HDFS简介
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,适合那些有着超大数据集(large data set)的应用程序。
HDFS基本概念篇
设计思想:分而治之:将大文件、大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析;
在大数据系统中作用:为各类分布式运算框架(如:mapreduce,spark,tez等)提供数据存储服务。
HDFS的概念和特性
一个分布式文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件。
Hadoop 3个核心组件:
分布式文件系统:Hdfs——实现将文件分布式存储在很多的服务器上(hdfs是一个基于Linux本地文件系统上的文件系统)
分布式运算编程框架:MapReduce——实现在很多机器上分布式并行运算
分布式资源调度平台:Yarn——帮用户调度大量的mapreduce程序,并合理分配运算资源
MapReduce:通俗说MapReduce是一套从海量源数据提取分析元素最后返回结果集的编程模型,将文件分布式存储到硬盘是第一步,而从海量数据中提取分析我们需要的内容就是MapReduce做的事了。
MapReduce的基本原理就是:将大的数据分析分成小块逐个分析,最后再将提取出来的数据汇总分析,最终获得我们想要的内容。当然怎么分块分析,怎么做Reduce操作非常复杂,Hadoop已经提供了数据分析的实现,我们只需要编写简单的需求命令即可达成我们想要的数据。
HDFS的设计特点是:
1、大数据文件,非常适合上T级别的大文件或者一堆大数据文件的存储,如果文件只有几个G甚至更小就没啥意思了。
2、文件分块存储,HDFS会将一个完整的大文件平均分块存储到不同计算器上,它的意义在于读取文件时可以同时从多个主机取不同区块的文件,多主机读取比单主机读取效率要高得多得多。
3、流式数据访问,一次写入多次读写,这种模式跟传统文件不同,它不支持动态改变文件内容,而是要求让文件一次写入就不做变化,要变化也只能在文件末添加内容。
4、廉价硬件,HDFS可以应用在普通PC机上,这种机制能够让给一些公司用几十台廉价的计算机就可以撑起一个大数据集群。
5、硬件故障,HDFS认为所有计算机都可能会出问题,为了防止某个主机失效读取不到该主机的块文件,它将同一个文件块副本分配到其它某几个主机上,如果其中一台主机失效,可以迅速找另一块副本取文件。
重要特性:
1.HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
2.HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件
3.目录结构及文件分块信息(元数据)的管理由namenode节点承担——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
4.文件的各个block的存储管理由datanode节点承担----datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
5.HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
HDFS的关键元素:
1、Block:将一个文件进行分块,通过配置参数( dfs.blocksize)来设置,hadoop2.x版本中是128M,老版本中是64M。
2、NameNode:保存整个文件系统的目录信息、文件信息及分块信息,这是由唯一一台主机专门保存,当然这台主机如果出错,NameNode就失效了。在 Hadoop2.* 开始支持 activity-standy 模式----如果主 NameNode 失效,启动备用主机运行NameNode。
3、DataNode:分布在廉价的计算机上,用于存储Block块文件。
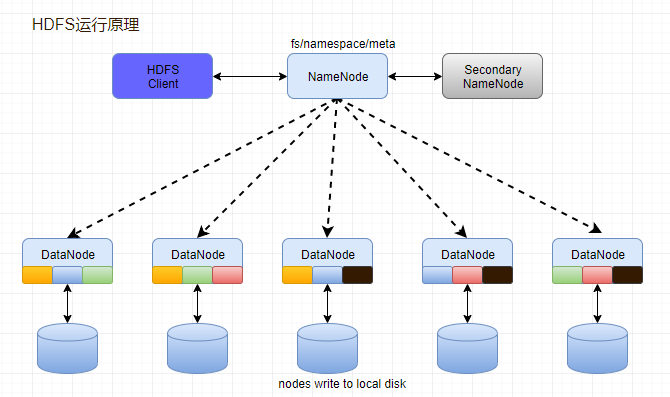
一、HDFS运行原理
1、NameNode和DataNode节点初始化完成后,采用RPC进行信息交换,采用的机制是心跳机制,即DataNode节点定时向NameNode反馈状态信息,反馈信息如:是否正常、磁盘空间大小、资源消耗情况等信息,以确保NameNode知道DataNode的情况;
2、NameNode会将子节点的相关元数据信息缓存在内存中,对于文件与Block块的信息会通过fsImage和edits文件方式持久化在磁盘上,以确保NameNode知道文件各个块的相关信息;
3、NameNode负责存储fsImage和edits元数据信息,但fsImage和edits元数据文件需要定期进行合并,这时则由SecondNameNode进程对fsImage和edits文件进行定期合并,合并好的文件再交给NameNode存储。
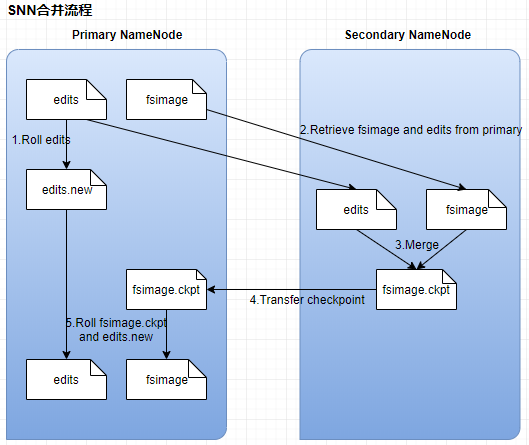
二、HDFS数据合并原理
1、NameNode初始化时会产生一个edits文件和一个fsimage文件,edits文件用于记录操作日志,比如文件的删除或添加等操作信息,fsImage用于存储文件与目录对应的信息以及edits合并进来的信息,即相当于fsimage文件在这里是一个总的元数据文件,记录着所有的信息;
2、随着edits文件不断增大,当达到设定的一个阀值的时候,这时SecondaryNameNode会将edits文件和fsImage文件通过采用http的方式进行复制到SecondaryNameNode下,同时NameNode会产生一个新的edits文件替换掉旧的edits文件,这样以保证数据不会出现冗余;
3、SecondaryNameNode拿到这两个文件后,会在内存中进行合并成一个fsImage.ckpt的文件,合并完成后,再通过http的方式将合并后的文件fsImage.ckpt复制到NameNode下,NameNode文件拿到fsImage.ckpt文件后,会将旧的fsimage文件替换掉,并且改名成fsimage文件。
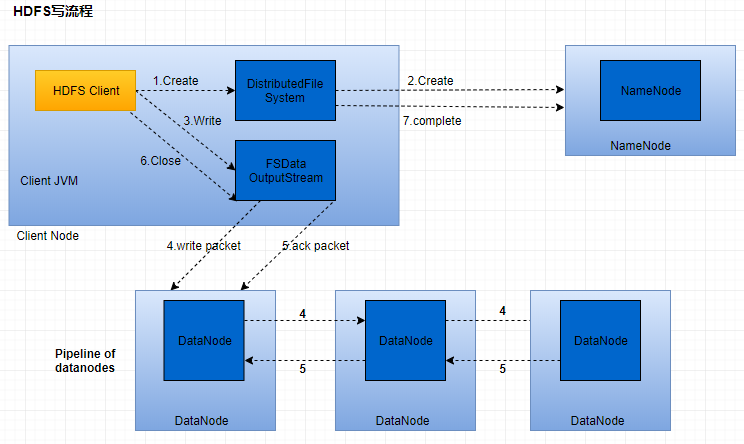
三、HDFS写原理
1、HDFS客户端提交写操作到NameNode上,NameNode收到客户端提交的请求后,会先判断此客户端在此目录下是否有写权限,如果有,然后进行查看,看哪几个DataNode适合存放,再给客户端返回存放数据块的节点信息,即告诉客户端可以把文件存放到相关的DataNode节点下;
2、客户端拿到数据存放节点位置信息后,会和对应的DataNode节点进行直接交互,进行数据写入,由于数据块具有副本replication,在数据写入时采用的方式是先写第一个副本,写完后再从第一个副本的节点将数据拷贝到其它节点,依次类推,直到所有副本都写完了,才算数据成功写入到HDFS上,副本写入采用的是串行,每个副本写的过程中都会逐级向上反馈写进度,以保证实时知道副本的写入情况;
3、随着所有副本写完后,客户端会收到数据节点反馈回来的一个成功状态,成功结束后,关闭与数据节点交互的通道,并反馈状态给NameNode,告诉NameNode文件已成功写入到对应的DataNode。
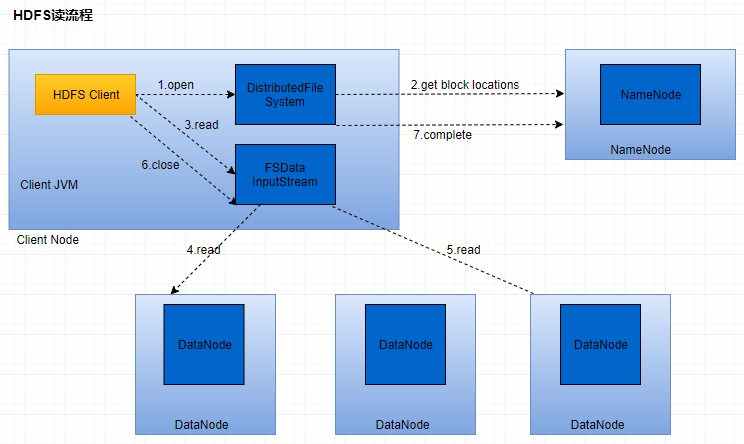
四、HDFS读原理
1、HDFS客户端提交读操作到NameNode上,NameNode收到客户端提交的请求后,会先判断此客户端在此目录下是否有读权限,如果有,则给客户端返回存放数据块的节点信息,即告诉客户端可以到相关的DataNode节点下去读取数据块;
2、客户端拿到块位置信息后,会去和相关的DataNode直接构建读取通道,读取数据块,当所有数据块都读取完成后关闭通道,并给NameNode返回状态信息,告诉NameNode已经读取完毕。
备注:
作者:Shengming Zeng
博客:http://www.cnblogs.com/zengming/
本文是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接。
<欢迎有不同想法或见解的同学一起探讨,共同进步>