YOLOv3是YOLO (You Only Look Once)系列目标检测算法中的第三版,相比之前的算法,尤其是针对小目标,精度有显著提升。下面我们就来看看在算法中究竟有哪些提升。
首先如上图所示,在训练过程中对于每幅输入图像,YOLOv3会预测三个不同大小的3D tensor,对应着三个不同的scale。设计这三个scale的目的就是为了能够检测出不同大小的物体。在这里我们以13x13的tensor为例做一个简单讲解。对于这个scale,原始输入图像会被分成分割成13x13的grid cell,每个grid cell对应着3D tensor中的1x1x255这样一个长条形voxel。255这个数字来源于(3x(4+1+80)),其中的数字代表bounding box的坐标,物体识别度(objectness score),以及相对应的每个class的confidence,具体释义见上图。
其次,如果训练集中某一个ground truth对应的bounding box中心恰好落在了输入图像的某一个grid cell中(如图中的红色grid cell),那么这个grid cell就负责预测此物体的bounding box,于是这个grid cell所对应的objectness score就被赋予1,其余的grid cell则为0。此外,每个grid cell还被赋予3个不同大小的prior box。在学习过程中,这个grid cell会逐渐学会如何选择哪个大小的prior box,以及对这个prior box进行微调(即offset/coordinate)。但是grid cell是如何知道该选取哪个prior box呢?在这里作者定义了一个规则,即只选取与ground truth bounding box的IOU重合度最高的哪个prior box。
上面说了有三个预设的不同大小的prior box,但是这三个大小是怎么计算得来的呢?作者首先在训练前,提前将COCO数据集中的所有bbox使用K-means clustering分成9个类别,每3个类别对应一个scale,这样总共3个scale。这种关于box大小的先验信息极大地帮助网络准确的预测每个box的offset/coordinate,因为从直观上,大小合适的box将会使网络更快速精准地学习。
网络模型结构
下图是YOLOv3的网络模型结构图,此结构主要由75个卷基层构成,卷基层对于分析物体特征最为有效。由于没有使用全连接层,该网络可以对应任意大小的输入图像。此外,池化层也没有出现在YOLOv3当中,取而代之的是将卷基层的stride设为2来达到下采样的效果,同时将尺度不变特征传送到下一层。除此之外,YOLOv3中还使用了类似ResNet和FPN网络的结构,这两个结构对于提高检测精度也是大有裨益。有关这两项会在后面进行讲解。
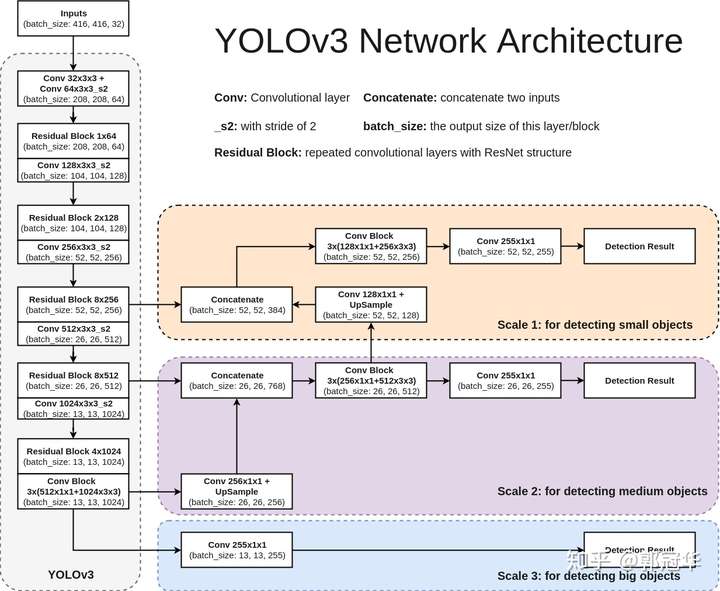
3 Scales:更好地对应不同大小的目标物体
通常一幅图像包含各种不同的物体,并且有大有小。比较理想的是一次就可以将所有大小的物体同时检测出来。因此,网络必须具备能够“看到”不同大小的物体的能力。并且网络越深,特征图就会越小,所以越往后小的物体也就越难检测出来。SSD中的做法是,在不同深度的feature map获得后,直接进行目标检测,这样小的物体会在相对较大的feature map中被检测出来,而大的物体会在相对较小的feature map被检测出来,从而达到对应不同scale的物体的目的。
然而在实际的feature map中,深度不同所对应的feature map包含的信息就不是绝对相同的。举例说明,随着网络深度的加深,浅层的feature map中主要包含低级的信息(物体边缘,颜色,初级位置信息等),深层的feature map中包含高等信息(例如物体的语义信息:狗,猫,汽车等等)。因此在不同级别的feature map中进行检测,听起来好像可以对应不同的scale,但是实际上精度并没有期待的那么高。
在YOLOv3中,这一点是通过采用FPN结构来提高对应多重scale的精度的。
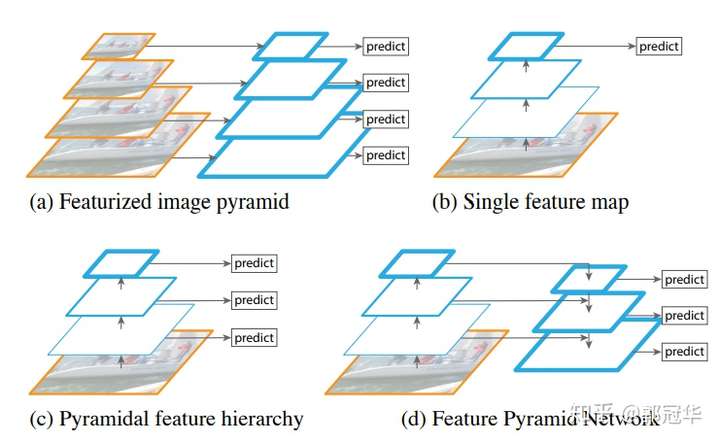 多重scale主流方法
多重scale主流方法
如下图所示,对于多重scale,目前主要有以下几种主流方法。
(a) 这种方法最直观。首先对于一幅图像建立图像金字塔,不同级别的金字塔图像被输入到对应的网络当中,用于不同scale物体的检测。但这样做的结果就是每个级别的金字塔都需要进行一次处理,速度很慢。
(b) 检测只在最后一个feature map阶段进行,这个结构无法检测不同大小的物体。
(c) 对不同深度的feature map分别进行目标检测。SSD中采用的便是这样的结构。每一个feature map获得的信息仅来源于之前的层,之后的层的特征信息无法获取并加以利用。
(d) 与(c)很接近,但有一点不同的是,当前层的feature map会对未来层的feature map进行上采样,并加以利用。这是一个有跨越性的设计。因为有了这样一个结构,当前的feature map就可以获得“未来”层的信息,这样的话低阶特征与高阶特征就有机融合起来了,提升检测精度。