Aberdeen 的一项调查表明,实施数据湖的组织比同类公司在有机收入增长方面高出 9%。这些领导者能够进行新类型的分析,例如通过日志文件、来自点击流的数据、社交媒体以及存储在数据湖中的互联网连接设备等进行机器学习。这有助于他们通过吸引和留住客户、提高生产力、主动维护设备以及做出明智的决策来更快地识别和应对业务增长机会。
一、数据湖的定义
数据湖(Data Lake)是一个以原始格式存储数据的存储库或系统。它按原样存储数据,而无需事先对数据进行结构化处理。一个数据湖可以存储结构化数据(如关系型数据库中的表),半结构化数据(如CSV、日志、XML、JSON),非结构化数据(如电子邮件、文档、PDF)和二进制数据(如图形、音频、视频),并运行不同类型的分析从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
二、数据湖的架构
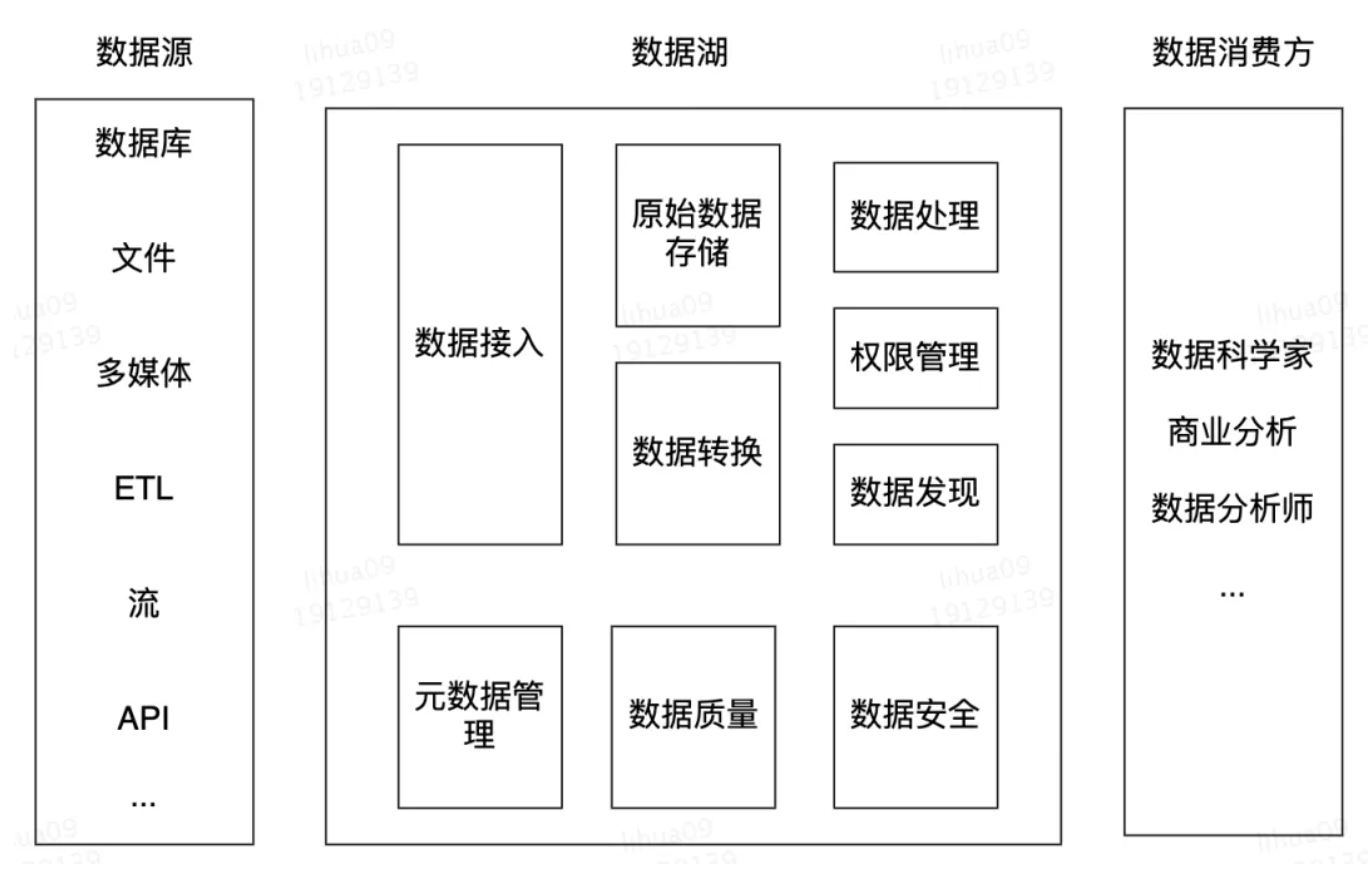
三、数据湖的核心能力
3.1数据集成
-
接入不同数据源,包括结构化数据(关系型或者非关系型数据库的表)、半结构化数据(csv、json、文档等)、非结构化数据、数据流、ETL工具(Kafka、Logstash、DataX等)转换后的数据、应用API获取的数据(如日志等);
-
自动生成元数据信息,确保进入数据湖的数据都有元数据;
-
提供统一的接入方式,如统一的API或者接口;
3.2数据存储
数据湖存储的数据量巨大且来源多样,数据湖应该支持异构和多样的存储,如HDFS、HBase、Hive等,存储原始格式的数据;
3.3数据搜索
数据湖中拥有海量的数据,对于用户来说,明确知道数据湖中数据的位置,快速的查找到数据,是一个非常重要的功能。
3.4数据治理
-
自动提取元数据信息,并统一存储;
-
对元数据进标签和分类,建立统一的数据目录;
-
建立数据血缘图谱,梳理上下游的脉络关系,有助于数据问题定位分析、数据变更影响范围评估、数据价值评估;
-
数据版本管理,便于回溯与分析。
3.5数据质量
-
对于接入的数据质量管控,提供数据字段校验、数据完整性分析等功能;
-
监控数据处理任务,避免未执行完成任务生成不完备数据;
-
配置数据执行完成校验,防止数据量发生突变,数据空值较多等。
3.6安全管控
对数据的使用权限进行管控,对敏感数据进行脱敏或加密处理,也是数据湖能商用所必须具备的能力。
3.7自助数据发现
提供一系列数据分析工具,便于用户对数据湖的数据进行自助数据发现,包括:
-
联合分析;
-
交互式大数据SQL分析;
-
机器学习;
-
BI报表;
-
支持对流、NoSQL、图等多种存储库的联合分析能力
-
...
四、数据湖的生命周期
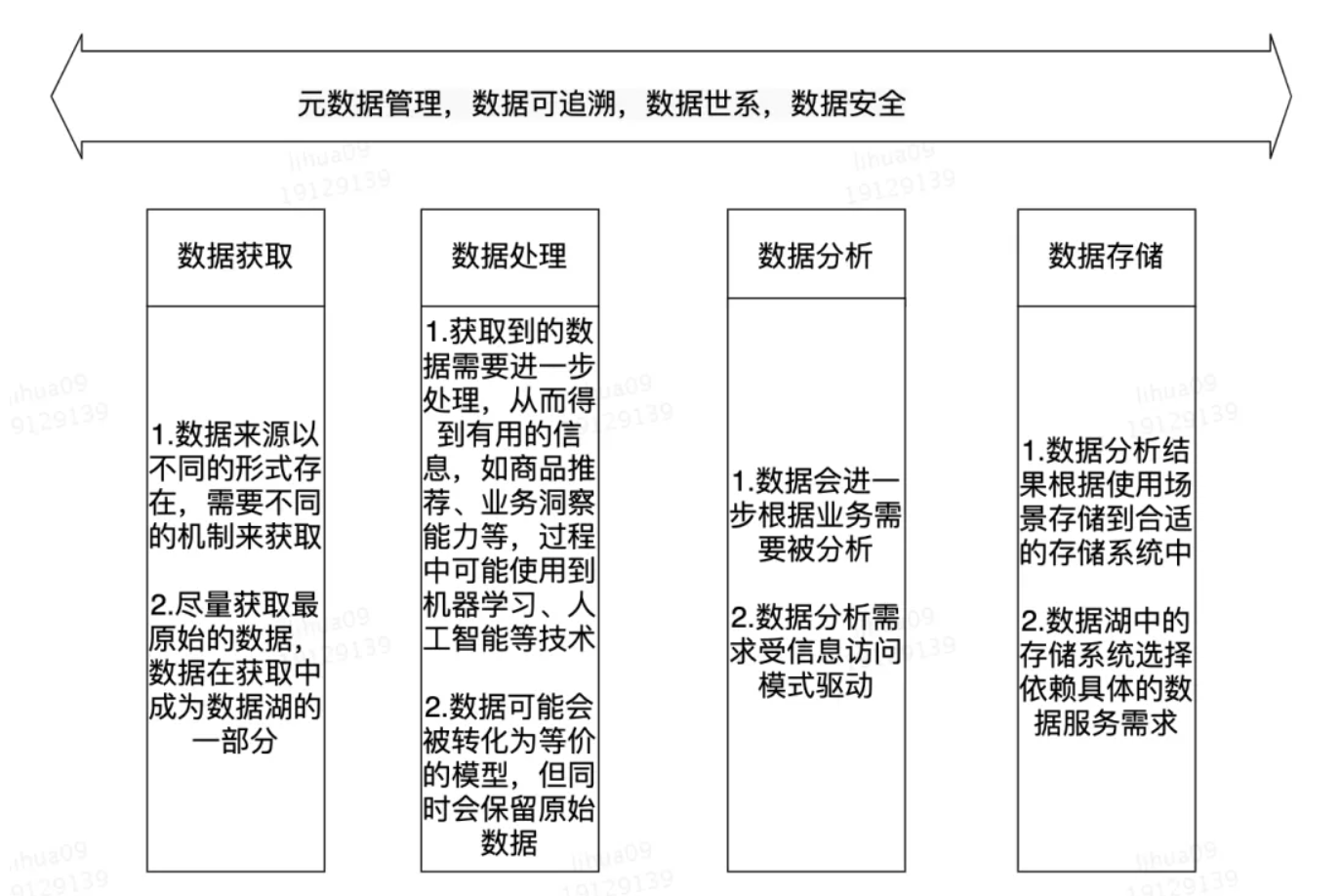
五、数据湖与数据仓库的区别
数据仓库是一个优化的数据库,用于分析来自事务系统和业务线应用程序的关系数据。事先定义数据结构和 Schema 以优化快速 SQL 查询,其中结果通常用于操作报告和分析。数据经过了清理、丰富和转换,因此可以充当用户可信任的“单一信息源”。
数据湖存储来自业务线应用程序的关系数据,以及来自移动应用程序、IoT 设备和社交媒体的非关系数据。捕获数据时,未定义数据结构或 Schema。这意味着您可以存储所有数据,而不需要精心设计也无需知道将来您可能需要哪些问题的答案。您可以对数据使用不同类型的分析(如 SQL 查询、大数据分析、全文搜索、实时分析和机器学习)来获得见解。
|
数据湖 |
数据仓库 | |
|---|---|---|
|
数据 |
来自 IoT 设备、网站、移动应用程序、社交媒体和企业应用程序的非关系和关系数据 |
来自事务系统、运营数据库和业务线应用程序的关系数据 |
|
Schema |
写入在分析时(读取型 Schema) |
设计在数据仓库实施之前(写入型 Schema) |
|
性价比 |
更快查询结果只需较低存储成本 |
更快查询结果会带来较高存储成本 |
|
数据质量 |
任何可以或无法进行监管的数据(例如原始数据) |
可作为重要事实依据的高度监管数据 |
|
用户 |
数据科学家、数据开发人员和业务分析师(使用监管数据) |
业务分析师 |
|
分析 |
机器学习、预测分析、数据发现和分析 |
批处理报告、BI 和可视化 |
六、数据湖的价值
能够在更短的时间内从更多来源利用更多数据,并使用户能够以不同方式协同处理和分析数据,从而做出更好、更快的决策。
七、数据湖的挑战
数据湖架构的主要挑战是存储原始数据而不监督内容。对于使数据可用的数据湖,它需要有定义的机制来编目和保护数据。没有这些元素,就无法找到或信任数据,从而导致“数据沼泽”的出现。满足更广泛受众的需求需要数据湖具有管理、语义一致性和访问控制。
八、数据湖的开源平台和组件
三大开源的数据湖项目Delta Lake、Iceberg 和 Hudi 。商业数据湖平台有zaloni、Azure、Amazon、阿里云等。
8.1Delta Lake
Delta Lake是Databricks公司开源的一个项目。它基于自家的Spark,为数据湖提供支持ACID事务的数据存储层。主要功能包括:支持ACID事务、元数据处理、数据历史版本、Schema增强等。
8.2Iceberg
Netflix的数据湖原先是借助Hive来构建,但发现Hive在设计上的诸多缺陷之后,开始转为自研Iceberg,并最终演化成Apache下一个高度抽象通用的开源数据湖方案。
8.3Hudi
Apache Hudi是由Uber的工程师为满足其内部数据分析的需求而设计的数据湖项目,它提供的fast upsert/delete以及compaction等功能可以说是精准命中广大人民群众的痛点,加上项目各成员积极地社区建设,包括技术细节分享、国内社区推广等等。
九、总结
数据湖在概念层还是有些模糊、混乱,缺少一系列标准化的、完善的定义。在实现方面也不是很成熟,缺少丰富的工具和生态圈。现阶段还在演变发展过程中,目前也能解决一些大数据问题。
十、参考文献
-
https://zhuanlan.zhihu.com/p/87795611
-
https://aws.amazon.com/cn/big-data/datalakes-and-analytics/what-is-a-data-lake/
-
https://www.jianshu.com/p/dc510ec49f53