《Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks》
论文主要的三个贡献:
(1) 揭示了检测和对齐之间的内在联系;
(2) 提出了三个CNN级联的网络结构;
(3) 提出了一种对于样本的新的hard mining的算法;
整个算法流程如下:
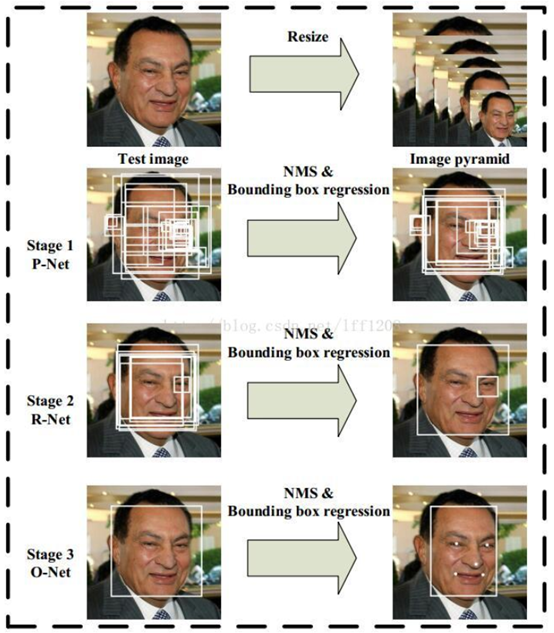
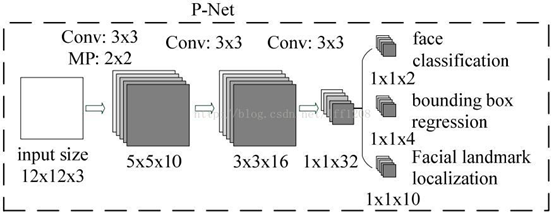
Stage 1:采用全卷积神经网络,即P-Net,去获得候选窗体和边界回归向量。同时,候选窗体根据边界框进行校准。然后,利用NMS方法去除重叠窗体。
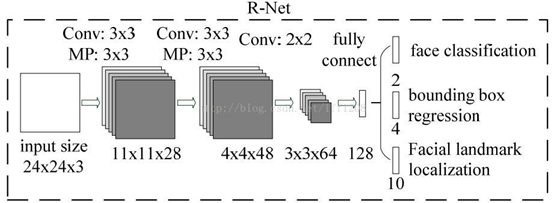
stage 2:R-Net,将经过P-Net确定的包含候选窗体的图片在R-Net网络中 训练,网络最后选用全连接的方式进行训练。利用边界框向量微调候选窗体,再利用NMS去除重叠窗体。
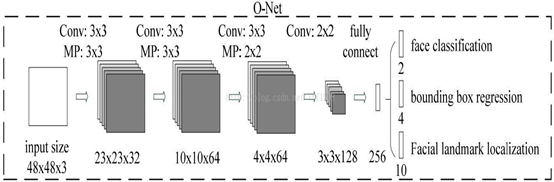
stage 3:O-Net,网络结构比R-Net多一层卷积,功能与R-Net作用一样,只是在去除重叠候选窗口的同时,显示五个人脸关键点定位。
训练:
MTCNN特征描述子主要包含3个部分,人脸/非人脸分类器,边界框回归,地标定位。
人脸分类:
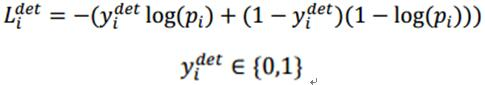
上式为人脸分类的交叉熵损失函数,其中,pi为是人脸的概率,yidet为背景的真实标签。
边界框回归:
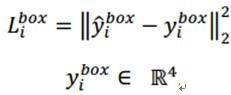
上式为通过欧氏距离计算的回归损失。其中,带尖的y为通过网络预测得到,不带尖的y为实际的真实的背景坐标。其中,y为一个(左上角x,左上角y,长,宽)组成的四元组。
地标定位:
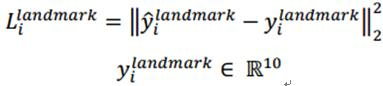
和边界回归一样,还是计算网络预测的地标位置和实际真实地标的欧式距离,并最小化该距离。其中,,带尖的y为通过网络预测得到,不带尖的y为实际的真实的地标坐标。由于一共5个点,每个点2个坐标,所以,y属于十元组。
多个输入源的训练:
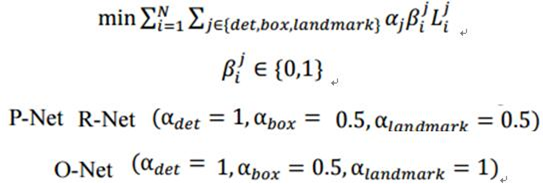
整个的训练学习过程就是最小化上面的这个函数,其中,N为训练样本数量,aj表示任务的重要性,bj为样本标签,Lj为上面的损失函数。
还有一点注意的是:在训练过程中,为了取得更好的效果,作者采用了一种新的hard mining 策略,它是在线的,而目前大多数都是offline即检测完之后再进行mining。具体做法就是:每次前向传播完一个batch的样本之后,根据loss对这些样本进行排列,选择前70%的样本反向传播它们的梯度,即认为这70%的样本是hard sample,并且忽略剩下的30%的easy sample对网络优化的影响。
测试流程参见附图,对图像进行金字塔处理,笔者用的缩放系数是1.3,注意pnet是全图计算,得到的featureMap上每个点对应金字塔图上12*12的大小,然后是否通过分类阈值进行窗口合并(NMS)和人脸框位置矫正。在pnet和rnet阶段,笔者实验发现人脸框位置矫正在NMS之前能提高召回率,在onet阶段,为避免同一人脸输出多个框,将NMS操作放在人脸框位置矫正之后。
在训练过程中,y尖和y的交并集IoU(Intersection-over-Union)比例:
0-0.3:非人脸
0.65-1.00:人脸
0.4-0.65:Part人脸
0.3-0.4:地标
训练样本的比例,负样本:正样本:part样本:地标=3:1:1:2