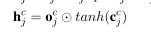论文使用了Lattice结构LSTM模型应用于命名实体识别,模型对一系列输入字符以及所有与词典匹配的潜在单词进行编码,与基于字符的方法相比,我们的模型显式地利用了单词和单词序列信息。与基于词的方法相比,lattice LSTM不存在分割错误。模型利用显式单词进行字符序列标记,不会出现分割错误。
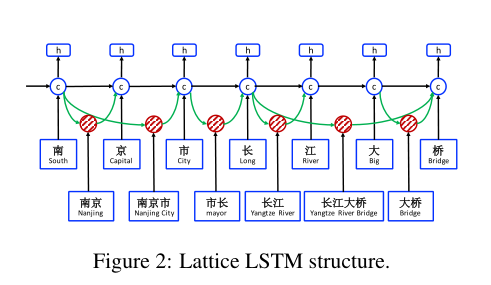
模型的结构是LSTM+CRF,主要的创新点是在字符编码中融入了单词的编码,对于一个句子在词典中去匹配它所包含的单词,在句子输入进LSTM的过程中,对于当前字符,融合以该字符结束的所有的单词的信息,将字符的向量表示输入进LSTM单元,将所有的单词的向量表示也输入进LSTM单元,最终将单词的向量表示和字符的向量表示以一定的权重进行结合。
字符的编码
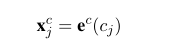
如果没有以当前字符结束的单词,就将这个向量输入进LSTM,得到其输出的向量表示
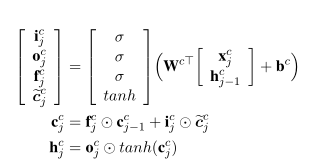
如果存在以当前字符结束的单词,将这个单词的向量表示也输入进LSTM,将单词的编码与单词起始字符b的隐藏向量进行拼接,得到记忆细胞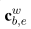
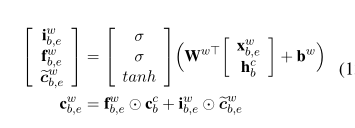
这个时候,字符的输入门的信息就要结合单词的信息,将原来计算记忆细胞的式子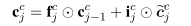 变成了以下这个式子,上面得到的,是单词的编码于单词其实字符编码的结合,它也作为输入,输入进下边这个式子。
变成了以下这个式子,上面得到的,是单词的编码于单词其实字符编码的结合,它也作为输入,输入进下边这个式子。
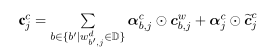
这个里面的α是注意力系数,计算单词编码和字符编码各自的权重,根据单词和字符的输入门向量经过归一化得到,其中单词的输入门信息最开始只结合了起始字符的信息,现在让他结合最后一个字符的信息,计算的公式如下:
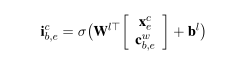
有了单词和字符的输入向量,下面计算注意力系数:
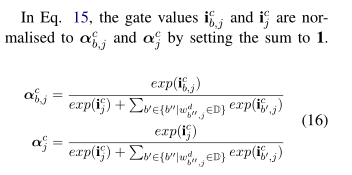
隐藏向量的公式还是根据之前的公式进行计算: