- 常见注意力模型
- 注意力机制应用于超分辨
- MAANet:Multi-view Aware Attention Networks
- RNAN:Residual Non-local Attention Networks for Image Restoration
- SAN:Second-order Attention Network for Single Image Super-Resolution
- TAN:Triple Attention Mixed Link Network for Single Image Super Resolution
- HRAN:Hybrid Residual Attention Network
- MGAN:Multi-grained Attention Networks
- PANet:Pyramid Attention Networks for Image Restoration
- CSNLN:Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining
常见注意力模型
Non-local Neural Networks
计算任意两个位置之间的交互直接捕捉远程依赖,而不用局限于相邻点,其相当于构造了一个和特征图谱尺寸一样大的卷积核, 从而可以维持更多信息
-
blog:
-
code:
-
idea:




-
存在问题:在[PANet](#
PANet:Pyramid Attention Networks for Image Restoration)中指出,在自注意力模块中使用的逐像素匹配通常对低级视觉任务很嘈杂(噪声问题),从而降低了性能。 从直觉上讲,扩大搜索空间会增加寻找更好匹配的可能性,但对于现有的自注意模块而言并非如此。 与采用大量降维操作的高级特征图不同,图像重建网络通常会保持输入的空间大小。 因此,特征仅与局部区域高度相关,因此容易受到噪声信号的影响。 这与传统的非局部滤波方法相一致,在传统的非局部滤波方法中,逐像素匹配的效果比块匹配要差得多。
SPATIAL TRANSFORMER NETWORKS
基于空间域的注意力机制,利用坐标进行复制,用于图像的方位变化转正
-
paper :SPATIAL TRANSFORMER NETWORKS
-
code:
-
idea:



Squeeze-and-Excitation Networks
基于通道注意力,对每个通道赋予不同的权值
-
code:
-
idea:

Residual Attention Network
-
blog:https://blog.csdn.net/u013738531/article/details/81293271
-
code:https://github.com/tengshaofeng/ResidualAttentionNetwork-pytorch
-
idea:



注意力机制应用于超分辨
MAANet:Multi-view Aware Attention Networks
-
blog:https://blog.csdn.net/weixin_42096202/article/details/103666302
-
code:
None -
idea:
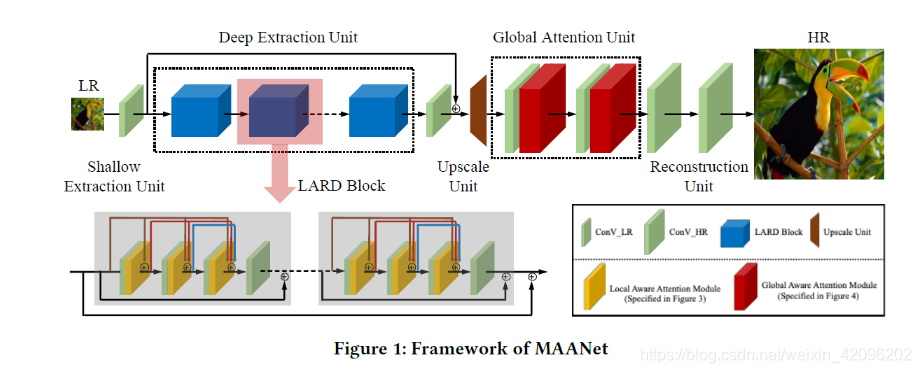
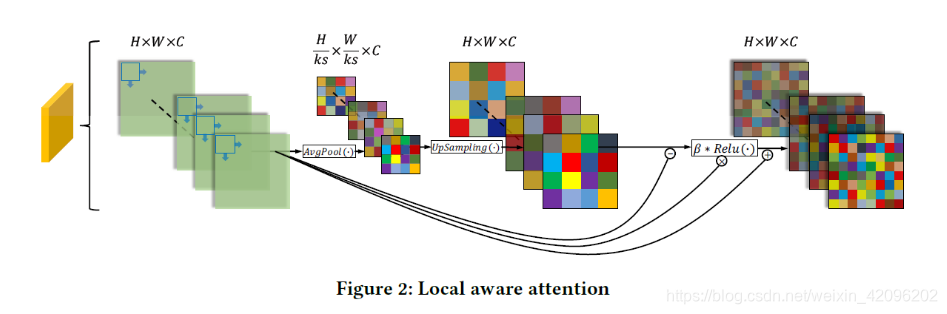
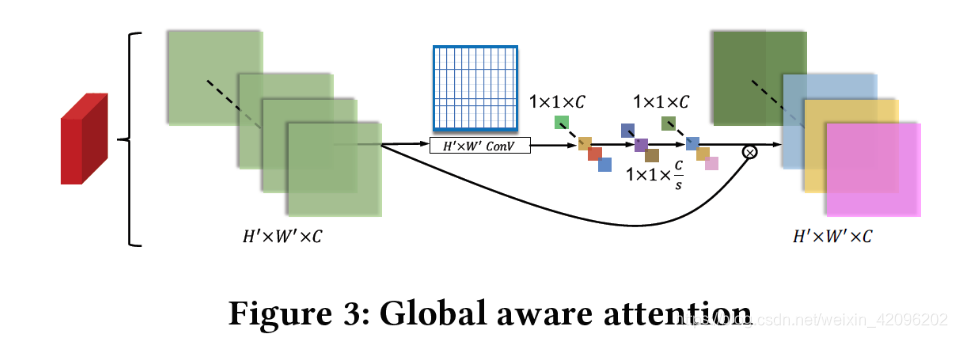
- 局部注意力利用下采样
- 全局注意力类似[Squeeze-and-Excitation Networks](#Squeeze-and-Excitation Networks)
RNAN:Residual Non-local Attention Networks for Image Restoration
-
idea:



- 主要引入了上面提到的[局部注意力](#Residual Attention Network)和[非局部注意力](#Non-local Neural Networks)
SAN:Second-order Attention Network for Single Image Super-Resolution
-
paper:http://www4.comp.polyu.edu.hk/~cslzhang/paper/CVPR19-SAN.pdf
-
idea:
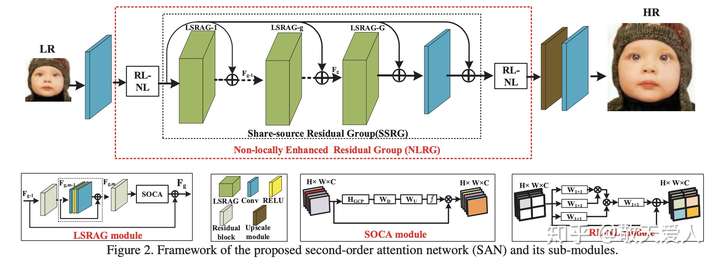
- 对于二阶注意力
SOCA比较难理解
- 对于二阶注意力
TAN:Triple Attention Mixed Link Network for Single Image Super Resolution
-
paper:https://arxiv.org/ftp/arxiv/papers/1810/1810.03254.pdf
-
blog:https://blog.csdn.net/qq_34049103/article/details/103291959

HRAN:Hybrid Residual Attention Network
-
blog:博客没人读
-
idea:


MGAN:Multi-grained Attention Networks
- paper:https://arxiv.org/pdf/1909.11937.pdf
- code:没开源
- blog:没人读
PANet:Pyramid Attention Networks for Image Restoration
-
blog:https://blog.csdn.net/weixin_42096202/article/details/106240801


- Non-Local 只能在相同尺度下提取注意力,而且是以逐像素比对的方式,会引入噪声问题,导致性能下降,且未能捕获不同特征尺度上的有用特征的依赖关系
- Scale Agnostic Attention 以patch方式捕获两个尺度上的全局像素响应
- pyramid attention 以patch的方式来捕获多个尺度上的全局响应
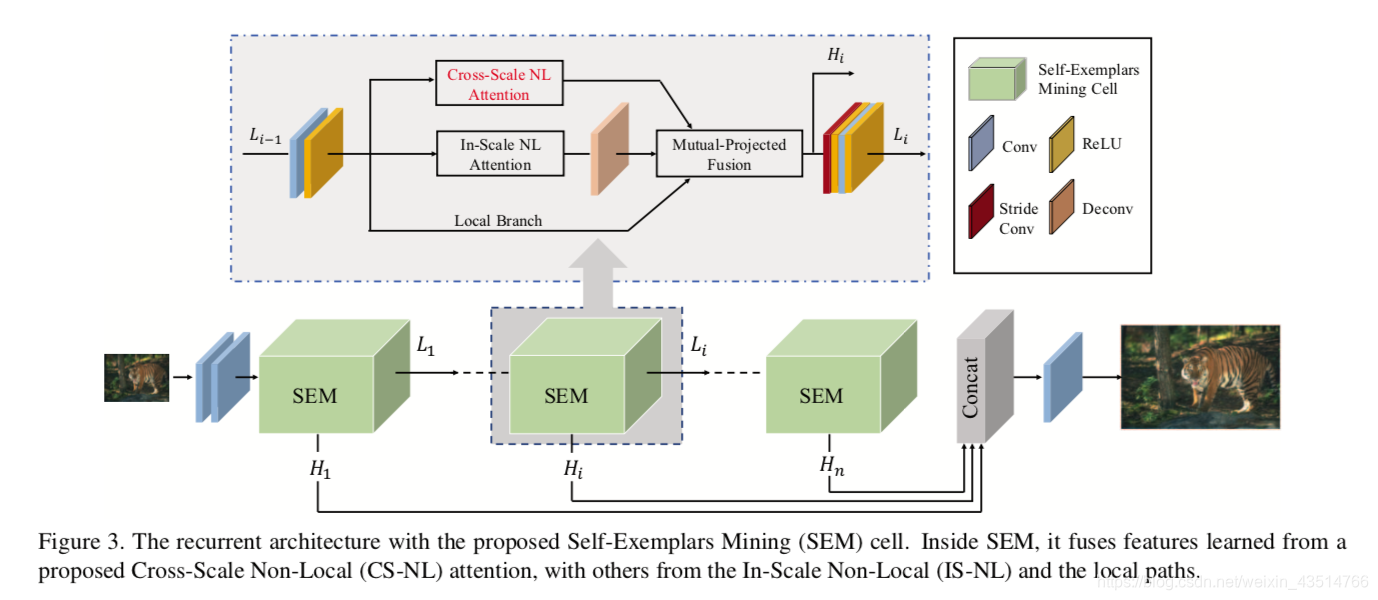
CSNLN:Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining
-
code:https://github.com/SHI-Labs/Cross-Scale-Non-Local-Attention
-
blog:https://blog.csdn.net/weixin_43514766/article/details/109996899
-
idea:
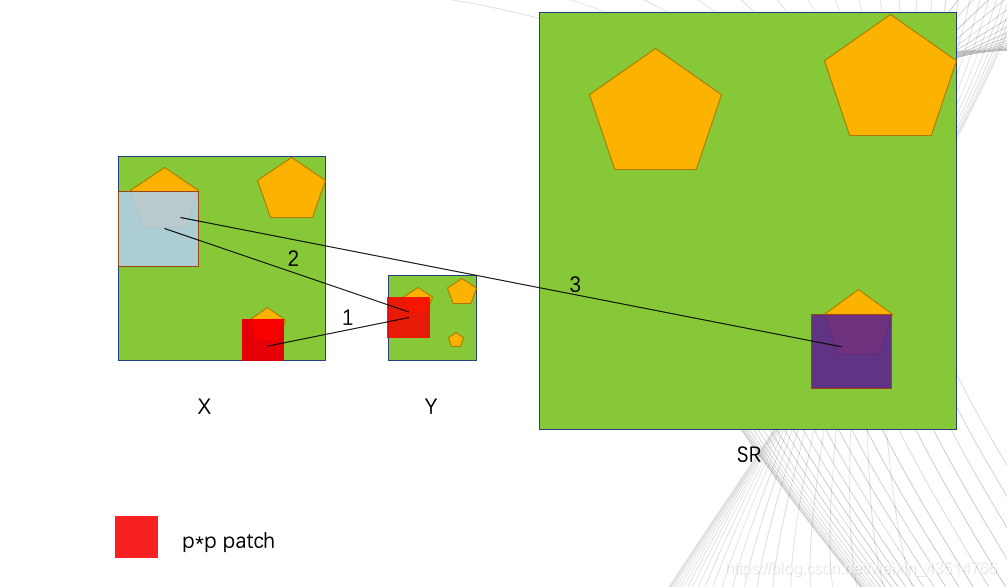
-
红色的小方块儿是pxp(p是可调参数)尺寸的,举个例子:如果我们想重建X中的红色小方块的部分(target),首先我们在X的下采样结果Y中搜寻与该target接近的小块儿(不止一个,为了方便,只画了一个,实际上应该是多个结果进行加权),Y中的小块就是与target接近的小块,此时,我们在X中找到对应该小块的“大”块,就是蓝色这块;最后,用蓝色块中的信息辅助重建目标块——SR中的紫色块。
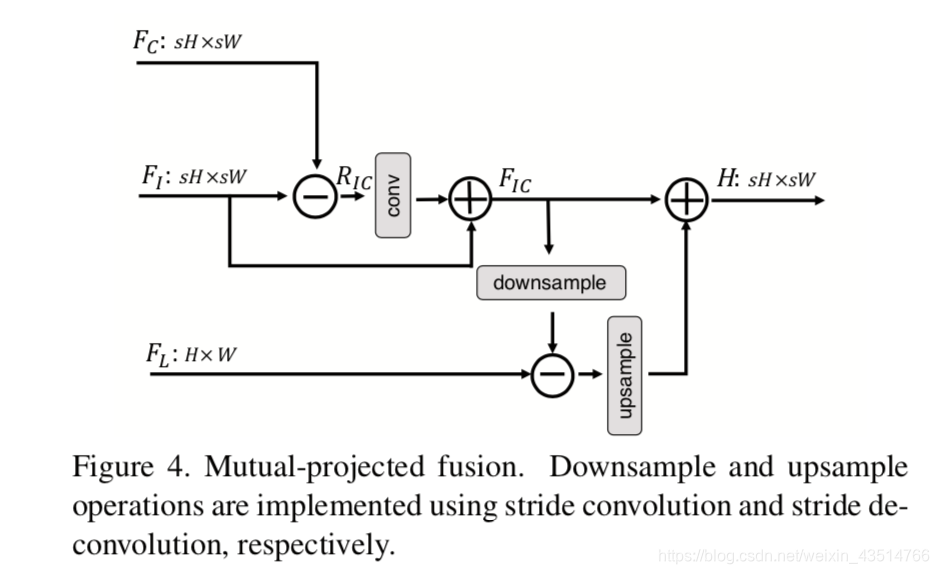
-
残差特征 RIC 表示一个来源中存在而另一来源中不存在的细节。 这种残差间的投影使网络绕过共有信息,仅关注不同源之间的特殊信息,从而提高了网络的判别能力。同时加入了反投影的思路,Mutual-Projected Fusion结构可确保在融合不同特征的同时进行残差学习,与琐碎的加法(adding)或串联(concatenating)操作相比,该融合方法可进行更具判别性的特征学习。
-