常用的分组函数:
分组函数在计算时省略列中的空值
不能在where语句中使用分组函数
①:AVG/SUM:在数字类型数据使用AVG and SUM 函数
AVG:计算平均值
SUM:计算总和
②:COUNT(*)返回表中所有符合条件的记录数.
COUNT(字段) 返回所有符合条件并且字段值非空的记录
③:MAX/MIN:MIN and MAX适用于任何数据类型
MIN: 计算最小值
MAX:计算最大值
分组语句:
原表内容: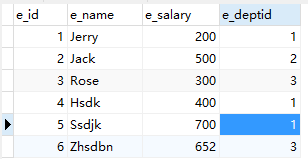
①:group by语法
SELECT column, group_function FROM table [WHERE condition] [GROUP BY group_by_expression] [ORDER BY column];
使用GROUP BY子句将表分成小组
组函数忽略空值,可以使用ifnull
结果集隐式按升序排列,如果需要改变排序方式可以使用Order by 子句
②:group by使用
#把工资小于300的过滤掉再分组
#把工资大于等于300的分组
SELECT e_name,e_id, e_salary FROM employee WHERE e_salary>=300 GROUP BY e_deptid
结果:
#把工资大于等于300的分组 并按照组平均工资的降序排序
SELECT *,AVG(e_salary) FROM employee WHERE e_salary>=300 GROUP BY e_deptid ORDER BY AVG(e_salary) DESC;
结果: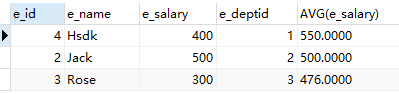
③:使用HAVING:
1,不能在 WHERE 子句中限制组.
2,限制组必须使用 HAVING 子句.
3,不能在 WHERE 子句中使用组函数.
#列出部门的平均工资大于250的部门
SELECT e_deptid,AVG(e_salary) FROM employee GROUP BY e_deptid HAVING AVG(e_salary)>250
结果:
分组函数执行流程:
在整个语句执行的过程中,最先执行的是From,然后是Where子句,在对表数据进行过滤后,符合条件的数据通过Group by进行分组,分组数据通过Having子句进行组函数过滤,最终的结果通过order by子句进行排序,排序的结果被返回给用户。
多表查询:(分为隐式连接和显式连接)
原表: employee 部门表 dept
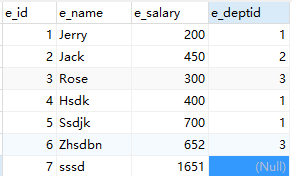
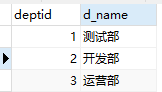
隐式查询
目的:进行多张表的联合查询
缺点:
1)会把表中的null的记录直接过滤,所以:隐式连接只能做内连接
#列举出所有的员工还有所在部门的名称
SELECT employee.e_id,employee.e_name,employee.e_salary,employee.e_deptid,dept.d_name FROM employee,dept WHERE employee.e_deptid=dept.deptid
结果: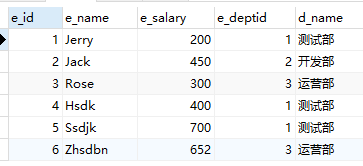
显式连接:可以理解为把隐式连接的条件从where挪到on里
分为内连接,外连接,自连接
如果想把一张表的信息包括null都查询出来则使用外连接,如果想把null信息忽略则使用内连接
隐式连接的问题在于:
1,需要在where条件中写连接条件,如果忘记写,代码不会出错,产生笛卡尔乘积;
2,隐式连接只能做内连接;
优化:
1)如果on后面有多个条件,并且这些条件中有连接条件和顾虑条件, 那么先写过滤条件后写连接条件,性能会有大的提升→有了JOIN就可以不写where了
2)尽量使用记录少的表连接记录相对较多的表
SELECT [表名1.列名1,表名1.列名2,表名1.列名3,表名2.列名1,表名2.列名2] FROM 表名1 , 表名2 WHERE 表名1.列=表名2.列
SELECT [表名1.列名1,表名1.列名2,表名1.列名3,表名2.列名1,表名2.列名2] FROM 表名1 JOIN 表名2 ON 表名1.列=表名2.列
,---> JOIN WHERE--->ON
#左连接:在连接生成的新表中,把JOIN关键字左边的表的记录全部显示出来
SELECT emp.e_id,emp.e_name,emp.e_salary,dept.d_name FROM employee AS emp LEFT JOIN dept ON emp.e_deptid=dept.deptid
结果: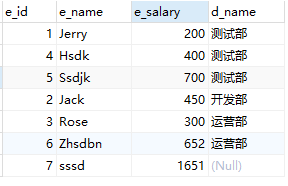
自连接:
场景1:
同一张表中的记录中, 存在多种身份的记录
如:班长和学生的关系, 部门经理和部门员工的关系
查询,某个班长管理哪些学生。
场景2:
同一个对象中包含两个同类型的对象,在同一张表中查询出三个表中的信息。
在查询语句中,一张表可以重复使用多次,完成多次连接的需要;
查询员工和其经理
原表: e_monitor相当于部门经理 由表得1,2为部门经理
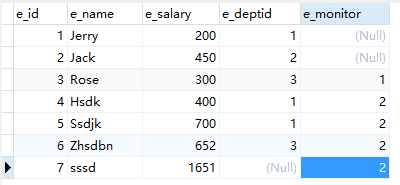
查询有经理管理的员工和其经理
SELECT emp.e_id '员工编号',emp.e_name '员工姓名',monitor.e_id'经理编号',monitor.e_name '经理姓名' FROM
employee emp JOIN employee monitor ON emp.e_monitor=monitor.e_id
结果: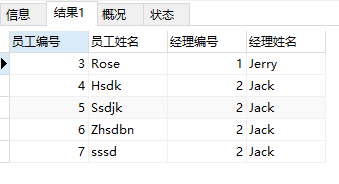
子查询:
在一个查询A的结果集中再次查询B, 那么A就叫做B的子查询
在使用select语句查询数据时,有时候会遇到这样的情况,在where查询条件中的限制条件不是一个确定的值,而是一个来自于另一个查询的结果。
SELECT select_list FROM table WHERE expr operator (SELECT select_list FROM table);
1、子查询在主查询前执行一次
2、主查询使用子查询的结果
##找出所有小于平均工资的员工
SELECT e_name , e_salary FROM employee WHERE e_salary<(SELECT AVG(e_salary) FROM employee)
结果: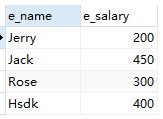
UNION/UNION ALL:(比如查询全校的学生信息)
JOIN是用于把表横向连接,UNION/UNION ALL是用于把表纵向连接
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
注意:
1,UNION 操作的表列数必须相同;
2,列也必须拥有相兼容的数据类型。
3,每条 SELECT 语句中的列的顺序必须对应。
4,UNION 结果集中的列名总是使用 UNION 中第一个 SELECT 语句中的列名
5,UNION 操作的表会把结果中重复的记录删除
UNION ALL则允许重复的值出现
# UNION:有去重功能 (SELECT * FROM t_employee) UNION (SELECT * FROM t_employee_bak); # UNION ALL简单的堆叠 (SELECT * FROM t_employee) UNION ALL (SELECT * FROM t_employee_bak);