标准IO库提供缓冲的目的是尽可能减少使用read和write调用的次数,降低执行IO的时间,它提供三种类型的缓冲:
- 全缓冲。在填满标准IO缓冲区4096Bytes后(缓冲区已满)才进行实际IO操作(通过write系统调用,将数据传递到内核高速缓冲区,最终内核将数据写入磁盘),对于磁盘文件通常就是全缓冲,上面的示例就是采用缓冲。
- 行缓冲。在输入和输出中遇到换行符时(缓冲区已满)进行实际的IO操作(通过write系统调用,将数据传递到内核高速缓冲区,最终内核将数据写入磁盘),当涉及到一个终端时,通常使用行缓冲。使用最频繁的printf函数就是采用行缓冲,所以感觉不出缓冲的存在。
- 不带缓冲。标准IO库不对字符进行缓冲存储。标准出错流stderr通常是不带缓冲的。
补充一下知识点:
read()和write()系统调用在操作磁盘文件时不会直接发起磁盘请求,而是仅仅在用户空间缓冲区与内核缓冲区高速缓存之间复制数据。例如下面调用将3个字节的数据从用户空间内存传递到内核空间的缓冲区中。
write(fd,"abc",3);
write()随机返回。在后续某个时刻,内核会将其缓冲区中的数据写入(刷新至)磁盘。(因此,可以说系统调用与磁盘操作并不同步)
与此同理,对输入而言,内核从磁盘中读取数据并存储到内核缓冲区中。read()调用将从该缓冲区中读取数据,直至把缓冲区中的数据读完,这时,内核会将文件的下一段内容读入缓冲区高速缓存。
这样设计,使得read()和write()很快,不需要等待(缓慢的)磁盘操作。同时,这一设计也极为高效,因为这减少了内核必须执行的磁盘传输次数。(预读和满写)
两句话:
1.read()和write()负责在用户空间缓冲区和内核高速缓冲区高速缓存复制数据。
2.内核负责从磁盘读数据到内核高速缓冲区(预读),以及当内核高速缓冲区满了,写到磁盘中去(满写)。
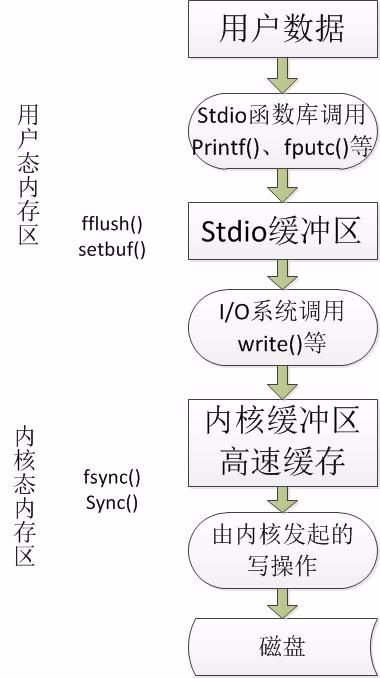
自 上而下,首先是通过stdio库将用户数据传递到stdio缓冲区(一般是4096Bytes,或者也可以有标准IO自动分配),该缓冲区位于用户态内存 区。当缓冲区满时(行缓冲遇到‘ ',全缓冲满4096Bytes),stdio库会调用write()系统调用,将数据传递到内核高速缓冲区(位于内 核态内存区)。最终,内核发起磁盘操作,将数据传递到磁盘。
使用fflush()强制刷新stdio缓冲区(通过write()调用),将数据传递到内核高速缓冲区中。
fsync() syn()系统调用将使缓冲数据和与打开文件描述符fd相关的所有元数据都刷新到磁盘上。
首先要明白不带缓冲的概念:所谓不带缓冲,并不是指内核不提供缓冲,而是只单
纯的系统调用,不是函数库的调用。系统内核对磁盘的读写都会提供一个块缓冲,当用write函数对其写数据时,直接调用系统调用,将数据写入到块缓冲进行
排队,当块缓冲达到一定的量时,才会把数据写入磁盘。因此所谓的不带缓冲的I/O是指进程不提供缓冲功能。每调用一次write或read函数,直接系统
调用。
而带缓冲的I/O是指进程对输入输出流进行了改进,提供了一个流缓冲,当用fwrite函数网磁盘写数据时,先把数据写入流缓冲区中,当达到一定条件,比如流缓冲区满了,或刷新流缓冲,这时候才会把数据一次送往内核提供的块缓冲,再经块缓冲写入磁盘。
因此,带缓冲的I/O在往磁盘写入相同的数据量时,会比不带缓冲的I/O调用系统调用的次数要少。
自 上而下,首先是通过stdio库将用户数据传递到stdio缓冲区(一般是4096Bytes,或者也可以有标准IO自动分配),该缓冲区位于用户态内存 区。当缓冲区满时(行缓冲遇到‘ ',全缓冲满4096Bytes),stdio库会调用write()系统调用,将数据传递到内核高速缓冲区(位于内 核态内存区)。最终,内核发起磁盘操作,将数据传递到磁盘。
使用fflush()强制刷新stdio缓冲区(通过write()调用),将数据传递到内核高速缓冲区中。
fsync() syn()系统调用将使缓冲数据和与打开文件描述符fd相关的所有元数据都刷新到磁盘上。
首先要明白不带缓冲的概念:所谓不带缓冲,并不是指内核不提供缓冲,而是只单
纯的系统调用,不是函数库的调用。系统内核对磁盘的读写都会提供一个块缓冲,当用write函数对其写数据时,直接调用系统调用,将数据写入到块缓冲进行
排队,当块缓冲达到一定的量时,才会把数据写入磁盘。因此所谓的不带缓冲的I/O是指进程不提供缓冲功能。每调用一次write或read函数,直接系统
调用。
而带缓冲的I/O是指进程对输入输出流进行了改进,提供了一个流缓冲,当用fwrite函数网磁盘写数据时,先把数据写入流缓冲区中,当达到一定条件,比如流缓冲区满了,或刷新流缓冲,这时候才会把数据一次送往内核提供的块缓冲,再经块缓冲写入磁盘。
因此,带缓冲的I/O在往磁盘写入相同的数据量时,会比不带缓冲的I/O调用系统调用的次数要少。
但是差别在read每次读的数据是调用者要求的大小,比如调 用要求读取10个字节数据,read就会读10个字节数据到数组中,而fread不一样,为了加快读的速度,fread每次都会读比要求更多的数据,然后 放到缓冲区中,这样下次再读数据只需要到缓冲区中去取就可以了。
fread每次会读取一个缓冲区大小的数据,32位下一般是4096个字节,相当于调用了read(fd,buf,4096)
for(i=0; i<4; ++i)
read(fd,buf,128)
一共有4次系统调用
而fread一次就读取了4096字节放到缓冲区了,所以省事了
fgetc读一个字节,fgetc有可能从内核中预读1024个字节到I/O缓冲区中,再返回第一个字节,这时该文件在内核中记录的读写位置是1024,而在FILE结构体中记录的读写位置是1
#include<unistd.h>#include<stdlib.h>int main(){char buf[10];int n;n=read(STDIN_FILENO,buf,10);if(n<0){perror("read stdin_fileno");exit(0);}write(STDOUT_FILENO,buf,n);return 0;}
[root@localhost test]# ./a.outhello world //从键盘输入hello worl[root@localhost test]# dbash: d: command not found- Shell进程创建
a.out进程,a.out进程开始执行,而Shell进程睡眠等待a.out进程退出。a.out调用read时睡眠等待,直到终端设备输入了换行符才从read返回,read只读走10个字符,剩下的字符仍然保存在内核的终端设备输入缓冲区中a.out进程打印并退出,这时Shell进程恢复运行,Shell继续从终端读取用户输入的命令,于是读走了终端设备输入缓冲区中剩下的字符d和换行符,把它当成一条命令解释执行,结果发现执行不了,没有d这个命令。