一、环境
- 系统: Ubuntu 14.04 64bit
- Hadoop版本: hadoop 2.4.1 (stable)
- JDK版本: OpenJDK 7
- 集群环境: 4台主机,1台作为Master,另3台作为Slave。
所有主机的用户名都为hadoop,密码为123456.
二、网络主机配置
- 配置主机名和局域网IP
主机名与局域网IP地址对应如下:
主机名 | 局域网IP |
Master | 115.156.236.178 |
Slave1 | 115.156.236.199 |
Slave2 | 115.156.236.189 |
Slave3 | 115.156.236.215 |
- 修改主机名
首先选定哪台主机要作为Master(比如ip为 192.168.1.178 这台),然后在该主机的 /etc/hostname 中,修改机器名为Master,将其他主机命名为Slave1、Slave2、Slave3等。
sudo vi /etc/hostname
- 修改hosts
接着在 /etc/hosts中,把所有集群的主机信息都写进去。
sudo vi /etc/hosts

注意,该网络配置需要在所有主机上进行。
- 测试能否互相ping通
配置好后可以在各个主机上执行ping Master和ping Slave1测试一下,看是否相互ping通。

三、安装JDK
- 到官网下载Linux x64:
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
将jdk-7u79-linux-x64.tar.gz解压至/home/hadoop目录下
tar zxvf jdk-7u79-linux-x64.tar.gz –C /home/hadoop
- 编辑环境变量:
sudo vi /etc/profile
在里面添加如下内容

- 使配置生效:
source /etc/profile
- 测试:
java –version

四、SSH无密码登陆节点
- 安装ssh
sudo apt-get install openssh-server
如果无法正常安装,先试着执行下面的语句:
sudo apt-get update
- 编辑环境变量
sudo vi /etc/profile
修改后如下所示:

使配置生效:
source /etc/profile
- 配置namenode的ssh无密码自动登录
这个操作是要让Master节点可以无密码SSH登陆到Slave节点上。
首先生成 Master 的公匙,在 Master 节点终端中执行:
su hadoop
cd /home/hadoop
ssh-keygen –t rsa #生成公钥和私钥,一路回车
完成后会在/home/hadoop/目录下产生完全隐藏的文件夹.ssh。
然后执行:
cd .ssh # 进入.ssh目录
cp id_rsa.pub authorized_keys #生成authorized_keys文件
ssh localhost #测试无密码登陆
- 配置Master无密码访问Slave1、Slave2和Slave3
(1)将公钥传输到Slave1节点:
scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
scp时会要求输入Slave1上hadoop用户的密码(123456),输入完成后会提示传输完毕。
(2)接着在 Slave1节点上将ssh公匙保存到相应位置:
cp id_rsa.pub authorized_keys
(3)对其他的Slave节点,也要执行 将公匙传输到Slave节点、在Slave节点上保存到相应位置 这两步。
(4)最后在 Master 节点上就可以无密码SSH到Slave1节点了。
ssh Slave1

五、配置Hadoop
将hadoop-2.4.1.tar.gz保存至/home/Hadoop,然后解压:
tar zxvf jdk-7u79-linux-x64.tar.gz
- Master节点配置Hadoop
集群/分布式模式需要修改 etc/hadoop 中的6个配置文件, hadoop-env.sh 、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
(1)文件hadoop-env.sh
配置jdk,添加下面一行:
export JAVA_HOME=/home/hadoop/jdk1.7.0_79
(2)文件slaves
将原来 localhost 删除,把所有Slave的主机名写上,每行一个。例如我有3个 Slave节点,那么该文件中就有3行内容:
Slave1
Slave2
Slave3
(3)文件core-site.xml,修改如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop/tmp</value>
<description>Abase for other temporary directories. </description>
</property>
</configuration>
(4)文件hdfs-site.xml,因为有3个Slave,所以dfs.replication的值设为3。
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
(5)文件mapred-site.xml,这个文件不存在,首先需要从模板中复制一份:
cp mapred-site.xml.template mapred-site.xml
然后配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(6)文件yarn-site.xml:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 将Hadoop复制到Slave节点
配置好后,将 Master 上的 Hadoop 文件复制到各个节点上(虽然直接采用 scp 复制也可以正确运行,但会有所不同,如符号链接 scp 过去后就有点不一样了。所以先打包再复制比较稳妥)。
(1)在Master执行:
cd /home/hadoop
sudo tar -zcf ./hadoop.tar.gz ./hadoop
scp ./hadoop.tar.gz Slave1:/home/hadoop
(2)在Slave1上执行:
sudo tar -zxf ~/hadoop.tar.gz -C /home/hadoop
sudo chown -R hadoop:hadoop /home/hadoop/hadoop
(3)然后在Master节点上就可以启动hadoop了。
cd ~/hadoop
bin/hdfs namenode -format # 首次运行需要执行初始化,后面不再需要
启动Hadoop集群:
sbin/start-dfs.sh
sbin/start-yarn.sh
- 查看进程
在Master节点通过jps查看Master的Hadoop进程:

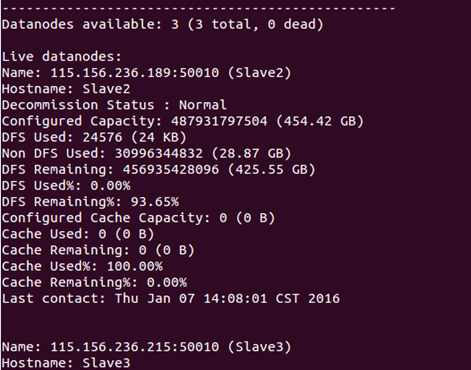
在Master节点上查看DataNode是否正常启动:
bin/hdfs dfsadmin -report
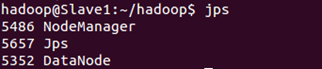
在Slave节点上通过jps查看Slave的Hadoop进程:
jps
也可以通过Web页面看到查看DataNode和NameNode的状态:
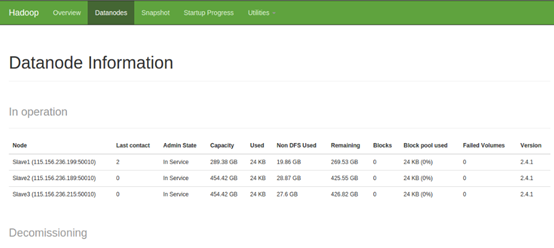
- 关闭Hadoop集群也是在Master节点上执行:
sbin/stop-dfs.sh
sbin/stop-yarn.sh
- 几个可能遇到的问题
(1)无法启动DataNode?
所以如果集群以前能启动,但后来启动不了,特别是 DataNode 无法启动,不妨试着删除所有节点(包括 Slave 节点)上的 tmp 文件夹:
rm -rf ~/Hadoop/tmp
bin/hdfs namenode –format
sbin/start-dfs.sh
sbin/start-yarn.sh
(2)ID不一致导致HDFS无法启动?
这个问题一般是由于两次或两次以上的格式化NameNode造成的,有两种方法可以解决,第一种方法是删除DataNode的所有资料;第二种方法是修改每个DataNode的namespaceID(位于/dfs/data/current/VERSION文件中)或修改NameNode的namespaceID(位于/dfs/name/current/VERSION文件中),使其一致。
(3)如何重启DataNode?
当Hadoop集群的某单个节点出现问题时,一般不必重启整个系统,只须重启这个节点,它会自动连入整个集群。
sbin/hadoop-daemon.sh start datanode
参考文献
http://www.linuxidc.com/Linux/2015-02/113486.htm
http://www.linuxidc.com/Linux/2013-09/90600.htm