一、ORM分组操作示例
总结:
1. 分组 ORM中values或者values_list 里面写什么字段,就相当于select 什么字段 ret = models.Employee.objects.all().values("dept", "age") 相当于: SELECT `employee`.`dept`, `employee`.`age` FROM `employee` LIMIT 21; args=() 2. ORM中 annotate 前面是什么就按照什么分组! from django.db.models import Avg ret = models.Employee.objects.values("province").annotate(a=Avg("salary")).values("province", "a") 相当于: SELECT `employee`.`province`, AVG(`employee`.`salary`) AS `a` FROM `employee` GROUP BY `employee`.`province` ORDER BY NULL LIMIT 21; args=() 3. extra --> 在执行ORM查询的时候执行额外的SQL语句 # 查询person表,判断每个人的工资是否大于2000 ret = models.Person.objects.all().extra( select={"gt": "salary > 2000"} ) 相当于: SELECT (salary > 2000) AS `gt`, `person`.`id`, `person`.`name`, `person`.`salary`, `person`.`dept_id` FROM `person` LIMIT 21; args=() 4. 直接执行原生的SQL语句,类似pymysql的用法 from django.db import connection cursor = connection.cursor() # 获取光标,等待执行SQL语句 cursor.execute("""SELECT * from person where id = %s""", [1]) row = cursor.fetchone() print(row)
单表操作
建表:
class Employee(models.Model): name = models.CharField(max_length=16) age = models.IntegerField() salary = models.IntegerField() province = models.CharField(max_length=32) dept = models.CharField(max_length=16) def __str__(self): return self.name class Meta: db_table = "employee"
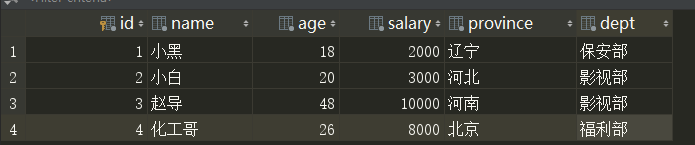
操作:
我们使用原生SQL语句,按照部分分组求平均工资:
select dept,AVG(salary) from employee group by dept;
ORM语句与SQL语句对应关系:
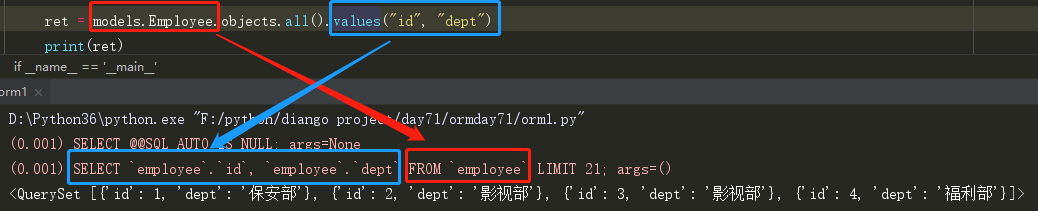
ORM查询:
ret = models.Employee.objects.all() print(ret)#<QuerySet [<Employee: 小黑>, <Employee: 小白>, <Employee: 赵导>, <Employee: 化工哥>]> #(0.003) SELECT `employee`.`id`, `employee`.`name`, `employee`.`age`, `employee`.`salary`, `employee`.`province`, `employee`.`dept`
FROM `employee` LIMIT 21; args=()
ret = models.Employee.objects.values("dept") print(ret) # (0.002) SELECT `employee`.`dept` FROM `employee` LIMIT 21; args = () # < QuerySet[{'dept': '保安部'}, {'dept': '影视部'}, {'dept': '影视部'}, {'dept': '福利部'}] >
ret = models.Employee.objects.values("dept").annotate(avg=Avg("salary")).values("dept","avg") print(ret) #(0.068) SELECT `employee`.`dept`, AVG(`employee`.`salary`) AS `avg` FROM `employee` GROUP BY `employee`.`dept` ORDER BY NULL LIMIT 21; #<QuerySet [{'dept': '保安部', 'avg': 2000.0}, {'dept': '影视部', 'avg': 6500.0}, {'dept': '福利部', 'avg': 8000.0}]>
多表操作
建表:
class Employee2(models.Model): name = models.CharField(max_length=16) age = models.IntegerField() salary = models.IntegerField() province = models.CharField(max_length=32) dept = models.ForeignKey(to="Dept") def __str__(self): return self.name class Meta: db_table = "employee2" class Dept(models.Model): name = models.CharField(max_length=16, unique=True) def __str__(self): return self.name class Meta: db_table = "dept2"
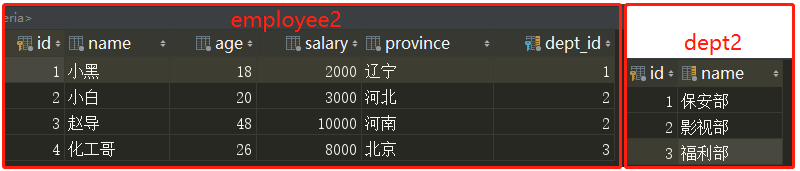
SQL查询:
select dept2.name,AVG(salary) from employee2 inner join dept2 on (employee2.dept_id=dept2.id) group by dept_id;
ORM查询:
from django.db.models import Avg ret = models.Employee2.objects.values("dept_id").annotate(avg=Avg("salary")).values("dept__name","avg") print(ret) # < QuerySet[{'dept__name': '保安部', 'avg': 2000.0}, {'dept__name': '影视部', 'avg': 6500.0}, {'dept__name': '福利部', 'avg': 8000.0}] > # (0.089) SELECT `dept2`.`name`,AVG(`employee2`.`salary`) AS `avg` FROM `employee2` INNER JOIN `dept2` ON(`employee2`.`dept_id` = `dept2`.id`)
GROUP BY `employee2`.`dept_id`,`dept2`.`name` ORDER BY NULL LIMIT 21;args = ()
# 查所有的员工和部门名称 ret = models.Employee2.objects.values("name", "dept__name") print(ret) #(0.012) SELECT `employee2`.`name`, `dept2`.`name` FROM `employee2` INNER JOIN `dept2` ON (`employee2`.`dept_id` = `dept2`.`id`) LIMIT 21; #<QuerySet [{'name': '小黑', 'dept__name': '保安部'}, {'name': '小白', 'dept__name': '影视部'}, {'name': '赵导', 'dept__name': '影视部'},
{'name': '化工哥', 'dept__name': '福利部'}]>
select_related 和 prefetch_related 的使用
def select_related(self, *fields) 性能相关:表之间进行join连表操作,一次性获取关联的数据。 总结: 1. select_related主要针一对一和多对一关系进行优化。 2. select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。 def prefetch_related(self, *lookups) 性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 总结: 1. 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。 2. prefetch_related()的优化方式是分别查询每个表,然后用Python处理他们之间的关系。
select_related的使用示例
#select_related的使用:表之间进行join连表操作,一次性获取关联的数据。 ret = models.Employee2.objects.select_related() print(ret) #(0.019) SELECT `employee2`.`id`, `employee2`.`name`, `employee2`.`age`, `employee2`.`salary`, `employee2`.`province`, `employee2`.`dept_id`,
`dept2`.`id`, `dept2`.`name` FROM `employee2` INNER JOIN `dept2` ON (`employee2`.`dept_id` = `dept2`.`id`) LIMIT 21; args=() #<QuerySet [<Employee2: 小黑>, <Employee2: 小白>, <Employee2: 赵导>, <Employee2: 化工哥>]> ret = models.Employee2.objects.select_related().values("name","dept__name") print(ret) #(0.020) SELECT `employee2`.`name`, `dept2`.`name` FROM `employee2` INNER JOIN `dept2` ON (`employee2`.`dept_id` = `dept2`.`id`) LIMIT 21; #<QuerySet [{'name': '小黑', 'dept__name': '保安部'}, {'name': '小白', 'dept__name': '影视部'}, {'name': '赵导', 'dept__name': '影视部'},
{'name': '化工哥', 'dept__name': '福利部'}]>
建立多对多关系表:
class Author(models.Model): name = models.CharField(max_length=32) books = models.ManyToManyField(to="Book") def __str__(self): return self.name class Meta: db_table = "author" class Book(models.Model): title = models.CharField(max_length=32) def __str__(self): return self.title class Meta: db_table = "book"

ret = models.Author.objects.select_related("books__title").values("name", "books__title") print(ret) #(0.014) SELECT `author`.`name`, `book`.`title` FROM `author` LEFT OUTER JOIN `author_books` ON (`author`.`id` = `author_books`.`author_id`)
LEFT OUTER JOIN `book` ON (`author_books`.`book_id` = `book`.`id`) LIMIT 21; args=() #<QuerySet [{'name': '小黑', 'books__title': '沙河出版社'}, {'name': '小白', 'books__title': '沙河出版社'}, {'name': '小黑',
'books__title': '光子出版社'}, {'name': '小黄', 'books__title': '光子出版社'}, {'name': '小黑', 'books__title': '番茄物语'},
{'name': '小白', 'books__title': '番茄物语'}, {'name': '小黄', 'books__title': '番茄物语'}]>
批量操作
def bulk_create(self, objs, batch_size=None): # 批量插入 # batch_size表示一次插入的个数 objs = [ models.DDD(name='r11'), models.DDD(name='r22') ] models.DDD.objects.bulk_create(objs, 10)
示例:
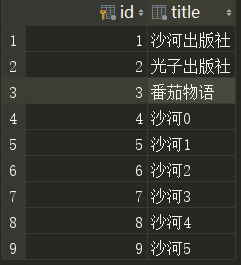
# 批量创建 # 有100个书籍对象 objs = [models.Book(title="沙河{}".format(i)) for i in range(6)] # # 在数据库中批量创建, 2次一提交 models.Book.objects.bulk_create(objs, 2)
二、基于对象查询(子查询)和queryset、双下划线的正反查询
models.py
from django.db import models # Create your models here. class Author(models.Model): nid = models.AutoField(primary_key=True) name=models.CharField( max_length=32) age=models.IntegerField() # 与AuthorDetail建立一对一的关系 authorDetail=models.OneToOneField(to="AuthorDetail",on_delete=models.CASCADE) class AuthorDetail(models.Model): nid = models.AutoField(primary_key=True) birthday=models.DateField() telephone=models.BigIntegerField() addr=models.CharField( max_length=64) class Publish(models.Model): nid = models.AutoField(primary_key=True) name=models.CharField( max_length=32) city=models.CharField( max_length=32) email=models.EmailField() class Book(models.Model): nid = models.AutoField(primary_key=True) title = models.CharField( max_length=32) publishDate=models.DateField() price=models.DecimalField(max_digits=5,decimal_places=2) # 与Publish建立一对多的关系,外键字段建立在多的一方 publish=models.ForeignKey(to="Publish",to_field="nid",on_delete=models.CASCADE) # 与Author表建立多对多的关系,ManyToManyField可以建在两个模型中的任意一个,自动创建第三张表 authors=models.ManyToManyField(to='Author',)
查询操作
from django.shortcuts import render,HttpResponse # Create your views here. from app01 import models def query(request): # #####################基于对象查询(子查询)############################## # 按字段(publish) # 一对多 book -----------------> publish # <---------------- # book_set.all() # 正向查询按字段: # 查询python这本书籍的出版社的邮箱 python=models.Book.objects.filter(title="python").first() print(python.publish.email) # 反向查询按 表名小写_set.all() # 苹果出版社出版的书籍名称 publish_obj=models.Publish.objects.filter(name="苹果出版社").first() for obj in publish_obj.book_set.all(): print(obj.title) # 按字段(authors.all()) # 多对多 book -----------------------> author # <---------------- # book_set.all() # 查询python作者的年龄 python = models.Book.objects.filter(title="python").first() for author in python.authors.all(): print(author.name ,author.age) # 查询alex出版过的书籍名称 alex=models.Author.objects.filter(name="alex").first() for book in alex.book_set.all(): print(book.title) # 按字段 authorDetail # 一对一 author -----------------------> authordetail # <---------------- # 按表名 author #查询alex的手机号 alex=models.Author.objects.filter(name='alex').first() print(alex.authorDetail.telephone) # 查询家在山东的作者名字 # 查询家在山东的第一个作者名字 ad1 = models.AuthorDetail.objects.filter(addr="shandong").first() print(ad1.author.name) #一对一关系体现在这里 # 查询家在山东的所有作者名字 ad_list=models.AuthorDetail.objects.filter(addr="shandong") for ad2 in ad_list: print(ad2.author.name) #一对一关系体现在这里 ''' 对应sql: select publish_id from Book where title="python" select email from Publish where nid = 1 ''' # #####################基于queryset和__查询(join查询)############################ # 正向查询:按字段 反向查询:表名小写 # 查询python这本书籍的出版社的邮箱 ret=models.Book.objects.filter(title="python").values("publish__email") print(ret.query) #把settings里的LOGGINE注释,然后加上 .query就是只打印这一句的sql语句 ''' select publish.email from Book left join Publish on book.publish_id=publish.nid where book.title="python" ''' # 苹果出版社出版的书籍名称 # 方式1: ret1=models.Publish.objects.filter(name="苹果出版社").values("book__title") print("111111111====>",ret1.query) #方式2: ret2=models.Book.objects.filter(publish__name="苹果出版社").values("title") print("2222222222====>", ret2.query) #查询alex的手机号 # 方式1: ret=models.Author.objects.filter(name="alex").values("authorDetail__telephone") # 方式2: models.AuthorDetail.objects.filter(author__name="alex").values("telephone") # 查询手机号以151开头的作者出版过的书籍名称以及书籍对应的出版社名称 ret=models.Book.objects.filter(authors__authorDetail__telephone__startswith="151").values('title',"publish__name") print(ret.query) # 查询过程,需要联5个表 # 以书籍为基表,过滤条件为手机号以151开头的,所以telephone__startswith="151"应该放在过滤条件的最后, # 然后由authorDetail表找telephone表,但是由Book表找不到authorDetail,所以由authors表再找authorDetail表,因为由Book表 # 可以找到authors,通过以上就把五个表连在一起了(4个表加一个多对多表),最后就可取出我们想要的东西 return HttpResponse("OK")