题目:
有以下员工信息表
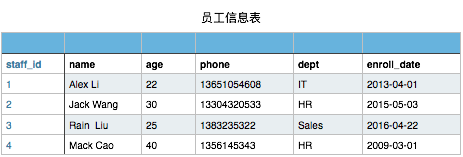
当然此表你在文件存储时可以这样表示
1,ZhangSan,9,13545255223,IT,2013-02-12
现需要对这个员工信息文件,实现增删改查操作
- 可进行模糊查询,语法至少支持下面3种:
- select name,age from staff_table where age > 22
- select * from staff_table where dept = "IT"
- select * from staff_table where enroll_date like "2013"
- 查到的信息,打印后,最后面还要显示查到的条数
- 可创建新员工纪录,以phone做唯一键,staff_id需自增
- 可删除指定员工信息纪录,输入员工id,即可删除
- 可修改员工信息,语法如下:
- UPDATE staff_table SET dept="Market" WHERE where dept = "IT"
注意:以上需求,要充分使用函数,请尽你的最大限度来减少重复代码!
流程图:
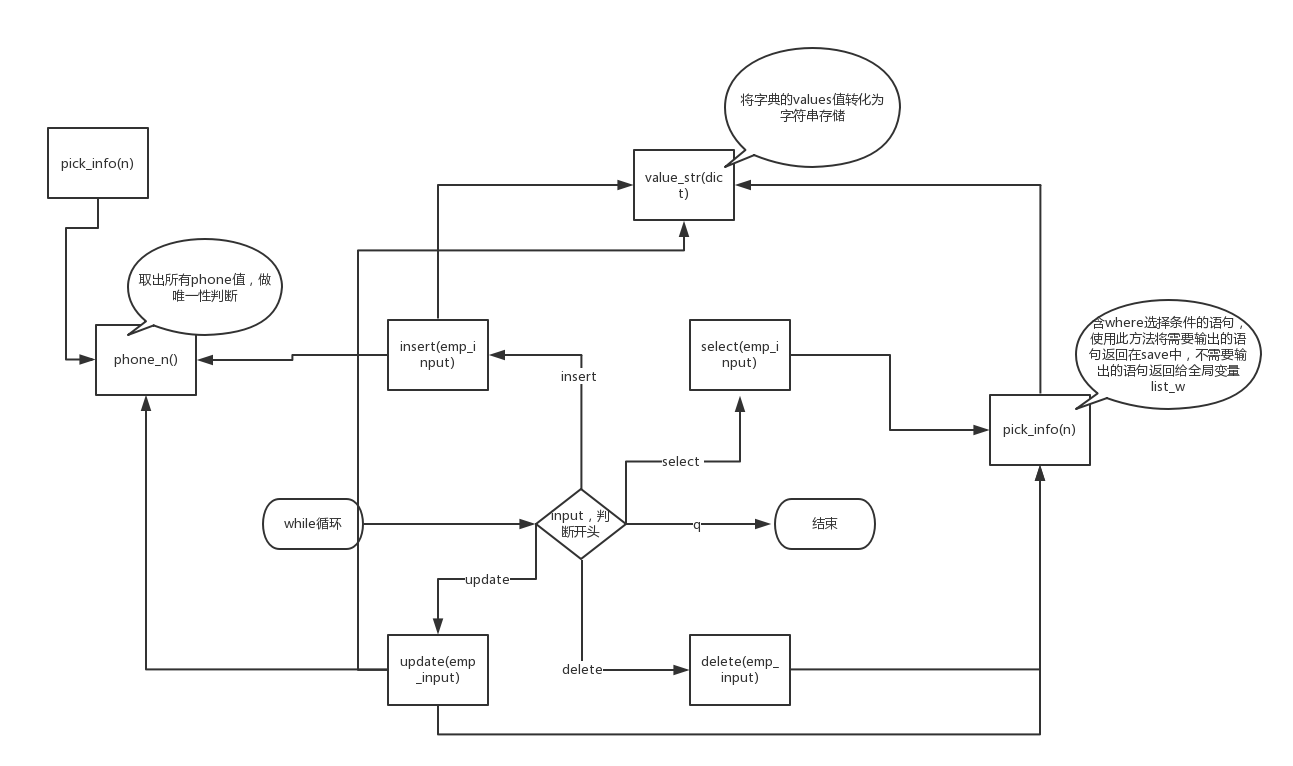
readme:
已有的信息
1,ZhangSan,9,13545255223,IT,2013-02-12
2,LiSi,12,18771135462,HR,2008-02-12
3,WangEr,29,15272829852,Salar,2008-02-12
4,ZhaoQi,36,13542677452,HR,2008-02-12
根据用户输入信息判断是否进入各个函数(兼容大小写)input
select(input):
需要select开头,含from
如:select name,age from staff_table where age < 22
SELECT * from staff_table where dept = "IT"
select * from staff_table where enroll_date like "2013"
a.查询字段可为任意个,where条件只能为>,<,=或者 like ,查询不区分大小写
b.查询字段,where条件 未做非存在字段的判断,会报错。无where会报错
update(input):
需要 update开头,含set
如: update staff_table set dept="Market" WHERE where dept = "IT"
a.where条件只能为>,<,=或者 like ,不区分大小写
b.set字段是phone,做了唯一性控制
c.set字段和where条件 未做非存在字段的判断,会报错。无where会报错
insert(input):
需要input开头,含into,values
如:INSERT INTO staff_table age,name values 13,zhuhuan
a.支持插入多字段,字段与值一一对应
b.插入字段对phone值做了唯一性控制
c.为对插入字段做非存在控制,字段名称不存在会报错。无where会报错
delete(input):
需要delete开头,含from
如:DELETE FROM staff_table WHERE age > 22
a.where条件只能为>,<,=或者 like ,不区分大小写
b.where条件 未做非存在字段的判断,会报错。无where会报错
其他:
pick_info(n):
作用:判断where后面的条件,将需要的值存入列表中返回,不需要的值存入全局变量list_w中。
被select,update,delete引用
value_str(dicts):
作用:将字典的values值转成字符串,用于写回文件中
被insert,update,pick_info()引用
phone_n():
作用:取出所有phone的values值,存入列表中返回,做唯一性判断。
顺带将文件中的字符串格式与字段一一匹配,生成字典,存入列表,传给全局变量list_kv。
被insert,update,pick_info()引用
#!/usr/bin/env python # -*-coding:utf-8-*- # _author_=zh #select * from STAFF_TABLE where age > 13 import os EMP_INFO_T=''' 1,ZhangSan,9,13545255223,IT,2013-02-12 2,LiSi,12,18771135462,HR,2008-02-12 3,WangEr,29,15272829852,Salar,2008-02-12 4,ZhaoQi,36,13542677452,HR,2008-02-12 ''' if not os.path.exists("info.txt"): with open("info.txt", "w", encoding="utf-8") as files: files.write(EMP_INFO_T) #取出文件中的值与DICT_KEY组成字典存入列表list_kv中,需要调用phone_n()方法 list_kv=[] def phone_n(): # function:取出所有phone值写入列表中返回,做唯一性判断 list_p=[] DICT_KEY = ["staffid", "name", "age", "phone", "dept", "enroll_date"] with open("info.txt","r",encoding="utf-8") as f: for line in f: if not line.strip(): continue dict_kv=dict(zip(DICT_KEY,line.strip().split(','))) list_kv.append(dict_kv) list_p.append(dict_kv["phone"]) return list_p def value_str(dicts): # function:将字典的values转成字符串存储 list_s=[] for i in dicts.values(): list_s.append(i) str_d = ','.join(str(v) for v in list_s) return str_d #找到所有不符合条件的数据,存到list_w中,需要调用pick_info()方法 list_w=[] def pick_info(n): ''' function:查出所有符合条件的数据,返回到save列表中 term : where 条件中的字段 jud:where 条件中的比较符 num : here 条件中比较值 sign:判断该行数据是否输出的标志 dict_key:字典的key ''' term=n[-3] jud=n[-2] num=n[-1] sign=False save = [] #需要使用list_kv,所以调用函数 phone_n() for i in list_kv: if jud==">": sign=int(i[term])>int(num) elif jud=="<": sign = int(i[term])<int(num) elif jud=="=": sign=i[term].lower()==num.strip('"') elif jud=="like": sign= num.strip('"') in i[term].lower() else: print("请使用>,<,=或like查询") if sign: save.append(str(i)) else: line=value_str(i) list_w.append(line) return save def select(emp_input): #function:查询逻辑 #sort:查询字段 sort = emp_input[1] s=pick_info(emp_input) count=0 for i in s: count+=1 i=eval(i) if sort=="*": print(pick_info(emp_input)) else: sort1 = sort.split(",") show_dict = dict() for j in sort1: show_dict[j]=i[j] print(show_dict) print("33[42;1m数据总数:%s33[0m"%(count)) def update(emp_input): #function 修改逻辑 # sort 需要修改的字段 sort=emp_input[3] sort=sort.split("=") list_p=phone_n() if sort[1] not in list_p: s = pick_info(emp_input) count=0 for i in s: count+=1 i = eval(i) list_s = [] i[sort[0]]=sort[1].strip('"') print(i) #将修改后 的值写入文件中 str_d=value_str(i) list_w.append(str_d) print("33[42;1m修改成功,修改条数:%s33[0m"%(count)) with open("info.txt","w",encoding="utf-8") as f: for k in list_w: f.write(k) else: print("33[42;1mphone号码重复33[0m") def insert(emp_input): #function 新增逻辑 # sort 需要插入的字段 sort = emp_input[3] # sort_v 需要插入的值 sort_v=emp_input[-1] list_sort=sort.split(",") list_sort_v=sort_v.split(",") dict_sort=dict(zip(list_sort,list_sort_v)) #判断phone 值得唯一性 list_p=phone_n() sign=True if "phone" in dict_sort.keys(): if dict_sort["phone"] in list_p: print("33[42;1mphone号码重复33[0m") sign=False if sign: count=0 DICT_KEY = ["staffid", "name", "age", "phone", "dept", "enroll_date"] #带key的空字典 dict_ky=dict.fromkeys(DICT_KEY) dict_ky=dict(dict_ky,**dict_sort) list_n=[] with open("info.txt","r+",encoding="utf-8") as f: for line in f : if not line.strip(): continue count+=1 dict_ky["staffid"]=count+1 str_d=value_str(dict_ky) f.write(str_d) def delete(emp_input): # function:删除逻辑 pick_info(emp_input) count=0 with open("info.txt","w",encoding="utf-8") as f: for i in list_w: count+=1 f.write(i) print("33[42;0m已删除数:%s33[0m"%count) while True: emp_input=input("-->(q退出):").strip().lower() emp_input_p=emp_input.split() if emp_input_p[0]=="select" and emp_input_p.count('from')==1: select(emp_input_p) elif emp_input_p[0]=="update" and emp_input_p.count('set')==1: update(emp_input_p) elif emp_input_p[0]=="insert" and emp_input_p.count('into')==1 and emp_input_p.count('values')==1: insert(emp_input_p) elif emp_input_p[0]=="delete" and emp_input_p.count('from')==1: delete(emp_input_p) elif emp_input=="Q": break else : print("�33[31;1mERROR:输入错误�33[0m")