摘要
本文将方向项提取和方向情感分类作为序列标注任务,重点研究方向项提取和方向情感分类中很少涉及的不平衡问题。此外,以往的研究在标注极性时往往忽略了方面项之间的相互作用。我们提出了一种梯度协调级联标记模型(GRACE)来解决这些问题。具体而言,开发了一个级联标记模块,以增强方面术语之间的交换,并在标记情绪极性时提高情感词的关注度。句子中方面项情感极性的标注取决于生成的方面项标注序列。为了缓解不平衡问题,我们通过动态调整每个标签的权重,将用于目标检测的梯度协调机制扩展到基于方面的情感分析。GRACE模型将BERT作为它的主干,实验结果表明,该模型在多个基准数据集上实现了一致性改进,并产生了最先进的结果。
1Introduction
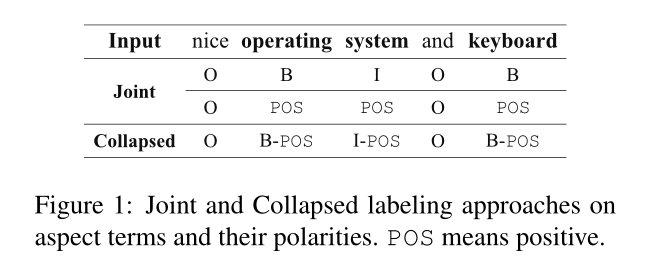
在基于方面的情绪分析(ABSA)中,方面术语提取(ATE)和方面情绪分类(ASC)是两个基本的细粒度子任务。ATE的任务是提取表达意见的实体的方面术语(或属性),ASC的任务是识别意见文本中这些提取术语表达的极性(胡和刘,2004)。考虑图1中的例子,其中包含人们对“操作系统”和“键盘”这两个方面术语的注释,它们的极性都是正的。
为了更好地满足实际应用,同时解决ATE和ASC的方面术语极性共提取近年来备受关注(Li等人,2019b;Luo等人,2019b;Hu等人,2019;Wan等人,2020)。在一个统一的模型中,方面术语极性共同提取的一个巨大挑战是ATE和ASC属于不同的任务:ATE通常是一个序列标记任务,而ASC通常是一个分类任务。以前的工作通常将ASC任务转换为序列标记。因此,ATE和ASC具有相同的配方。
在体项极性共提取上有两种序列标记方法。如图1所示,一种是 joint approach,另一种是collapsed approach。前一种方法使用两种不同的标记集联合标记每个句子:方面术语标记和极性标记。接下来的一个使用collapsed approach标签作为标签集,例如“B-POS”和“I-POS”,其中每个标签都表示纵横比术语边界及其极性。除了联合和折叠方法外,流水线方法首先使用方面术语标签标记给定的句子,例如,“B”和“I”(方面术语的开头和内部),然后将方面术语输入分类器以获得其相应的极性。
在这些方法中已经发表了一些相关的工作。Mitchell等人(2013年)和Zhang等人(2015年)发现,在命名实体及其情感共同提取方面, joint approach和collapsed approach方法优于流水线方法。Li等人(2019b)提出了一个统一的模型,采用collapsed approach方法进行方面术语极性的共提取。Hu等人(2019年)采用流水线方法解决了这项任务。Luo等人(2019b)采用了联合 joint approach方法来进行这种共提取。我们遵循本文中的联合方法,并相信通过学习并行序列标签,它比collapsed approach的方法具有更明显的责任。
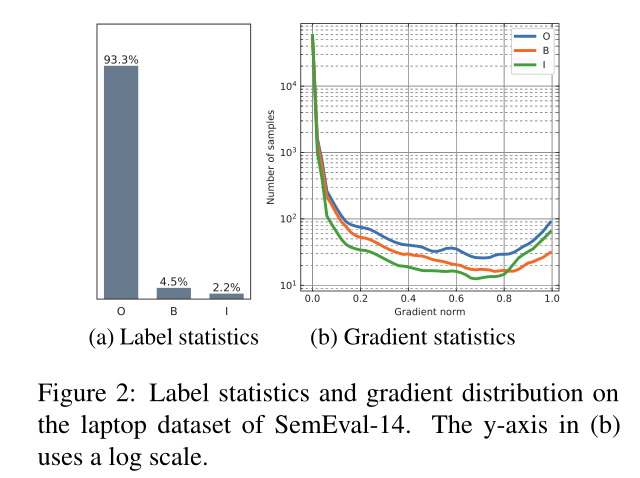
然而,以前关于joint approach方法的工作在标记极性时通常忽略了方面术语之间的相互作用。这种相互作用有助于确定极性。例如,在图1中,如果“操作系统”是正数,“键盘”应该是正数,因为这两个方面的术语通过协调连词“和”连接起来。此外,几乎所有以前的工作都不关注这种序列标记任务中标签的不平衡性。如图2a所示,“O”标签的数量远大于“B”和“I”标签的数量,后者往往主导训练损失。此外,我们在序列标记任务中发现了与Li等人(2019a)相同的梯度现象。如图2b所示,大多数标签都有较低的梯度,这对全局梯度有显著影响,因为它们的数量很大。
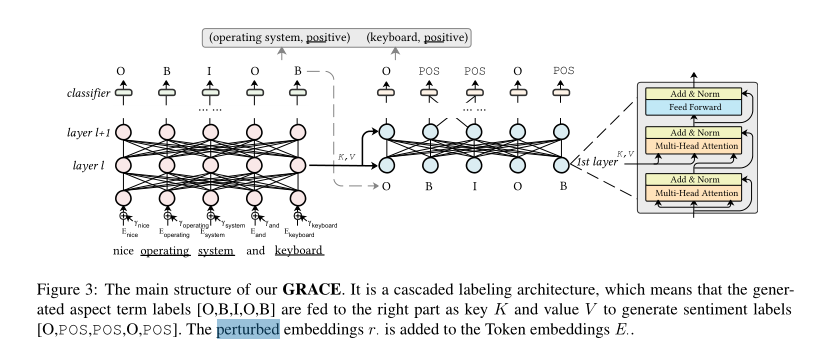
考虑到上述问题,本文提出了一种梯度协调级联标记模型(GRACE),如图3所示。与以前的工作不同,GRACE是一个级联标记模型,它再一个一致的框架中用生成的方面项标签去编码方面项极性标签,具体来说,我们使用两个与较低层共享的编码器模块来提取表示。一个编码器模块用于ATE,另一个在给出前一个编码器生成的方面术语标签之后用于ASC。因此,GRACE可以通过多头注意力机制在进行ASC任务时考虑不同方面项之间的关系,此外,我们在模型训练阶段扩展了梯度协调损失来解决不平衡标签问题。
创新点:
提出了一种新的框架GRACE,以端到端的方式解决方面项极性共提取问题。它采用级联标签的方法来考虑标签之间的相互作用时,标记他们的情感标签。
考虑了标签的不平衡问题,并扩展了梯度协调策略来缓解这一问题。我们还使用虚拟对抗训练和域数据集上的后训练来提高协同抽取性能。
在下文中,我们将在第2节中描述拟议的框架。实验在第3节中进行,然后是第4节中的相关工作。最后,我们在第五部分对论文进行总结。
2 模型
GRACE的概述如图3所示。它由两个共享浅层的模块组成:一个用于ATE,另一个用于ASC。我们将首先阐述共提取问题,然后在本节中详细描述该框架。
2.1 问题陈述
本文讨论了体项极性共抽取,其中体项在文本中被明确提及。我们将其分解为两个序列标记任务。形式上,给定一个句子S,其中包含来自特定领域的n个单词,用S={wi | i=1,…,n}表示。对于每个单词wi,我们的任务目标是分配一个标记 和一个标记
和一个标记 其中
其中 并且
并且
2.2 GRACE梯度协调和级联标记模型
本文重点讨论了联合标记方法。如图3所示,GRACE包含两个共享浅层的分支。为了从预训练模型中获益,我们使用BERT作为主干。然后,可以在预训练的BERT上生成ATE的表示H:
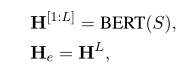
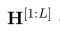 表示BERT每一层的表示,L代表BERT模型的最大层数12,
表示BERT每一层的表示,L代表BERT模型的最大层数12,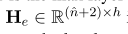 代表BERT最后一层的表示,n代表句子分词之后的长度,2代表CLS和SEP的token值,这两个token在ATE标签中记为O,不同层次的BERT捕获不同层次的信息,例如较低层的短语级信息和中间层的语言信息(Jawahar等,2019)。较高层通常与任务相关。因此,在ATE和ASC任务之间共享BERT是正确的选择。我们从BERT的第l层提取ASC任务的表示Hc:
代表BERT最后一层的表示,n代表句子分词之后的长度,2代表CLS和SEP的token值,这两个token在ATE标签中记为O,不同层次的BERT捕获不同层次的信息,例如较低层的短语级信息和中间层的语言信息(Jawahar等,2019)。较高层通常与任务相关。因此,在ATE和ASC任务之间共享BERT是正确的选择。我们从BERT的第l层提取ASC任务的表示Hc:
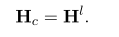
因此,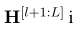 是为ATE任务特定的,当l=L时,所有的层被两个任务共享。
是为ATE任务特定的,当l=L时,所有的层被两个任务共享。
Cascaded Labeling(级联标签)
我们可以直接对He和Hc进行序列标记。然而,它不是针对ASC的定制特性。相反,ASC可能会降低A TE的性能。一个原因是A TE和ASC之间的区别。方面术语的极性通常不是来自术语本身。例如,图1中方面术语“操作系统”的极性来自形容词“nice”。当给“操作系统”贴上标签时,模型需要指出“好”。另一个原因是在标注方面术语的情感标签时,忽略了方面术语之间的交互作用。例如,“操作系统”和“键盘”是通过协调连接“和”来连接的。如果“操作系统”是正的,“键盘”也应该是正的。
因此,我们提出了级联标记方法,将生成的方面项序列作为输入来生成情感序列。如图3所示,将Hc作为键K和值V馈送到一个新的Transformer-Decoder (V aswani et al., 2017),生成一个新的方面情感表示Gc

Q代表ATE模型产生的方面项标签,transformer-Decoder的词嵌入词表大小是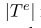
注意这里的变压器解码器与原来的变压器解码器不同。不同的是,我们使用多头注意而不是蒙面多头注意作为第一子层,因为ASC不是一个自回归任务,不需要每次预测一个元素的输出序列。
Gradient Harmonized Loss(梯度协调损失)
使用交叉熵损失函数训练模型
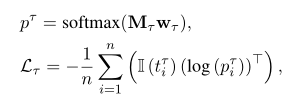
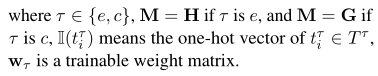
然后,将两个任务的损失构造为整个模型的联合损失:

然而,有两个众所周知的不协调通过上述损失的优化影响性能。一是正负例子之间的不平衡,二是简单例子与困难例子之间的不平衡(Li et al., 2019a)。具体来说,在我们的标注任务中,每个标注之间存在着不平衡。如图2a所示,标签“O”比其他标签占用的速率大得多。根据Li等(2019a)的工作,标签的易属性和难属性可以用梯度g的范数表示:

t代表每个标签的真实值0或1,p代表softmax预测的输出值,L代表交叉熵,z代表模型的logit输出。
图2b显示了标签w.r.t梯度范数g的统计情况。大多数标签都有较低的梯度,由于其数量较多,对全局梯度的影响较大。一个策略就是从这些标签上减少损失的权重。我们将损失函数的式子改写为GHM-C,它用于对象检测(Li et al., 2019a),如下所示

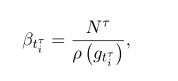
式中,gtτi为根据式(8)计算的tτi的梯度模,Nτ是标签的总数,ρ(g)为梯度密度:
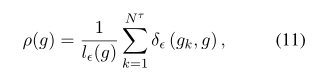
Virtual Adversarial Training(虚拟对抗训练)
为了使模型对对抗噪声具有更强的鲁棒性,我们利用(Miyato et al., 2016)中使用的虚拟对抗训练(V A T),在训练模型时对输入的令牌嵌入E进行小扰动r。额外损失如下:
Consistent Polarity Label(一致的极性标签)
将情感分类作为极性序列标记时,产生的序列标记并不总是一致的。例如,极性标签可能是“POS NEG”,表示方面术语“操作系统”。为了解决这一问题,我们设计了一种在同一方面术语中表示令牌的策略。ASC的生成的序列标签,我们首先获得方面的边界条件根据标签的意义,例如,标签的边界“O B I O B”在图3是{(1、2),(2、4),(2、4),(4、5),(5、6)},元素(绑定,eind)意味着开始索引(包容)和结束索引(独家)。然后进行方面情感表示Gc,分类计算如下:
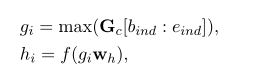
max代表最大池化操作,f代表RELU激活函数
3 实验
3.1数据集
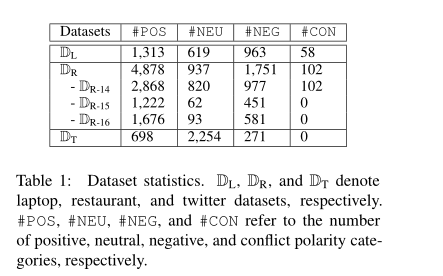
我们在三个基准情绪分析数据集上评估了所提出的模型,其中两个来自SemEval挑战,最后一个来自英语Twitter数据集,如表1所示。DL包含了来自SemEval 2014 (Pontiki et al., 2014)的笔记本电脑评论,而DR则是来自SemEval 2014 (DR-14)、SemEval 2015 (DR-15) (Pontiki et al., 2015)和SemEval 2016 (DR-16) (Pontiki et al., 2016)的餐厅评论。我们将这些数据集的官方数据划分为训练集、验证集和测试集。DL和DR的报告结果为5次跑的平均分数。DT由英文tweets组成。由于缺乏标准的训练-测试分离,我们报告了DT的10倍交叉验证结果(Li等人,2019b;罗等人,2019b)。评价指标为基于方面项及其极性的精确匹配的精度(P)、召回率(R)和F1得分。
3.2 Post-training
领域知识被证明对于特定领域的任务是有用的(Xu等人,2019;罗等人,2019b)。在本文中,我们采用亚马逊评论和Yelp评论,这两个分别是针对笔记本电脑和餐厅的域语料库,对我们的任务进行了未装箱BERT-Base的后培训。亚马逊评论数据集包含14280万条评论,Yelp评论数据集包含220万条餐馆评论。我们结合这两个评论数据集来完成我们的post-training工作。培训后的最大长度设置为320。BERT-Base的批量大小为4,096,具有梯度积累(每32步)。BERT-Base是在变压器库的基础上用Pytorch实现的。屏蔽策略是Whole Word Masking (WWM),与官方的BERT 相同。我们使用Adam优化器,将学习速率设置为5e-5,warm step为10%。
我们的预训练模型在8个NVIDIA Tesla V100 GPU上进行了10个epoch。我们使用fp16来加速训练和减少内存使用。培训前的过程需要5天以上。
3.5实验结果和分析
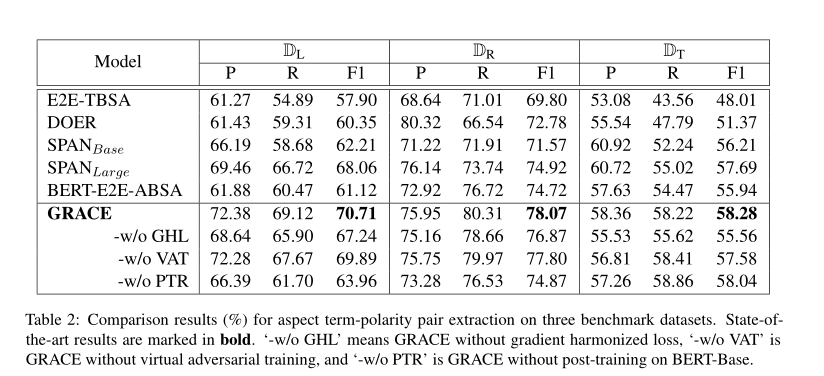
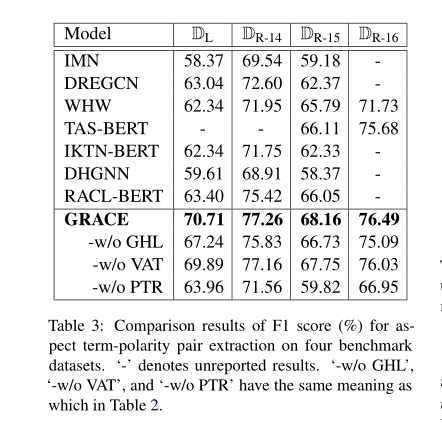
为了研究梯度协调损耗(梯度协调损耗,GHL)、V A T和训练前后消融的效果,我们分别进行了消融实验。结果显示在表2和表3的第二部分。我们可以看到,在没有GHL的情况下,与没有VA t的情况下相比,分数下降的更严重。这表明GRACE比VAT更能从梯度协调损失中获益,缓解标签的不平衡问题对序列标注更重要。在所有的笔记本电脑和餐馆数据集上,没有训练后的分数下降最严重,这表明领域特定知识可以极大地提高任务相关的数据集。
5 结论
本文提出了一种新的框架GRACE,该框架可以同时解决aspect术语提取和aspect情感分类的问题。该框架采用级联标记的方法,通过多头注意结构增强方面术语之间的交互,提高情感令牌对每个术语的注意。此外,我们借鉴了物体检测的梯度协调方法,缓解了标注任务中标签的不平衡问题。为提高提取性能,引入了基于域数据集的虚拟对抗训练和后训练。在3个基准数据集上的实验结果验证了GRACE方法的有效性,表明GRACE方法在方向项-极性共提取方面的效果明显优于基线方法。