Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取所设计的, 也可以应用在获取API所返回的数据或者通用的网络爬虫。
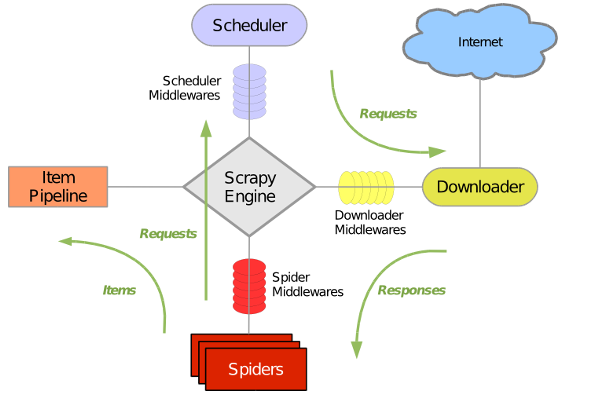
Scrapy原理图如下:
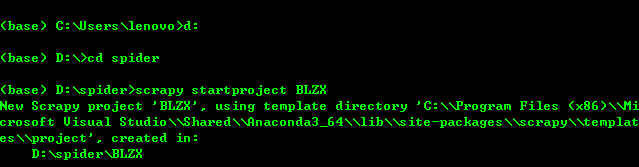
1、创建Scrapy项目:进入你需要创建scrapy项目的文件夹下,输入scrapy startproject BLZX(此处BLZX为爬虫项目名称)
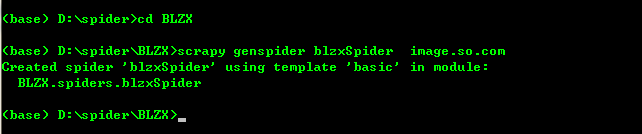
项目创建完成后出现一个scrapy框架自动给你生成的爬虫目录

2、进入创建好的项目当中创建spider爬虫文件blzxSpider:
cd BLZX
scrapy genspider blzxSpider image.so.com (其中image.so.com为爬取数据的链接)
到此我们的scrapy爬虫项目已经创建完成,目录如下:

创建好了blzxSpider爬虫文件后scrapy将会在改文件当中自动生成 如下代码,我们就可以在这个文件当中进行编写代码爬取数据了。
# -*- coding: utf-8 -*- import scrapy class BlzxspiderSpider(scrapy.Spider): name = 'blzxSpider' allowed_domains = ['image.so.com'] start_urls = ['http://image.so.com/'] def parse(self, response): pass
3、爬取360图片玩转的图片,此时我们需要编写blzxSpiser文件进行爬取360图片
代码如下
import scrapy import json class BoleSpider(scrapy.Spider): name = 'boleSpider' def start_requests(self): url = "https://image.so.com/zj?ch=photography&sn={}&listtype=new&temp=1" page = self.settings.get("MAX_PAGE") for i in range(int(page)+1): yield scrapy.Request(url=url.format(i*30)) def parse(self,response): photo_list = json.loads(response.text) for image in photo_list.get("list"): id = image["id"] url = image["qhimg_url"] title = image["group_title"] thumb = image["qhimg_thumb_url"] print(id,url,title,thumb)
抓取的结果为
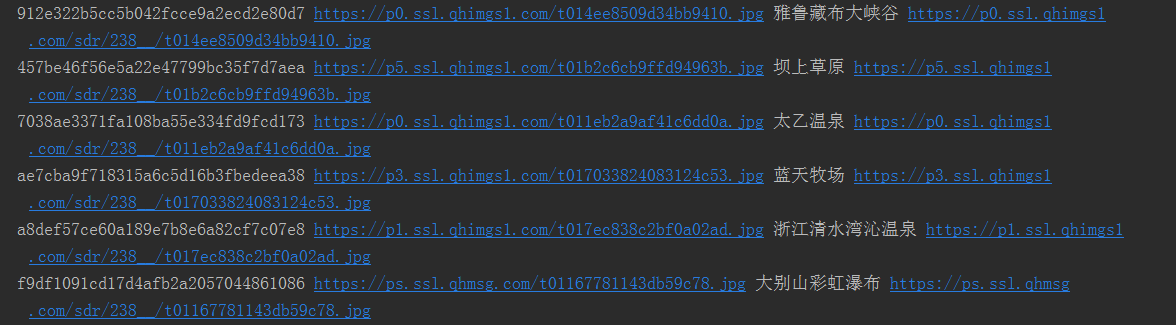
最后,我们已经将360图片的信息已经抓取下来了并打印在的控制台当中。但是我们需要把数据给下载下来,并且进行存储,所以在下一节当中会对item.py文件进行讲解。