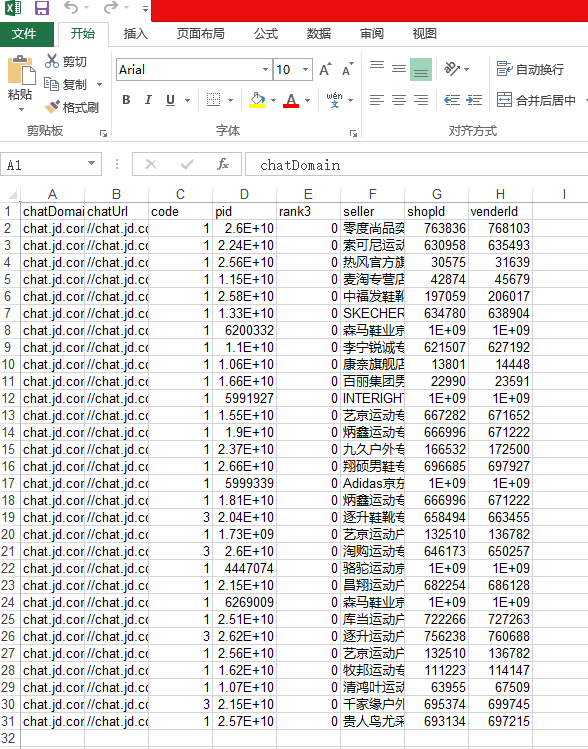
上面的为最终结果
import requests
import re
import xlwt
import json
# 导入必须的包: xlwt,json,requests,re.
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3315.4 Safari/537.36'
}
url = 'https://chat1.jd.com/api/checkChat?pidList=26004336451,22412368840,25559702284,11524577508,25820918484,13349043688,6200332,11045883520,10563894963,16632303662,5991927,15532659623,19020690355,23722306280,26619656484,5999339,18070284040,20365116716,1733647488,25959585398,4447074,21513497251,6269009,25067989736,26242379122,25628317037,16230894208,10653403147,21507885479,25729173546&callback=jQuery9142528&_=1522742110218'
# 用来获取源码
def html_index():
html = requests.get(url, headers=headers)
# 当html页面返回的状态码为200时,返回源码的文本格式
if html.status_code == 200:
return html.text
# 将数据提取并写入excei表中
def write_json(html1):
if html1:
data_list = []
# 循环得到每一个data
for data in html1:
# 循环得到data字典里的所有键值对的值
for value in data.values():
# 将得到的值放入空列表中
data_list.append(value)
# 创建一个新的列表生成式并赋给一个变量new_list.
# 这个列表生成式主要是将数据每8个为一个新的元素存入新的列表中,即列表套列表
new_list = [data_list[i:i + 8] for i in range(0, len(data_list), 8)]
# 生成一个xlwt.Workbook对象
xls = xlwt.Workbook()
# 调用对象的add_sheet方法
sheet = xls.add_sheet('sheet1', cell_overwrite_ok=True)
# 创建我们需要的第一行的标头数据
heads = ['chatDomain', 'chatUrl', 'code', 'pid', 'rank3', 'seller', 'shopId','venderId']
ls = 0
# 将标头循环写入表中
for head in heads:
sheet.write(0, ls, head)
ls += 1
i = 1
# 将数据分两次循环写入表中 外围循环行
for list in new_list:
j = 0
# 内围循环列
for data in list:
sheet.write(i, j, data)
j += 1
i += 1
# 最后将文件save保存
xls.save('案例.xls')
print(u'
录入成功!')
# 解析源码,拿到数据
def html_index_re(html):
json_data = re.compile('jQuery9142528((.*?))')
html_data = json_data.search(html)
html1 = html_data.group(1)
html1 = json.loads(html1)
# 讲得到的数据传入write_json函数中
write_json(html1)
def main():
html = html_index()
html_index_re(html)
# 这是将py文件设置成本地文件,当在本文件启动本项目时,先执行main函数,当被当成包调用时,不执行main函数。
if __name__ == '__main__':
main()