1.seq2seq模型有遗忘问题和对齐问题,attention在原来的seq2seq模型上做出了改进,在decoder编码阶段它的输入变为原来向量的加权求和,赋予每个向量不同的权重。
获取权重的方式:找一个向量q与输入句子的每个词的向量进行比较,如果两个向量相近则获得的权重比较高。
计算权重的方式:一种就是在预测t时刻的输出时,用decoder阶段上一时刻的输出作为q向量。另一种就是用ht作为q向量。可以将两个向量做内积,如果维数不同可以先让一个向量乘以一个矩阵,使两个向量维数相同再进行内积运算。还可以训练神经网络,进行计算。
attention模型中的编码阶段有一个前向的RNN和一个后向的RNN,将两个过程输出的向量进行结合,再decoder阶段,输入时encoder阶段不同时候输出向量的加权求和值。
2.self-attention(参考博客:https://blog.csdn.net/u012526436/article/details/86295971)
self-attention能够计算出一个句子中一个词与其他词之间的关联程度。
(1)首先,self-attention会计算出三个新的向量,在论文中,向量的维度是512维,我们把这三个向量分别称为Query、Key、Value,这三个向量是用embedding向量与一个矩阵相乘得到的结果,这个矩阵是随机初始化的.
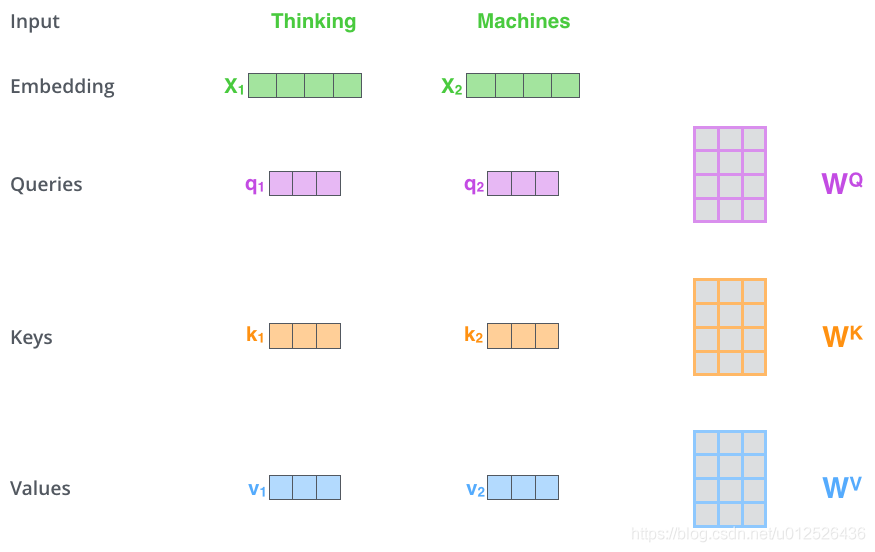
(2)
计算self-attention的分数值,该分数值决定了当我们在某个位置encode一个词时,对输入句子的其他部分的关注程度。这个分数值的计算方法是Query与Key做点成,以下图为例,首先我们需要针对Thinking这个词,计算出其他词对于该词的一个分数值,首先是针对于自己本身即q1·k1,然后是针对于第二个词即q1·k2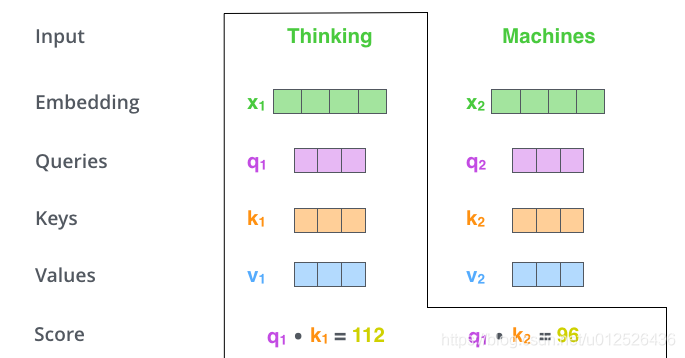
(3)接下来,把点成的结果除以一个常数,这里我们除以8,这个值一般是采用上文提到的矩阵的第一个维度的开方即64的开方8,当然也可以选择其他的值,然后把得到的结果做一个softmax的计算。得到的结果即是每个词对于当前位置的词的相关性大小,当然,当前位置的词相关性肯定会会很大
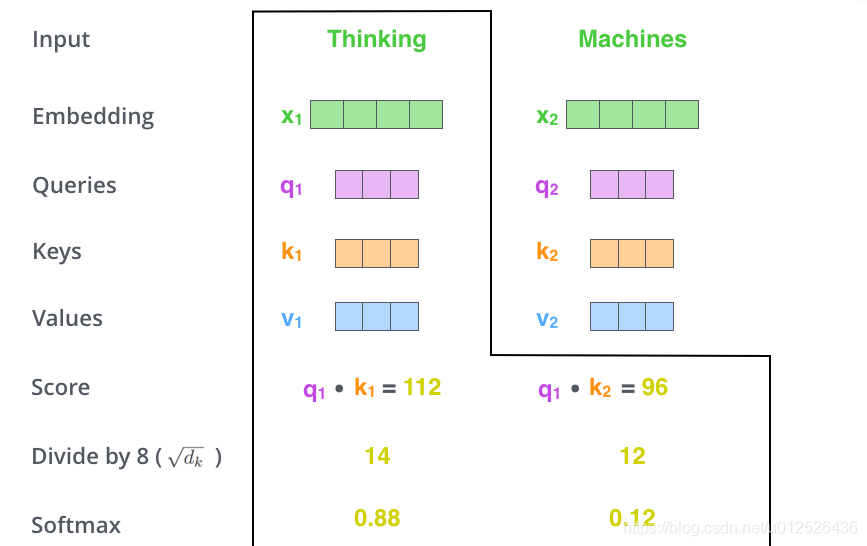
(4)下一步就是把Value和softmax得到的值进行相乘,并相加,得到的结果即是self-attetion在当前节点的值。
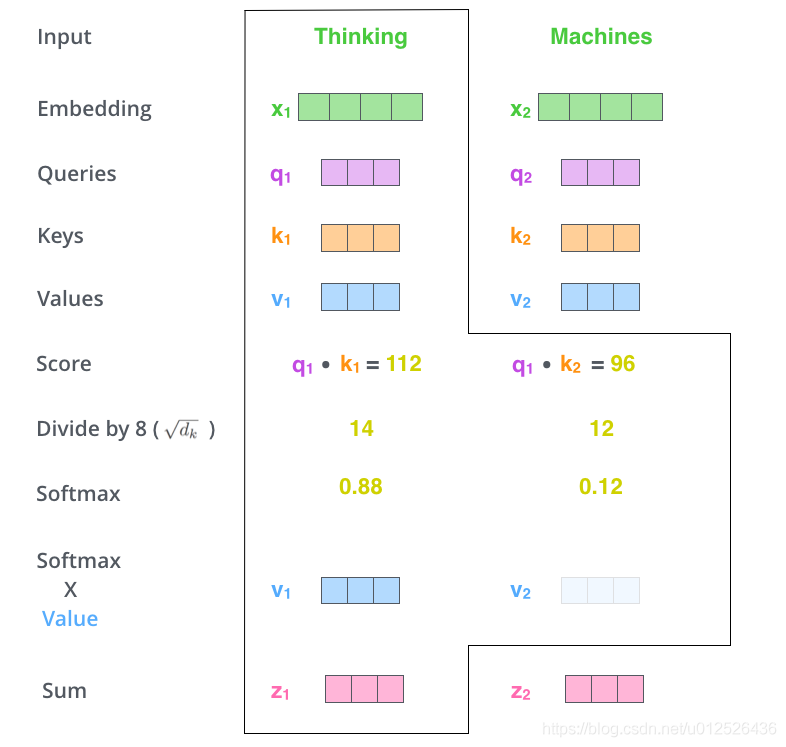
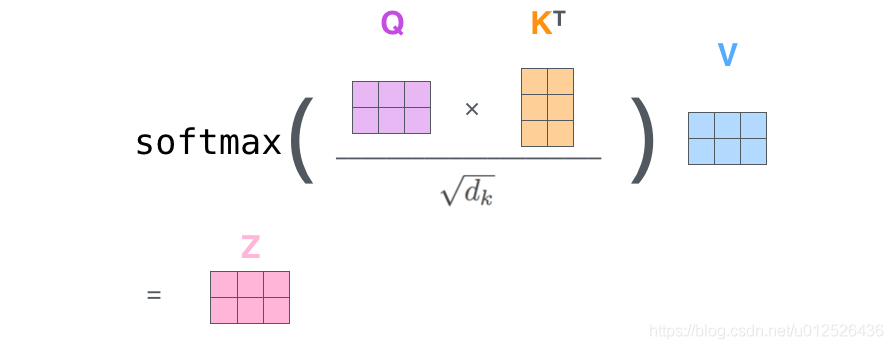
就是用一个词的Q向量和其他词的v向量相乘,进行归一化,获得这个词与其他词的近似程度,之后再成V向量,最后得到的维度和embedding的维度是相同的,这个时候得到的值不仅是这个词本身的信息,还根据这个词与其他词的关联程度获得了其他词的信息,进行了结合。