶囊的计算。因为高层胶囊的输出要与句子情感分析子任务的隐藏向量表示结合,因此需要计算的高层胶囊的个数是句子的长度。
我们以“从OE到SC的知识转移”为例,展示了算法1中的整个路由过程。具体而言,算法1的输入是OE(hoe)的表示和迭代的次数,bj|i代表OE中第i个token同意路由到SC中第j个token的表示的概率,他初始化的值为0.Wp是位置感知变换矩阵,通过添加位置编码实现。通过句子的长度算法能够确定动态胶囊的数量,uj|i表示将向量表示hioe与特殊设计的转换矩阵Wp相乘的结果。在每次迭代期间(第5行),通过应用softmax函数(第6行),获得低能级胶囊hioe和高能级胶囊v之间的耦合系数。然后,通过将所有意见向量以cj | i作为权重进行聚合,计算sj,并投票决定第j个标记的情感极性 .通过下面的公式将sj非线性缩放到0-1之间,一旦vj在当前迭代中更新,如果点积uj | i·voej较大,则概率bj | i变大(第9行)。也就是说,当ˆuj | i更类似于voej时,点积更大,这意味着它更有可能将这种观点知识路由到第j个标记,从而影响其情绪极性。因此,在下一次迭代中,较大的bj | i将导致第i个标记的意见知识与第j个标记的情感表示之间的较大一致值cj | i。相反,当ˆuj | i和voej之间没有相关性时,它会生成较低的cj | i。iter循环迭代后,通过路由过程学习的一致性值确保意见知识将发送到适当的情感表示。

同样,我们获得了从AE转移到SC的知识vjae,这表明哪个标记应该正确标记情感极性。然后,来自AE和OE子任务的知识组合如下:

通过上述过程,完成了“路由块#SC”中的多知识转移,这决定了SC中每个令牌的情感极性。同样,我们在图2中的“路由块#OE”和“路由块#AE”中实现了多知识转移。通过这样做,三个方面级子任务相互交互,以充分利用任务间的相关性。
3.4文档级知识转移
我们设计了以下两种方法来有针对性地将文档级知识转移到相应的方面级任务。我们将特定领域的知识从DDC子任务转移到AE和OE子任务:t代表迭代的次数

我们将情感相关知识从DSC子任务转移到SC子任务,
 ais(t) (s ∈{ddc, dsc})是文档级任务的权重,
ais(t) (s ∈{ddc, dsc})是文档级任务的权重,

文档表示形式的计算公式为
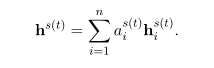
然后,应用具有softmax功能的全连接层将hs(t)映射到ˆys(t)。
总的来说,IMKTN可以通过路由算法充分执行知识转移,并通过这样的T轮迭代有针对性地合并文档级知识以增强相应的方面级任务。
3.5模型训练
对于训练,我们使用交叉熵函数最小化方面级任务的每个标记和文档级任务的每个实例的损失。方面级损失函数编写如下:

文档级损失函数:

为了训练整个模型,我们首先通过几个epoch的文档级任务训练网络,以便为方面级任务生成合理的特征。然后,我们在方面级和文档级语料库上交替训练网络,以尽量减少相应的损失。
4实验
4.1实验设置
数据集 我们结合两个带有领域标签的数据集进行领域分类,由于领域特定的属性,在训练D1和D3数据集时使用Yelp数据集,在D2数据集时使用Amazon数据集。
实施细节 为了公平比较,我们使用与比较模型相同的设置训练模型(陈和钱,2020)。我们在每个验证集上调整迭代数T和路由数iter。附录A和B中给出了更多的实现和调优细节。
评估指标 接下来(陈和钱,2020),应用四个指标进行评估,并在所有实验中报告了5次随机初始化的平均分数。我们使用F1ae、F1 oe和F1 sc来表示每个子任务的F1分数。我们使用表示为F1 absa的F1分数来测量完整absa,4其中仅当跨度和情绪都正确时,提取的方面项才被视为正确。
4.2对比模型
为了验证我们提出的模型在ABSA任务上的性能,我们使用以下方法进行了对比实验:
流水线模型 SPAN-BERT AE:CMLA DECNN SC:TNet,TCap
联合模型 MNN INABSA
级联模型 DOER SPAN-base DREGCN IMN RACL
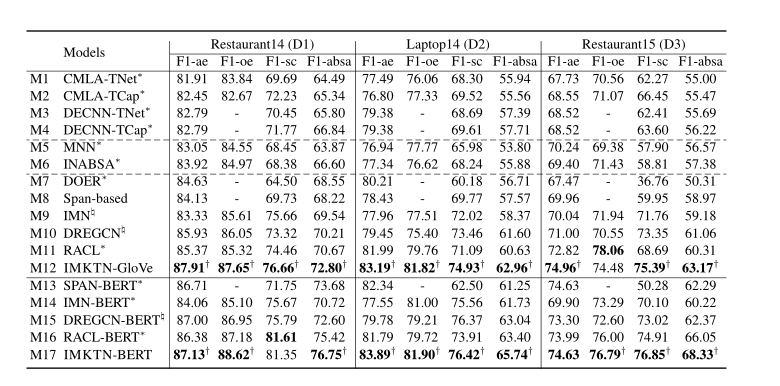
4.3实验结果
5分析和结论
5.1三个方面级子任务是否互相促进?
5.2有针对性的转移文档级知识是否更有助于方面级子任务
结果表明,有针对性地转移文档级知识更有助于方面级子任务,这与我们的直觉一致,即领域特定知识更倾向于促进AE和OE子任务,而情感相关知识倾向于改善SC子任务。因此,一种细粒度的方法对于增强ABSA是非常必要的。
5.3消融实验
我们得出的结论是:(1)一旦删除任何方面级子任务知识转移(第0行)∼2) ,在这两种设置下(即,GloVe和bertlagle),三个基准数据集的分数都会下降,这表明三个方面级别的子任务在语义上高度相关,因此可以增量地相互促进。(2) 我们还观察到,当删除文档级知识时,尤其是当删除DSC子任务时,明显下降,这表明有针对性地传输文档级知识显著有益于相应的方面级任务(第3行)∼4).

5.4为什么使用胶囊网络?
在我们的初步实验中,我们进行了一些实验来研究如何在不同任务之间有效地传递知识。结果显示在选项卡中。6,其中胶囊网络(第3行)表现最佳。原因是相邻层中的胶囊通过动态路由连接,能够通过特征聚类区分不同的特征(Sabour等人,2017)。这与我们的动机相吻合,即通过双向交互关系将相关特征从两个子任务转移到第三个子任务,以实现相互促进(特征聚类)。但是,其他方法(第0行∼2) 没有这样的动态路由机制,因此无法动态进行特征提取和聚类,导致结果不理想。因此,我们选择了胶囊网络。

5.5案例研究和可视化
为了理解多知识转移的工作原理,在图4,6中,我们以从OE和AE到SC的知识转移为例,可视化协议值cj | i。图4(a)和图4(c)是从OE到SC的知识转移情况。图4(a)显示了来自OE子任务的意见词“更长”的知识主要发送到SC子任务的方面词“电池”,图4(c)显示了相同的现象(来自OE子任务的意见词“不可怕”的知识主要发送到方面词“价格”),尽管它是一个否定句,表明意见词影响体项的情感极性,即前者(AE)与后者(SC)自然相关。特别是,在图4(c)中,否定信息可以通过路由算法有效地转移到方面术语“价格”,并影响其情感极性。图4(b)和图4(d)是将知识从AE转移到SC的情况,表明方面相关知识主要转移到方面术语“电池”和“价格”,支持它们成为方面项。因此,AE子任务可以帮助方面级情感分类判断单词是否应该具有情感极性。此外,我们还在附录C中提供了全面的误差分析。
6相关工作
现有模型通常独立或联合处理ABSA任务。显然,单独处理每个子任务无法利用任务间的相关性,导致性能受限。相比之下,综合或联合方法可以模拟交互相关性,从而获得有希望的结果。与上述研究不同,我们侧重于利用三个方面级子任务之间的任务间相关性,从而逐步促进彼此。此外,我们观察任务特征,然后使用文档级语料库有针对性地帮助相应的方面级子任务。
Capsule网络(Sabour等人,2017)已广泛应用于许多自然语言处理任务。在ABSA中,王等人(2019)专注于构建多个用于方面类别情感分析的胶囊,这些胶囊不采用路由过程。陈和钱(2019)构建了一个传输胶囊网络,用于通过共享编码器将语义知识从DSC传输到SC,该网络仅将vanilla胶囊网络用于SC子任务。Du等人(2019)将胶囊网络与交互注意相结合,为SC子任务的给定方面术语和上下文之间的交互关系建模。姜等(2019)发布了一个新的大规模多方面多情感数据集,并使用胶囊网络构建了一个强大的基线。与这些方法不同的是,我们关注端到端的ABSA任务而不是单个子任务,并提出了一种动态长度到动态长度的路由算法,该算法可以有效地执行多知识转移。
7结论
在本文中,我们提出了一种用于ABSA任务的迭代多知识转移网络,该网络可以利用所提出的路由算法充分利用三个方面级子任务之间的任务间相关性。此外,我们设计了一种更细粒度的方法,使我们的模型能够结合文档级知识,从而有针对性地增强相应的方面级任务。在三个基准数据集上的实验结果证明了我们提出的方法的有效性,该方法在大多数指标上都具有最先进的性能。