参考:https://blog.csdn.net/php_lzr/article/details/98853027
重复数据处理
场景一:这种方法只是统计了该字段重复对应的具体的个数
列出字段重复的数据
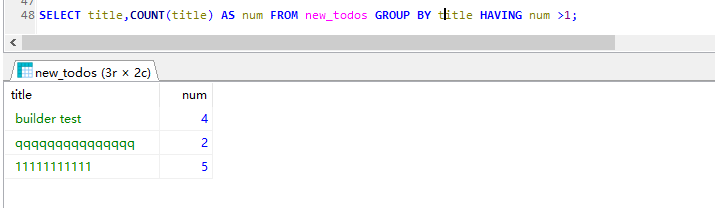
例子: 如图数据表 有重复数据,列出 title 有重复的数据

SELECT title,COUNT(title) AS num FROM new_todos GROUP BY title HAVING num >1;
查询结果:
SELECT title,COUNT(title) AS COUNT FROM new_todos GROUP BY title HAVING COUNT(title) >1 ORDER BY COUNT desc;

场景二:场景二:列出username字段重复记录的具体指:
SELECT * FROM new_todos WHERE title IN (SELECT title FROM new_todos GROUP BY title HAVING COUNT(title)>1)

这条语句当数据流大的时候可能效率比较低比较耗时,mysql没有为了子查询 生成临时表,数据流大的时候查询效率低。
可以先建立临时表
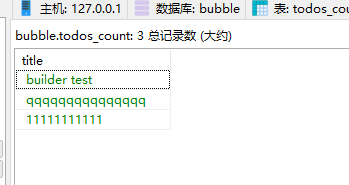
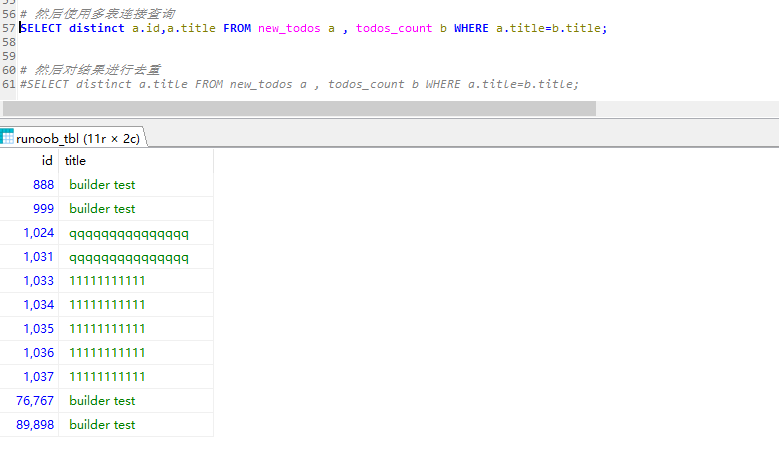
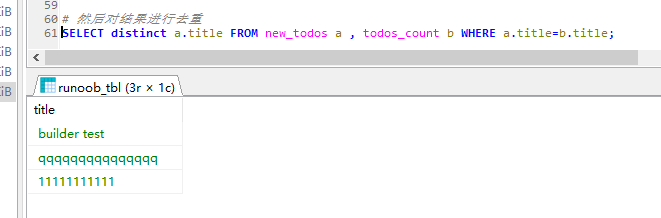
# 先创建临时表 # REATE TABLE `todos_count001` AS (SELECT title FROM new_todos GROUP BY title HAVING COUNT(title)>1) # 然后使用多表连接查询 # SELECT distinct a.id,a.title FROM new_todos a , todos_count b WHERE a.title=b.title; # 然后对结果进行去重 SELECT distinct a.title FROM new_todos a , todos_count b WHERE a.title=b.title;
#场景三 查询表中多个字段同时重复的记录
查看两个字段都有重复# 这里查询 title字段 和status 字段都有重复的数据
SELECT * FROM new_todos t WHERE (t.title,t.status) IN (SELECT title,status FROM new_todos GROUP BY title,status HAVING COUNT(*)>1)
