基于情境、实体和方面记忆的多实体方面情感分析
摘要
受产品评论中基于方面的情绪分析(ABSA)近期工作的启发,以及面对社交媒体平台上提到多个实体和多个方面的更复杂帖子,我们定义了一项新任务,称为基于多实体方面的情绪分析(ME-ABSA)。本任务旨在对(实体、方面)组合进行细粒度情绪分析,使经过充分研究的ABSA任务成为其特例。为了解决这一问题,我们提出了一种创新的方法,称为CEA方法,对上下文记忆、实体记忆和方面记忆进行建模。我们的实验结果表明,在ME-ABSA和ABSA任务的数据集上,我们的CEA方法在多个基线(包括用于ABSA任务的最新方法及其增强版本)上取得了显著的增益。深入分析表明,对于一些难以预测的职位类型,CEA方法比基线方法具有显著优势。此外,我们还表明,CEA方法能够推广到新的(实体、方面)组合,且精度损失很小。这一观察结果表明,实际应用中的数据注释可以大大简化。
介绍
挖掘海量在线社交媒体文本可以洞察消费者需求及其产品体验,帮助生产商改进产品。情绪分析是提取消费者对品牌、产品以及相关方面态度的有用工具。
与产品或服务相关的在线帖子可分为两类。首先是产品评论,比如亚马逊和Yelp上的评论。这些帖子是关于特定产品或服务的某些方面。在某些情况下,一个帖子针对的是一个实体:产品或服务本身。第二类是分享经验的帖子,比如Twitter上的帖子或婴儿护理论坛上的帖子。在大多数情况下,帖子中提到的实体和方面的数量是可变的。例如,“试过帮宝适。没有发现渗漏,但他的屁股变红了。然后我换了Kao。它有点贵,但不致过敏。”
在这篇文章中,有两个实体:帮宝适和Kao(两个纸尿裤品牌),以及三个方面:防渗漏、抗过敏和价格。
近年来,对产品评论的情绪分析引起了广泛关注。应用最广泛的技术之一是基于方面的情绪分析(简称ABSA,也称为方面级情绪分析。给定文本和目标方面,ABSA的目标是找到针对每个特定方面的情感极性。例如,考虑到“食物很好,但太贵了”在“食物”和“价格”方面,ABSA将给出结果(食物,正面),(价格,负面)。
然而,ABSA不直接适用于经验共享岗位,其中提到的实体数量可能会有所不同。因此,我们定义了基于多实体方面的情绪分析任务(ME-ABSA)来模拟这种情况:给定实体以及文本1中提到的方面,目标是预测每个(实体,方面)组合的情绪极性。在Pampers Kao的例子中,我们将预测对6个(实体,方面)组合的情绪,因为有2个实体和3个方面。显然,ABSA是ME-ABSA的一个特例,实体的数量仅限于一个。
ME-ABSA是一项具有挑战性的任务。有三个主要挑战:
方面情绪匹配:提取方面情绪是ABSA和ME-ABSA任务面临的基本挑战。在Pampers Kao的例子中,“稍微贵一点”指的是(价格,负面),而“不再过敏”指的是(抗过敏,正面)。
实体方面情绪匹配:将正确的方面和情绪匹配到正确的实体是一项挑战,尤其是当一篇文章中有多个实体、多个方面和多个情绪极性时。在Pampers Kao的例子中,对相同方面的抗过敏情绪对Pampers是负面的,但对Kao是正面的。
不匹配:这主要与中立职位有关。在Pampers Kao的例子中,我们无法将(防泄漏、正)与Kao相匹配。在防泄漏方面,Kao应保持中立。
在本文中,我们介绍了一种创新的方法来完成这项任务。我们使用一个交互层,一个位置注意层和一个注意力机制LSTM层建立上下文记忆。交互层接受字向量、实体向量和方面向量作为输入,并执行元素级乘法和级联,以融合实体、方面和上下文信息。位置注意层旨在利用实体和方面的位置信息。带有注意的LSTM层将输入作为向量转换为上下文记忆。然后,我们用上下文记忆迭代地更新实体记忆和方面记忆,因此在这一步之后,我们得到情感以及上下文实体和方面表示。最后,我们使用线性层和softmax层预测给定(实体、方面)组合的情绪极性。
实验表明,我们的方法优于几个基线,包括ABSA任务的最新技术,以及它们在ME-ABSA任务数据集上的增强版本。为了验证我们方法的有效性,我们还对ME-ABSA的特例:ABSA任务进行了比较。在所有三个ABSA基准数据集上,我们的方法都优于最先进的方法。在深入分析中,我们验证了每个组件的有效性,并进一步将数据分为七种类型,并在几种难以预测的类型中展示了我们的方法的显著优势。我们还对新的和罕见的(实体、方面)组合进行了实验,表明了该方法的能力以及在实际应用中减轻数据注释负担的潜力。
本文的贡献包括:
我们定义了多实体基于方面的情绪分析(ME-ABSA)任务,该任务适用于针对(实体,方面)组合的细粒度情绪分析,使基于方面的情绪分析(ABSA)成为ME-ABSA的一个特例,实体数量限制为一个。
我们建议为ME-ABSA任务建模上下文、实体和方面记忆。实验表明,在MEABSA数据集、ABSA数据集和ME-ABSA数据集中难以预测的帖子类型方面,CEA方法优于基线方法。
我们发布了我们的数据集,期待着推进细粒度情绪分析的研究。
相关工作
基于方面的情绪分析,简称ABSA,是情绪分析(Liu 2012)中的一个子领域,主要关注细粒度情绪信息。解决ABSA问题主要有两种方法。第一种是使用词汇和规则的传统方法。(胡和刘2004)总结了所有情感词的情感分数。(丁、刘和于2008)提出了一种基于词汇的整体方法,同时考虑了显性和隐性观点。通过使用树核方法(Nguyen和Shirai 2015a)识别Aspectopine关系,进一步改进了该方法。第二种是机器学习方法。(Ramesh et al.2015)利用铰链损失马尔可夫随机场来解决MOOC中的方面情绪问题。(Wang和Ester 2014)提出了一个情绪一致的主题模型,用于产品方面评级预测。
(Kiritchenko et al.2014)将基于词典的方法和基于特征的SVM相结合,在SemEval 14比赛中首次检测对方面类别的情绪。(Nguyen and Shirai 2015b)构建了目标依赖的二元短语依赖树来构建方面的表示。(Tang等人,2016)用递归神经网络解决了这个问题,并提出了两种方法TD-LSTM和TC-LSTM。(Wang等人,2016)提出了一种基于注意力的LSTM方法。在那些只处理抽象语境记忆的人中,它是最好的方法。(Tang、Qin和Liu 2016)介绍了一种基于深度内存网络的方法来解决ABSA任务,并实现了最先进的性能。
实体情感检测是情感分析的另一个子领域。(Moilanen和Pulman,2009)提出了一个实体级情绪建模框架。这表明,组合情感分析可以产生有效的结果。(Deng和Wiebe 2015)使用概率软逻辑模型进行实体\事件级情绪分析。(Mitchell等人,2013)将实体情感检测建模为序列标记问题。(Li和Lu 2017)介绍了情绪作用域的概念,并提出了能够学习情绪作用域以联合预测命名实体及其相关情绪的方法。
婴儿护理数据集
在本节中,我们将介绍ME-ABSA任务的数据集。我们的数据集主要是关于婴儿护理(BC),包括尿布、奶粉、疾病等主题。我们收集了www.babytree.com上的帖子,中国最大的婴儿护理论坛之一。我们实验中的实体包括类别名称(如奶粉、尿布)、品牌名称和产品名称。母婴行业的专业人士列出了实体和方面。
三位以英语为母语的人被邀请对帖子中提到的情感标签和所有组合(实体、方面)进行注释。两周的时间,包括交叉检查的时间,将给予这些母语为英语的人对数据进行注释。我们提供用于模型训练的训练集BC Train、用于参数调整的验证集BC Dev和用于评估的测试集BC test。表1列出了我们数据集的统计数据。

对于细粒度评估,我们还为每个帖子提供了七种类型的标签。例如 代表一个实体,多个方面和一个情感极性,E代表实体,A代表方面,S代表极性。
代表一个实体,多个方面和一个情感极性,E代表实体,A代表方面,S代表极性。
值得注意的是,由于用户更喜欢在论坛上推荐产品,而不是批评产品,所以正面样本的数量多于负面样本。我们的数据集中中性样本的百分比超过三分之一。中性样本的高百分比不同于某些情绪分析数据集。这主要是因为在这项任务中,如果没有对文本中提到的(实体、方面)组合表达态度,情绪是中性的。
CEA方法
架构概述
我们的方法对上下文、实体和方面记忆进行建模,称为CEA方法。这里的记忆指的是抽象的、可重现的和可修改的表现。CEA方法由3个模块组成:上下文记忆编码、实体和方面记忆更新和情感预测。图1给出了该体系结构的说明。

上下文记忆编码
编码上下文记忆的目的是在给定实体和方面信息的情况下获得上下文的良好表示。该模块接受单词向量、实体向量和方面向量作为输入,分别对单词向量、实体向量和方面向量之间的交互进行建模,选择性地关注给定位置信息的重要信息,将输出反馈给LSTM层,并使用注意机制计算上下文记忆。
模块输入
上下文编码器模块的输入包含三个部分:post中每个单词的预训练单词向量wi、实体向量ve和方面向量va。如果实体(方面)是单个单词,则ve(va)由实体(方面)的单词向量初始化,否则,通过平均实体(方面)中每个单词的单词向量来计算。例如,“大脑发展”的方面向量是“大脑”的词向量和“发展”的词向量的平均值。
Interaction layer A(交互层A)
交互层的目的是在编码上下文记忆时考虑实体和方面信息。有三种选择:
1.没有互动

2.拼接

3.相乘再拼接

我们认为第三种方法比前两种要好,先将wi于方面和实体向量分别相乘,再进行拼接。
Position attention layer(定位注意力层)
基于这样一种观点,即对实体和方面的情感更可能通过它们附近的词语来表达。该模型关注每个单词,注意值基于实体的注意函数ge和方面注意力函数的ga。两个事实使功能更加复杂:一个实体或方面可能在同一篇文章中多次被提及;位置可能未知。


pwi是句子中第i个单词的位置,pe是句子中实体的位置,pa是句子中方面的位置,pei是最接近第i个单词的实体项的位置,pai是距离第i个单词最近的方面项的位置,位置注意力层的输出是:

LSTM层
我们将位置注意层的输出反馈给长短时记忆网络(LSTM)(Hochreiter和Schmidhuber 1997)。LSTM是递归神经网络的一个强大变体,它能够处理任意长度的序列,并通过选通机制捕获长程依赖。LSTM输出i的隐藏状态{hi}∈ [1,N]。在输入进LSTM之前我们进行dropout操作,将LSTM的维数设置为单词的维数,以备将来使用。
Interaction layer B
与交互层A相同,只是将wi更改为hi。交互层B的输出为
Attention
我们使用注意机制来计算上下文记忆。注意力计算如下:
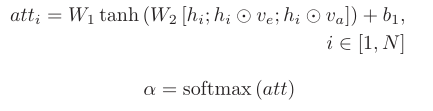
最后,上下文记忆c计算如下:

Entity and Aspect Memory Updating
更新实体和方面记忆的目的是将由单词向量初始化的原始实体和方面向量转换为包含情感和上下文信息的实体和方面记忆。
更新实体和方面向量。在这一步中,我们分别更新实体向量和方面向量。我们提供两种更新方法:
1.简单求和

2.加权求和

加权求和比简单求和更灵活,但同时增加了模型的复杂性。我们对这两种更新方法进行了实验,简单求和的准确率更高。
Multi-Hop for Updating.(多跳更新)人们普遍认为,具有多个层次的模型能够学习多个抽象层次(LeCun、Bengio和Hinton 2015)。(Tang、Qin和Liu 2016)表明,7-9层的深度记忆网络在ABSA任务中表现更好。在这项工作中,我们使用多跳学习实体和方面的抽象表示。一个新的跃点包含以下步骤:通过ve=ve'和va=va'、 计算交互层B,用注意更新上下文记忆,更新实体和方面记忆,判断是否满足停止条件。我们只是在实验中确定跳数。我们在参数调整过程中调整最大跳数。(意思就是多层的Interaction layer B,将之前经过Interaction layer B产生的上下文注意力向量与原来ve va产生的ve’和va‘ 赋值给ve和va,再经过Interaction layer B层进行迭代更新)
Sentiment Prediction
更新的实体和体记忆被认为是“语境中对实体和体的情感”的表征。我们将更新后的实体和方面记忆向量连接起来,并将其馈送到线性层,然后是softmax层,以预测情绪极性作为最终输出。请注意,我们在softmax之前执行了另一次dropout。
该方法的损失函数定义为交叉熵损失和l2正则化损失之和。
进行实验
我们描述了我们的实验方法、定量和定性结果,这些结果验证了我们的方法对ME-ABSA任务及其特例:ABSA任务的有效性。
实验装置
单词向量使用300维的Glove向量,使用jieba分词,LSTM隐藏层单元个数设置为300,我们用一批25个实例来训练模型10次迭代,L2正则化权重为0.001,Adam optimizer的学习率为0.001。LSTM和softmax之前的dropout率均设置为0.5。最大跳数设置为3。为了克服词汇表外(OOV)问题,我们使用随机词向量初始化OOV词,随机均匀范围为0.01到0.01。
我们的评估指标包括:准确性、精确性、召回率、f1分数:反映有效性,以及测试时间:评估效率。测试时间是指测试集上的运行时间。在配备tensorflow Framework 4的i7-16GB-GTX1070(GPU)计算机上进行BC测试时,所有方法的测试批量都设置为1000。我们只计算该方法的运行时间,不包括预处理、训练、将结果写入文件等常见部分的运行时间。
结果与分析
表2显示了两种方法在MEABSA任务上的比较结果。TAE-LSTM++的性能优于LSTM,这表明LSTM输入的实体和方面信息以及注意机制对于预测是有用的。DMN++比TAE-LSTM++更快,但较弱。我们认为这是因为引言部分提到了实体方面情绪匹配的挑战。DMN在基于方面的情感分析中,DMN主要通过注意更新实体和方面表示,忽略模型中的词序。这在ABSA任务中效果很好(DMN是ABSA任务的最新方法)。在ME-ABSA任务中,忽略词序会导致语境理解困难,并面临实体-方面-情感匹配挑战。TAELSM和DMN的精确度较低,表明在ME-ABSA任务中考虑实体信息很重要。OracleE的准确率很低,显示方面信息很重要,所有实体情感分类方法在ME-ABSA任务中的性能都不会超过我们的方法。我们的方法CEA在准确性和PRF方面明显优于基线方法。CEA更复杂,测试时间比第二好的方法AtalSTM++多50%,花费约3秒。
基于以下事实:a)LSTM、ATAE-LSTM++、DMN++的性能优于其他基线方法;b) ATAE-LSTM++是LSTM的增强版,它只更新上下文内存;DMN++只对实体和方面内存进行了内存更新,在接下来的测试集BC test上,我们只将我们的方法与AtalSTM++和DMN++进行了比较。
特殊情况下的表现:ABSA任务
为了进一步验证我们的方法的能力,我们使用基准数据集在ME-ABSA的特例:ABSA任务上对其进行了测试。我们在SemEval 2014任务45的数据集上进行了实验。这些数据集是顾客评论,一个来自餐馆领域,另一个来自笔记本电脑领域。这些数据集为每个域提供一个训练集和一个测试集。
在餐馆领域的数据集中,基于方面的情绪分析任务进一步分为方面术语情绪分析和方面层次情绪分析。前者提供上下文、上下文中提到的方面术语、方面术语的位置以及对方面术语的看法。后者提供语境、方面类别和对方面类别的情感。方面类别包括食品、价格、服务、氛围、轶事\/杂项。对于方面类别情感分类,在没有给出方面位置的情况下,我们在实验中去除了位置注意层。在笔记本电脑领域的数据集中,只有方面术语情绪分析任务。
在ME-ABSA和ABSA数据集中的优异结果验证了对上下文、实体和方面记忆建模的有效性。
深入分析
表4说明了修改我们方法的一个组成部分的准确性。它验证了某些组件的有效性,即修改任何组件都可能会损害精度。

Performance on Seven Post Types
我们使用基线方法对数据集部分介绍的七种数据类型进行评估,以展示方法的能力。表5显示了评估结果。一般来说,所有方法在具有多个实体的帖子上实现的性能都相对较低,这表明ME-ABSA任务面临挑战。
在所有post类型中,TAE-LSTM++的性能优于DMN,我们的方法的性能最好。对于E1A+S+、E+A1S1、E+A1S+和E+A+S+,TAE-LSTM和DMN的准确度均低于0.70,因此我们将其命名为“难以预测的后类型”。在这四种类型中,E1A+S+与介绍部分介绍的方面情绪挑战有关,而其他三种帖子类型都面临这三种挑战。在这些难以预测的帖子类型中,我们的方法明显优于基线方法。

Performance on New and Rare Combinations (在新的并且罕见的实体方面对组合表现的性能)
本节的动机如下。假设有m个实体,n个方面,对于每个(实体,方面)组合,模型平均需要k个实例才能学好。我们能不能喂少于M∗ N∗ k条数据,以减轻实际应用中数据标注的负担?由于很难给出理论证明,我们尝试了一种数据驱动的方法:我们验证新的并且罕见的(实体、方面)组合的准确性。
图2说明了测试集中有93条数据,它们的(实体、方面)组合没有出现在训练集中。它们是新的组合。CEA和TAE-LSTM++对新组合的准确度接近整个数据集的准确度。在罕见的组合中,由于罕见的实例数量很少,精度会发生波动。可以观察到,训练数据量与我们的CEA方法的性能之间没有明显的相关性。这是可取的,因为相关性越低,方法越好。为了进一步量化相关性,我们应用皮尔逊相关系数来衡量三种方法的绩效与训练数据量之间的相关性。对于我们的方法CEA,皮尔逊相关系数为0.047,ATAE-LSTM++为-0.077,DMN++为0.319。这表明DMN++比CEA和ATAELSTM++更缺乏训练数据。统计数据显示,CEA在新的和罕见的组合上有一个很好的结果,这表明没有必要注释所有可能的实体-方面组合。
结论
在本文中,我们定义了一个名为基于多实体方面的情绪分析(ME-ABSA)的新任务来研究细粒度情绪分析,使ABSA成为该任务的一个特例,其中实体的数量仅限于一个。我们提出了一种结合上下文、实体和方面记忆建模的方法。实验验证了该方法的有效性。在难以预测的职位类型上,该方法的表现明显优于基线方法。我们还展示了关于新的和罕见的(实体、方面)组合的有希望的结果,表明实际应用中的数据注释可以大大简化。在未来的工作中,我们将尝试在更新实体和方面内存时修改停止条件。我们预计,减少简单样本的跳数,增加困难样本的跳数,将提高效率和效率。