
启动服务端,指定默认的存储的位置即可:
mongod -- dbpath F:/store #数据库默认的存储的位置
在启动一个“黑框框”, 当为客户端来连接启动的这个server
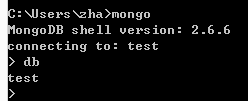
连接到mong server ,并且在service的黑框框中会显示,客户端的连接

下面就是mongo shell 对数据库的操作了
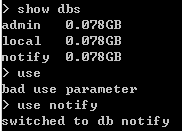


表示同一张表中,存储的数据并不是结构化的数据,能够带来很多的好处,但是也可能带来一定的混乱,所以针对
这个,mongdb的数据有一定 的设计的规范,后面可定会有涉及。
在说一下上面的命令,我们的使用命令 db.notify.insert({........});
When you insert the first document, the mongdb will
create both the notify database and the notify collection
(这里 数据库的名称 和 collection 的名称是一样的)
这里面的collection相当于 sql数据中的表,collection中包含的就是Document,下面是对document的说明:
MongoDB stores data in the form of documents, which are JSON-like
field and value pairs. Documents are analogous to structures in
programming languages that associate keys with values (e.g.
dictionaries, hashes, maps, and associative arrays). Formally, MongoDB
documents are BSON documents. BSON is a binary representation
of JSON with additional type information. In the documents, the
value of a field can be any of the BSON data types, including other
documents, arrays, and arrays of documents.
collection 和 Document 的关系如图所示:MongoDB stores all documents in collections. A
collection is a group of related documents that have a set of shared
common indexes. Collections are analogous to a table in relational
databases.

mongo 的查找: 也就是选择document 从单一的collection里面,就是从一张表中选择记录,符合SQL的思路。
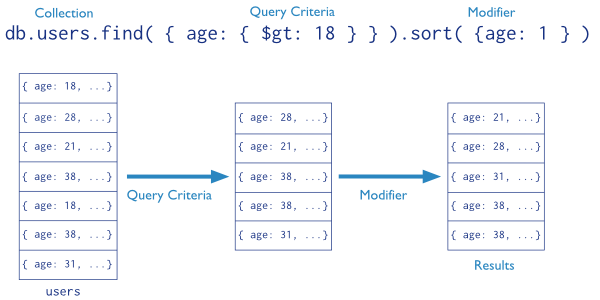
查找的过程 与SQL查找的对应的关系:

find 操作的说明:
索引:提高查找的速度
db.inventory.find( { type: typeValue } );
针对Collection inventory 的字段 type 建立索引。db.inventory.ensureIndex( { type: 1 } )
建立索引的语句是:db.collection.ensureIndex(keys, options)在这里我们可以通过:db.collection.find({。。。条件。。。}).explain();来看到输出的结果,分析读取的效率



只是简单的描述,感觉和Mysql的explain()比较的像。
聚合:(aggregation) : In addition to the basic queries, MongoDB provides several data
aggregation features. For example, MongoDB can return counts of the
number of documents that match a query, or return the number of
distinct values for a field, or process a collection of documents using
a versatile stage-based data processing pipeline or map-reduce
operations.