转载链接如下:
Softmax理解之margin - 王峰的文章 - 知乎 https://zhuanlan.zhihu.com/p/52108088
在了解如何引入 margin 之前,我们首先要知道为何要加margin。在SVM时代,margin (以下称作间隔)被认为是模型泛化能力的保证,但在神经网络时代使用的最多的损失函数 Softmax 交叉熵损失中并没有显式地引入间隔项。从第一篇和第三篇文章中我们知道通过 smooth 化,可以在类间引入一定的间隔,而这个间隔与特征幅度和最后一个内机层的权重幅度有关。但这种间隔的大小主要是由网络自行调整,并不是我们人为指定的,网络自行调整的间隔并不一定是最优的。实际上为了减小损失函数的值,margin 为零甚至 margin 为负才是神经网络自认为正确的优化方向。
此外,在人脸认证、图像检索、重识别任务中,是通过特征与特征之间的距离来判断两个样本的相似度的。因此我们一般不使用整个网络模型,而是将最后的分类层丢掉,仅仅使用模型提取特征。例如下图的一个二分类问题:
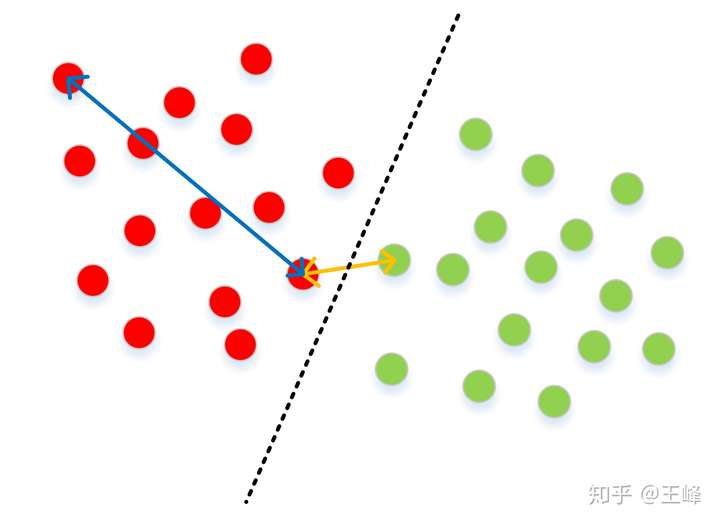
红色点和绿色点可以被一条分界线很好地分开,作为一个分类模型,这条分界线的表现很不错,识别率100%。但如果要进行特征比对任务,这个模型就远远不够精确了:从图上我们可以看到,分界线两侧的两个点之间的距离(黄色箭头)可能会远小于类内的最大距离(蓝色箭头)。所以使用分类器来训练特征比对任务是远远不够的,我们必须将类间的间隔拉得更大,才能保证“类间距离大于类内距离”这一目标。
可以这么说:度量学习(特征比对)是比分类更难的问题。至于究竟难多少,SphereFace这篇文章的 Property 3 指出,度量学习比分类困难3倍。当然说一个问题比另一个问题困难几倍这种说法本身就不太科学,大家有个大致的概念即可,不要过于纠结这个数字。
下面就来谈谈如何提高间隔。在我们这个系列的第一篇文章中,使用了如下优化目标:
输出C个分数,使目标分数比最大的非目标分数更大。
其对应的损失函数为:
。
参考 hinge loss,引入间隔项:
,
这个损失函数的意义是:
输出C个分数,使目标分数比最大的非目标分数还要大 m。
这里的m由我们手动进行调节,m 越大,则我们会强行要求目标与非目标分数之间拉开更大的差距。但注意到,如果我们不限制分数 的取值范围,那网络会自动优化使得分数
整体取值都非常大,这样会使得我们所设置的 m 相对变小,非常不便。
因此我们需要使用第三篇文章中提到的归一化方法,让分数 由余弦层后接一个尺度因子 s 来得到。这样我们就可以手动控制分数
的取值范围,以方便设置参数 m。
于是损失函数变为:
,
这里的 s 看似是一个冗余项,损失函数乘以一个常数并不影响其优化。但因为我们后面要将这个损失函数 smooth 化,所以这里仍然保留着 s 项。接下来使用第一篇文章中的 smooth 技巧,将损失函数化为:
。
因为这里的 m 与分数 之间是加减的关系,所以我们称这个损失函数为“带有加性间隔的 Softmax 交叉熵损失函数”。
这个损失函数中有两个参数,一个 s 一个 m。其中 s 的设置参照第三篇文章,其实只要超过一定的阈值就可以了,一般来说需要设置一个最小值,然后让 s 按照正常的神经网络参数的更新方式来更新。对于 m 的设置目前还需要手动调节,下一篇文章会介绍一些自动设置的方法,但效果还是不如调参师手工调整的好。
下面给大家直观地展示一下两个参数的效果,因为我们对特征和类向量进行了 归一化,所以特征和类向量全部分布在单位球上。我随便训练了一个MNIST模型,取出最后10个类向量,然后遍历整个球上的点,计算每个点所对应的最高概率值。由于Softmax交叉熵损失的定义为概率值的负对数,所以通过概率值我们就能够(间接地)看出损失函数的表面形状。
在不加间隔,即 时,不同的 s 会产生不同的边界形状:

s 越小,边界变化会越平缓。这样会使得每个类的点更加向类中心收拢,其实也可以起到一定的增加类间间隔的作用。但根据第三篇文章,过小的 s 会带来近似不准确的缺点,所以通过缩小 s 来增加间隔并不是一个好方法。想要添加类间间隔当然还是直接显式地添加比较好。
在 的基础上添加间隔项 m 的效果如下:
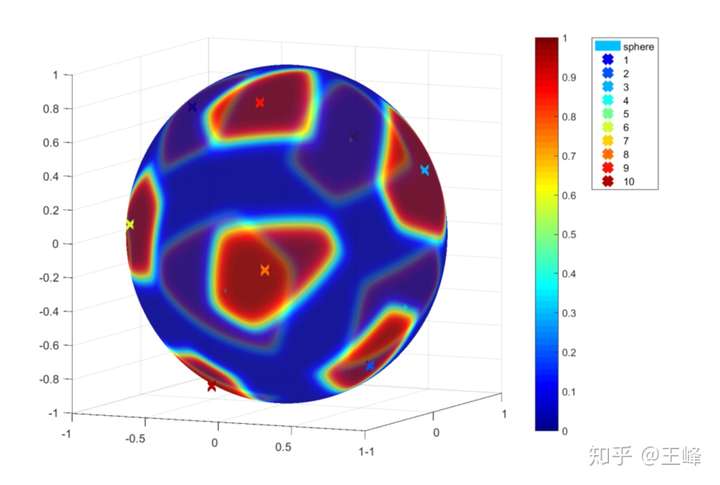
对比这张图和上边的(c)图,可以看到每个类别所占据的区域减小了,样本只有落在红色区域内才被认为是分类正确的。从这张图上可以看出,由于限制了特征空间在单位球上,添加间隔项 m 可以同时增大类间距离并缩小类内距离。而且这个间隔可以由我们来手动调节,在过拟合严重的数据集上,我们可以增加 m 来使得目标更难,起到约束的作用,从而降低过拟合效应。