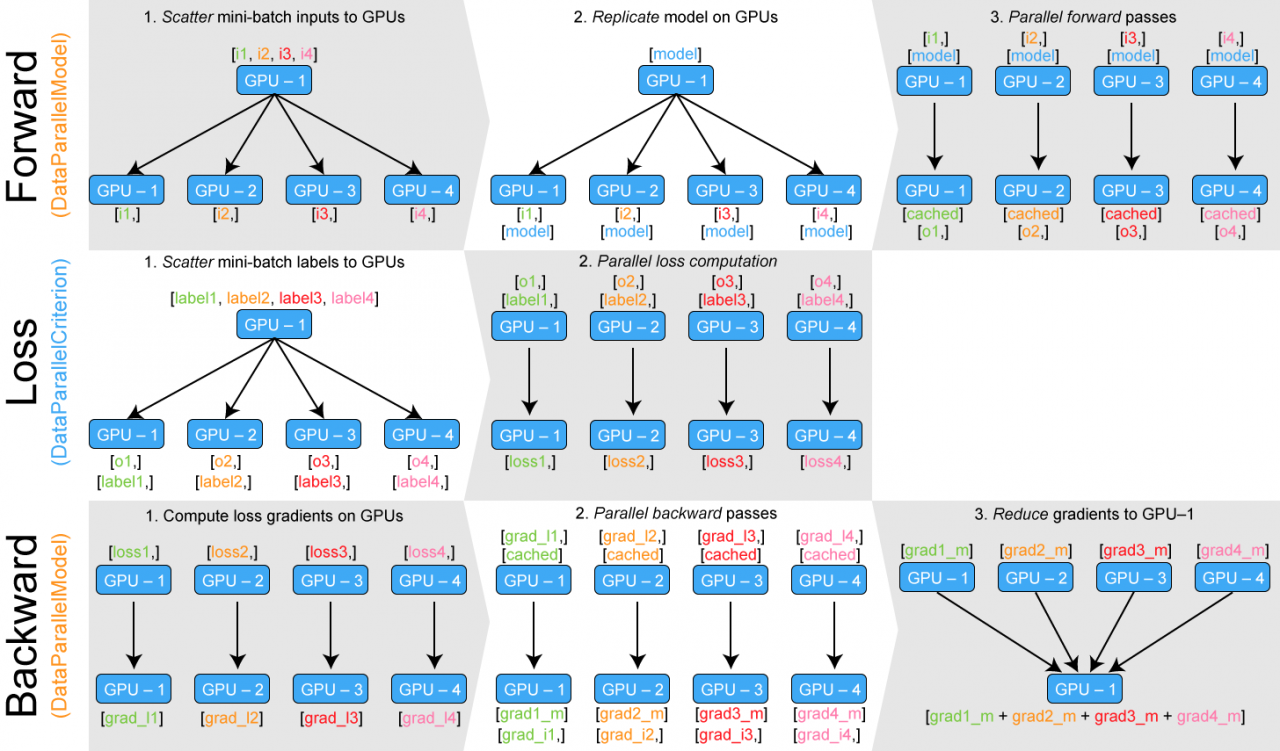
使用DataParallel进行并行化时的结构如下:
在上图第一行第四个步骤中,GPU-1 其实汇集了所有 GPU 的运算结果。这个对于多分类问题还好,但如果是自然语言处理模型就会出现问题,导致 GPU-1 汇集的梯度过大,直接爆掉。
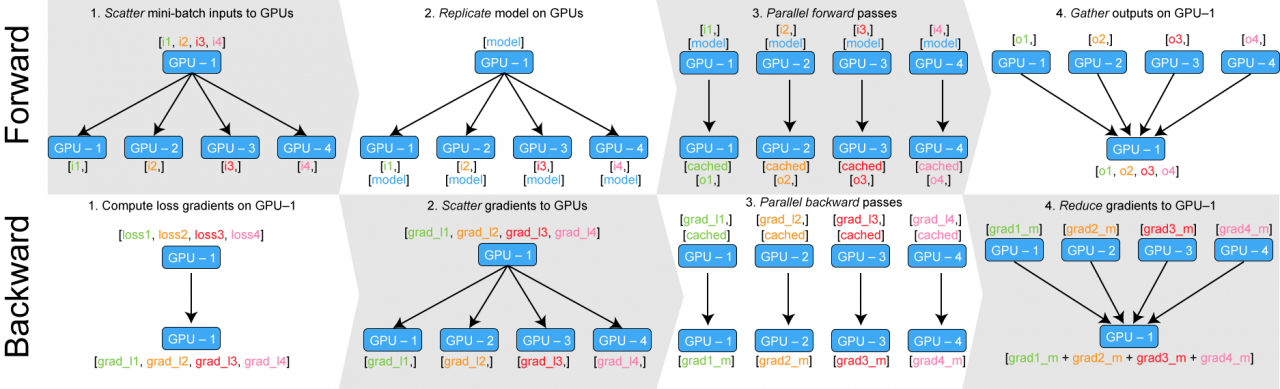
那么就要想办法实现多 GPU 的负载均衡,方法就是让 GPU-1 不汇集梯度,而是保存在各个 GPU 上。这个方法的关键就是要分布化我们的损失函数,让梯度在各个 GPU 上单独计算和反向传播。这里又一个开源的实现:https://github.com/zhanghang1989/PyTorch-Encoding。这里是一个修改版,可以直接在我们的代码里调用:地址。实例:
from parallel import DataParallelModel, DataParallelCriterion parallel_model = DataParallelModel(model) # 并行化model parallel_loss = DataParallelCriterion(loss_function) # 并行化损失函数 predictions = parallel_model(inputs) # 并行前向计算 # "predictions"是多个gpu的结果的元组 loss = parallel_loss(predictions, labels) # 并行计算损失函数 loss.backward() # 计算梯度 optimizer.step() # 反向传播 predictions = parallel_model(inputs)
如果你的网络输出是多个,可以这样分解:
output_1, output_2 = zip(*predictions)
如果有时候不想进行分布式损失函数计算,可以这样手动汇集所有结果:
gathered_predictions = parallel.gather(predictions)
下图展示了负载均衡以后的原理: