深入理解之String类
String源码
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
...
}
由源代码可以看出
- String类不可被继承,String对象是可不变的
- String实例的字符串都是同过char[]储存的
- String 类中每一个看起来会修改 String 值的方法,实际上都是创建了一个全新的 String对象,以包含修改后的字符串内容。而最初的 String 对象则丝毫未动 。
public class Test {
public static void main(String[] args) {
String str1 = "aaBBcc";
System.out.println(str1);//aaBBcc
String str2 = upcase(str1);
System.out.println(str2);//AABBCC
System.out.println(str1);//aaBBcc
}
public static String upcase(String str){
return str.toUpperCase();
}
}
str1 并没有改变
+与StringBuilder
在java中+连接符可以用来连接字符串,其原理又是怎么样的呢,看看代码
//测试代码
public class Test {
public static void main(String[] args) {
String str1 = "str1-a";
String str2 = "str2-b";
System.out.println(str1+str2);
}
}
//反编译结果
public class Test
{
public Test(){}
public static void main(String args[])
{
String str1 = "str1-a";
String str2 = "str2-b";
System.out.println((new StringBuilder()).append(str1).append(str2).toString());
}
}
根据源码可以看出:
在java中使用+拼接字符串的时候,编译器会默认的创建StringBuilder对象使用append()方法拼接字符串,然后调用toString方法返回拼接好的字符串。 由于append()方法的各种重载形式会调用String.valueOf方法。
+的运行效率
使用“+”连接符时,JVM会隐式创建StringBuilder对象,这种方式在大部分情况下并不会造成效率的损失,不过在进行大量循环拼接字符串时则需要注意。
String s = "abc";
for (int i=0; i<10000; i++) {
s += "abc";
}
/**
* 反编译后
*/
String s = "abc";
for(int i = 0; i < 1000; i++) {
s = (new StringBuilder()).append(s).append("abc").toString();
}
这样由于大量StringBuilder创建在堆内存中,肯定会造成效率的损失 ,可以在外面创建StringBuilder优化
StringBuilder sb = new StringBuilder("abc");
for (int i = 0; i < 1000; i++) {
sb.append("abc");
}
sb.toString();
还有一种特殊情况,当+两边在编译期都为确定的字符串常量时,编译器会自动优化,直接将两个常量拼接好。
例如:
System.out.println("hello"+"world");
//反编译后
System.out.println("helloworld");
---------------------------------
//final 修饰变量 不可变
String s1 = "hello1";
final int i = 1;
String s2 = "hello"+i;
System.out.println(s2==s1)//true
---------------------------------
String s1 = "hello1";
final int i = getI();
//虽然通过final修饰但是是通过方法调用的,指向的不是同一个对象
String s2 = "hello"+i;
System.out.println(s2==s1)//false
public int getI(){ return 1;}
字符串常量池
在JDK1.7之前运行时常量池逻辑包含字符串常量池存放在方法区, 时hotspot虚拟机对方法区的实现为永久代
在JDK1.7字符串常量池被方法区拿到了堆中,运行时常量池还在方法区中
在JDK1.8hotspot移除了方法区,用元空间代替,字符串常量池还在堆中,运行时常量池还在方法区中, 只不过方法区的实现从永久代变成了元空间(Metaspace)
字符串池里的内容是在类加载完成,经过验证,准备阶段之后在堆中生成字符串对象实例,然后将该字符串对象实例的引用值存到string pool中(记住:string pool中存的是引用值而不是具体的实例对象,具体的实例对象是在堆中开辟的一块空间存放的)。 在HotSpot VM里实现的string pool功能的是一个StringTable类,它是一个哈希表,里面存的是驻留字符串(也就是我们常说的用双引号括起来的)的引用(而不是驻留字符串实例本身),也就是说在堆中的某些字符串实例被这个StringTable引用之后就等同被赋予了”驻留字符串”的身份。这个StringTable在每个HotSpot VM的实例只有一份,被所有的类共享。
intern方法
String str1 = "hello";
//这样直接声明出来得String对象存放在字符串常量池中
String Str2 = new String("word");
//new出来的String对象存放在堆中
/**
* Returns a canonical representation for the string object.
* <p>
* A pool of strings, initially empty, is maintained privately by the
* class {@code String}.
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
* <p>
* It follows that for any two strings {@code s} and {@code t},
* {@code s.intern() == t.intern()} is {@code true}
* if and only if {@code s.equals(t)} is {@code true}.
* <p>
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* <cite>The Java™ Language Specification</cite>.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
*/
public native String intern();
intern 方法是一个native方法, String对象的intern方法会得到字符串对象在常量池中对应的引用,如果常量池中没有对应的字符串,则该字符串将被添加到常量池中,然后返回常量池中字符串的引用;
String str1 = new StringBuilder("计算机").append("软件").toString();
System.out.println(str1.intern() == str1);
String str2 = new StringBuilder("ja").append("va").toString();
System.out.println(str2.intern() == str2);
//output true/false
字符串常量池在jdk1.7之后就移到堆中了,那只需要在常量池里记录一下首次出现的实例引用即可,因此intern()返回的引用和由StringBuilder创建的那个字符串实例就是同一个。而对str2比较返回false,这是因为“java这个字符串在执行String-Builder.toString()之前就已经出现过了,字符串常量池中已经有它的引用,不符合intern()方法要求“首次遇到”的原则,“计算机软件”这个字符串则是首次
出现的,因此结果返回true
测试题
public class Test {
public static void main(String[] args) {
String str = "1";
String str1 = "ssss" + str;
String str2 = (new StringBuilder("ssss")).append(str).toString();
String str3 = (new StringBuilder()).append("ssss").append(str).toString();
String str4 = "ssss1";
final int i = 1;
String str5 = "ssss" + i;
String str6 = String.valueOf(i);
String str7 = "ss" +"ss1";
String str8 = new String("ssss1");
String str9 = new String("ssss1");
System.out.println(str1 == str2);//f
System.out.println(str1 == str3);//f
System.out.println(str2 == str3);//f
System.out.println(str1 == str4);//f
System.out.println(str2 == str4);//f
System.out.println(str3 == str4);//f
System.out.println(str5 == str4);//t
System.out.println(str == str6);//f
System.out.println(str7 == str4);//t
System.out.println(str4 == str8);//f
System.out.println(str8.intern() == str4);//t
System.out.println(str8.intern() == str9.intern());//t
System.out.println(str8.intern() == str9);//f
}
}
StringBuilder
StringBuilder类表示一个可变的字符序列,是一个非线程安全的容器,一般使用于单线程拼接字符串。
StringBuilder源码
public final class StringBuilder
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence{
public StringBuilder() {
super(16);
}
public StringBuilder(int capacity) {
super(capacity);
}
public StringBuilder(String str) {
super(str.length() + 16);
append(str);
}
public StringBuilder(CharSequence seq) {
this(seq.length() + 16);
append(seq);
}
...
}
由源码可得知
- StringBuilder由final修饰,不能被继承
- 继承于AbstractStringBuilder类
- 默认容量为16
StringBuffer
StringBuffer 也是继承于 AbstractStringBuilder ,使用 value 和 count 分别表示存储的字符数组和字符串使用的计数,StringBuffer 与 StringBuilder 最大的区别就是 StringBuffer 可以在多线程场景下使用,StringBuffer 内部有大部分方法都加了 synchronized 锁。在单线程场景下效率比较低,因为有锁的开销。
StringBuffer源码
public final class StringBuffer
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence
{
/**
* A cache of the last value returned by toString. Cleared
* whenever the StringBuffer is modified.
*/
private transient char[] toStringCache;
static final long serialVersionUID = 3388685877147921107L;
public StringBuffer() {
super(16);
}
public StringBuffer(int capacity) {
super(capacity);
}
public StringBuffer(String str) {
super(str.length() + 16);
append(str);
}
public StringBuffer(CharSequence seq) {
this(seq.length() + 16);
append(seq);
}
@Override
public synchronized int length() {
return count;
}
@Override
public synchronized int capacity() {
return value.length;
}
@Override
public synchronized void ensureCapacity(int minimumCapacity) {
if (minimumCapacity > value.length) {
expandCapacity(minimumCapacity);
}
}
...
}
由源码分析可得知:
- StringBuffer由final修饰,不能被继承
- 继承于AbstractStringBuilder类
- 默认容量为16
- 线程安全
- 拥有字符缓冲数组
StringBuilder和StringBuffer的扩容问题
StringBuilder和StringBuffer都继承于AbstractStringBuilder,所以看看AbstractStringBuilder源码
AbstractStringBuilder源码
abstract class AbstractStringBuilder implements Appendable, CharSequence {
//底层都是由char[]实现
char[] value;
int count;
AbstractStringBuilder() {}
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
@Override
public int length() {
return count;
}
//初始化容量数组长度
public int capacity() {
return value.length;
}
public void ensureCapacity(int minimumCapacity) {
if (minimumCapacity > 0)
ensureCapacityInternal(minimumCapacity);
}
//扩容方法
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
if (minimumCapacity - value.length > 0)
expandCapacity(minimumCapacity);
}
/**
*minimumCapacity 就是字符长度 + 要拼接的字符串长度
*扩容原字符长度的两倍+2
*如果扩容后的长度还比拼接后的字符串长度小的话,就直接扩容到它需要的长度
*内存溢出了就抛异常
*在进行数组的拷贝,完成扩容
*/
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}
}
扩容总结:
StringBuilder和Stringbuffer的默认容量都是16,扩容机制都是相同的,扩容一般扩容原字符串长度的两倍+2,如果发现还是不够小于字符长度 + 要拼接的字符串长度。就直接扩到需要的长度。
String、StringBuilder与StringBuffer
共同点:
- 都被final修饰,不可被继承
- 底层都由char[]实现
不同点:
- String和StringBuilder都是线程不安全的,StringBuffer为线程安全的
- StringBuilder拼接字符串的效率比StringBuffer高
- String是不可变字符序列,StringBuffer、StringBuilder是可变字符序列

String的equals方法
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
主要是比较两个字符串的内容是否相同
String的hashCode方法
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
问:为什么会选择31作为乘子?
选择数字31是因为它是一个奇质数,如果选择一个偶数会在乘法运算中产生溢出,导致数值信息丢失,因为乘二相当于移位运算。选择质数的优势并不是特别的明显,但这是一个传统。同时,数字31有一个很好的特性,即乘法运算可以被移位和减法运算取代,来获取更好的性能: 31 * i == (i << 5) - i ,jvm会自动完成这个优化。
面试题
“ Java里面有==运算符了,为什么还需要equals啊?”
equals主要的作用是用来比较两个对象的逻辑是否相等,==则是用来比较两个对象的地址是否相等。Object类中的equals方法作用与==相同。
public boolean equals(Object obj) {
return (this == obj);
}
"重写equals有哪些准则?"
自反性:对于任何非空引用值 x,x.equals(x) 都应返回 true。
对称性:对于任何非空引用值 x 和 y,当且仅当 y.equals(x) 返回 true 时,x.equals(y) 才应返回 true。
传递性:对于任何非空引用值 x、y 和 z,如果 x.equals(y) 返回 true, 并且 y.equals(z) 返回 true,那么 x.equals(z) 应返回 true。
一致性:对于任何非空引用值 x 和 y,多次调用 x.equals(y) 始终返回 true 或始终返回 false, 前提是对象上 equals 比较中所用的信息没有被修改。
非空性:对于任何非空引用值 x,x.equals(null) 都应返回 false。
“什么hashcode?”
hashcode()的作用是获取哈希码, 主要用于查找的快捷性,因为hashCode也是在Object对象中就有的,所以所有Java对象都有hashCode,在HashTable和HashMap这一类的散列结构中,都是通过hashCode来查找在散列表中的位置的。
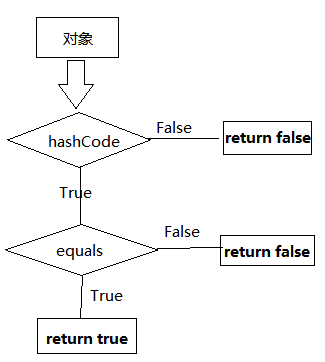
equals相等则hashcode必然相等,hashcode相等,equals不一定相等。
“你重写过hashcode方法和equals方法吗?为什么重新equals时必须重写hashcode?”
如果两个对象相等,则hashcode一定也是相同的
两个对象相等,对两个对象分别调用equals方法都返回true
两个对象有相同的hashcode值,它们也不一定是相等的
因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖
hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据
对象的比较过程如下