1、流程图:
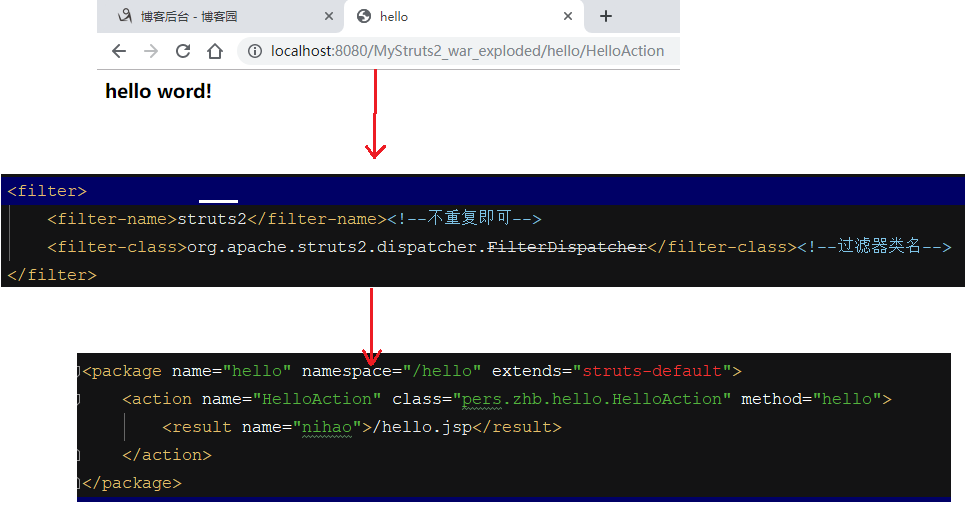
通过地址先经过过滤器,然后过滤器查看配置文件中的命名空间(package中的namespace)中是否有hello,再去action中的name属性中查找是否有HelloAction,
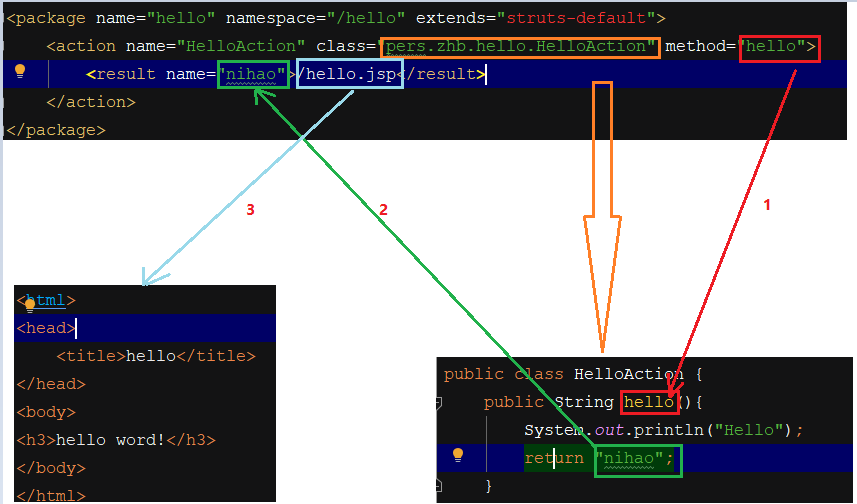
2、访问流程详解
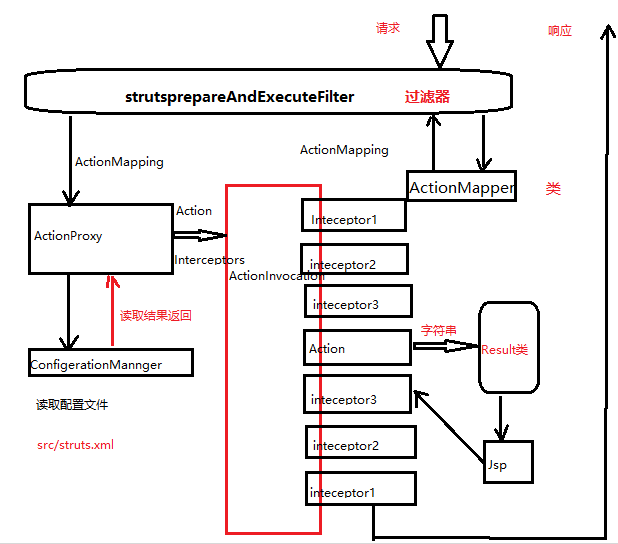
(1)首先,客户端发送请求,请求首先经过过一系列的滤器(这些过滤器中有一个叫ActionContextCleanUp的可选过滤器,这个过滤器对于Struts和其他框架的集成很有帮助)。
(2)接着FilterDispatcher(StrutsPrepareAndExecuteFilter)被调用,FilterDispatcher(StrutsPrepareAndExecuteFilter)询问ActionMapper来决定这个请求是否需要某一个Action。经过过滤器后需要经过ActionMapper类,该类将请求的信息处理好并封装为ActionMapping对象给过滤器。
(3)过滤器判断该请求是否需要Struts2处理。
(4)如果需要Struts2处理,则将ActionMapping转交给ActionProxy类。
(5)ActionProxy类通过ActionMannger读取配置文件,找到需要调用的Action类,并将结果返回给ActionProxy类。此时ActionProxy类既知道了要访问的目的地,又通过配置文件知道了要访问哪些包等信息。
(6)ActionProxy创建一个ActionInvocation实例,ActionProxy类将Action和Interceptors都转交给ActionInvocation。ActionInvocation实例使用命名模式来调用,在使用Action的过程前后,涉及到相关拦截器的调用
(7)一旦Action执行完毕,ActionInvocation负责根据struts.xml中的配置找到对应的返回结果,返回结果通常是(但不总是,也有可能是另一个Action链),一个需要被表示的jsp或者FreeMarker的模板,在表示的过程中可以使用Struts2框架中继承的标签,在这个过程中要涉及到ActionMapper
(8)一个inteceptor可以代表一个功能。