一 storm起源
storm作为一个流式处理框架,它与hadoop的根本区别在于hadoop的输入不是持续的,而storm的输入是持续的。storm是一个开源的,分布式的流式的计算系统。随着有些公司数据量增长非常快和和数据量特别大就出现了分布式的需要,把一个计算任务拆解成多个计算机同时运行。Google发表的三篇论文,Google File System,BigTable,MapReduce奠定了分布式的理论基础,原Yahoo的Doug Cutting根据这些学术论文研究出hadoop。基于hadoop改造的系统就如雨后春笋般的出现了,HBase,Drill,Hive,Tez,Pig,Dremel,Mahout,等形成了一整套生态系统。 但是hadoop只适用于批处理,不适用于流式处理,流式处理有时候是非常必须和重要的,批处理往往需要收集一部分时间数据然后在计算,流式处理是相对动态的,比如用户出广告费使他的搜索靠前,如果第二名出不了这么多钱,就可以恶意点击位于他前面的广告商使费用很快用完,如果批处理hadoop就可能招来广告商的埋怨,如果用流式处理框架就可以比较实时的计算是不是恶意点击。于是就产生了分布式流式计算系统,比较有名的有流失系统有Yahoo的S4,IBM的StreamBase,Amazon的kinesis,Spark的Streaming,Google的Millwheel .
批量计算和流式计算的比较:

Storm的很大一部分实现都是Clojure代码。同时storm在设计之初就考虑到了兼容多语言开发。Nimbus是一个thrift服务,topologies被定义为Thrift结构体。Thrift的运用使得Storm可以被任意开发语言使用。
二 storm组件
Storm的术语包括Stream、Spout、Bolt、Task、Worker、Stream Grouping和Topology。
Storm的一个作业是一个拓扑--Topology,包含了许多数据节点和计算节点,以及这些节点之间的边,数据源节点称为spout,计算节点称为bolt,点之间的边称为Stream,数据流中的每一条记录称为tuple。拓扑的每个节点都要说明它所发射出的元组的字段的name,其他节点只需要订阅该name就可以接收处理。
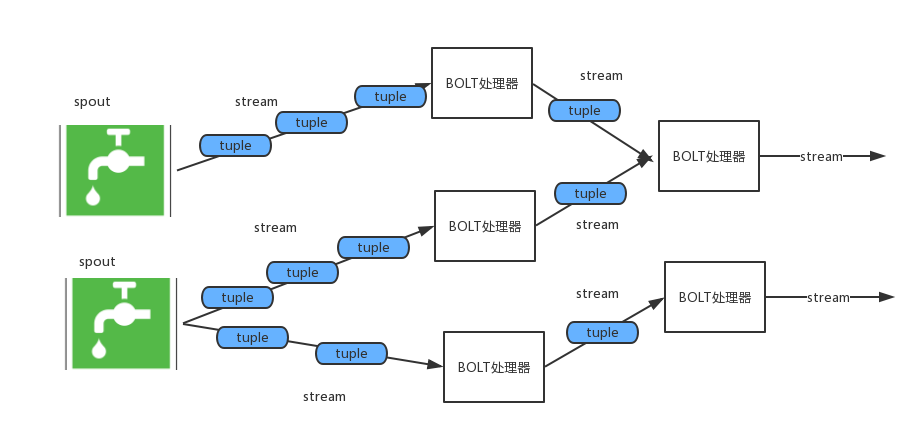
Topology
在storm上需要你自己去定义和建立topology,从而进行实时的计算。topoloy里面的每一个节点都是并行运行的,它会一直永久运行,直到你显示的关闭进程。topology的定义是thrift结构并且nimbus是一个thrift服务,可以用其它语言创建并且提交topology.如果是java可以使用TopologyBuilder定义拓扑,并且指定spout和bolt和分组方式,可以使用stormsubmitter向集群提交拓扑名称,拓扑配置信息和本身的topology作为参数运行一个拓扑。可以使用storm kill {topologyname}来停止一个拓扑,其中 topologyname 就是你提交拓扑时使用的拓扑名称。不过,在执行该命令后 Storm 不会马上 kill 掉该拓扑。Storm 会先停止所有 spouts 的活动,使得他们不能继续发送 tuple,然后 Storm 会等待 Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS 参数表示的一段时间,然后才会结束所有的 worker 进程。这可以保证拓扑在被 kill 之前可以有足够的时间完成已有的 tuple 的处理。
Streams
数据流式storm中最核心的抽象概念,指的是在分布式环境中并行创建、处理的一组元组(tuple)的无界序列。在声明数据流的时候可以定义一个有效的id。但是大部分都是单一数据流的,不需要ID进行区分, 可以直接使用OutputFieldsDeclarer 申明无id的数据流。实际上,系统默认会给这种数据流定义一个名为“default”的 id。
Spouts
spouts是拓扑中的数据源,负责读入数据。spouts可以定义为可靠的和不可靠的数据源,可靠的数据源可以在tuple发送失败的时候重新发送,不可靠的则不处理。nextTuple方法就是向拓扑中发送一个新的tuple.需要注意nextTuple方法不能被其它方法阻塞,否则会导致数据流的中断。(可参考阿里的JStorm)spouts还有两个比较重要的act和fail方法,只对可靠的spouts起作用,在发送tuple失败和成功时可做进一步处理。
Bolts
bolts是topology的计算节点,可以进行数据过滤,函数处理,聚合,联结,数据库交互等功能实现数据流的转化。你需要从其他的storm组件中订阅指定的数据流,并且在定义bolt的时候把注册相应的组件。对于申明默认id 的数据流,InputDeclarer的shuffleGrouping("1") 与shuffleGrouping("1", DEFAULT_STREAM_ID) 两种声明方式是等价的,都是订阅来自组件“1”的数据流。bolt也可以定义多个数据流,可以通过OutputFieldsDeclarer的declareStream方法来申明定义不同的数据源,然后发送数据时在outputCollector的emit方法中将数据流id作为参数来实现数据发送的功能。Bolt的execute方法负责接受一个元祖作为一个输入,并且使用outputCollector对象发送新的元组。如果有消息可靠性保障的需求,Bolt必须为它所处理的每个元组调用OutputCollector的 ack 方法,以便Storm能够了解元组是否处理完成。
Tuple
tuple也叫元组,是数据流中的一个基本处理单元,可以由Integer,Long,Short,Byte,Double,Float,Boolean,Char基本类型、字符串、字节数组、ArrayList、HashMap、HashSet 以及 Clojure 的集合类型的序列化。如果你需要在 tuple 中使用其他的对象类型,你就需要注册一个自定义的序列化器。如果 Storm 发现了一个没有注册序列化器的类型,它会使用 Java 自带的序列化器。如果这个对象无法序列化,Storm 就会抛出异常。Java 自身的序列化机制非常耗费资源,而且不管在 CPU 的性能上或者序列化对象的大小上都没有优势。建议在生产环境中运行拓扑的时候注册一个自定义的序列化器。
Tasks和Workers
tasks是线程级别的,而workers是进程级别的,每个工作进程即Worker是一个实际的JVM进程,tasks和workers都是执行topology中的spout和bolt.可以通过topologyBuilder的setSpout 方法和 setBolt 方法中设置相应 的并行度。比如,topology的并行度定义为100,workers数量为20,那么每个worker就会有6个tasks任务。
Stream Grouping
随机分组(Shuffle grouping):元组会被随机地分配到 Bolt 的不同任务(tasks)中,尽可能使得每个任务所处理元组数量保持基本相同。
域分组(Fields grouping):数据流根据定义的“域”来进行分组。比如可以基于一个名为“id”的域进行分组,包含相同的“id”的元组会分配到同一个任务中。
部分关键字分组(Partial Key grouping):这种方式与域分组很相似,根据定义的域来对数据流进行分组,不同的是,这种方式会考虑下游 Bolt 数据处理的均衡性问题,在输入数据源关键字不平衡时会有更好的性能1。感兴趣的读者可以参考这篇论文,其中详细解释了这种分组方式的工作原理以及它的优点。
完全分组(All grouping):相当于广播方式,同一个元组会被复制多份然后被所有的任务处理。
全局分组(Global grouping):这种方式下所有的数据流都会被发送到 Bolt 的同一个任务中,也就是 id 最小的那个任务。
非分组(None grouping):目前和随机分组等效。
直接分组(Direct grouping):元组的发送者可以指定下游的哪个任务可以接收这个元组。只有在数据流被声明为直接数据流时才能够使用直接分组方式。使用直接数据流发送元组需要使用OutputCollector 的其中一个 emitDirect 方法。Bolt 可以通过 TopologyContext 来获取它的下游消费者的任务 id,也可以通过跟踪 OutputCollector 的 emit 方法(该方法会返回它所发送元组的目标任务的 id)的数据来获取任务 id。
本地或随机分组(Local or shuffle grouping):如果在源组件的 worker 进程里目标 Bolt 有一个或更多的任务线程,元组会被随机分配到那些同进程的任务中。换句话说,这与随机分组的方式具有相似的效果。
三 Storm的可用性
storm集群
采用主从结构,主节点称为Nimbus,管理整个集群的运行状态,从节点称为Supervisor,维护每一台机器的状态。
worker 挂掉
supervisor 会重新启动工作进程。如果仍然一直失败,在一定时间内无法向 Nimbus 发送心跳,Nimbus 就会将这个任务重新分配到其他的worker上面。
非主节点故障
非主节点发生故障时,该节点上所有的任务(tasks)都会超时,然后 Nimbus 在检测到超时后会将所有的这些任务重新分配到其他机器上去。
Nimbus 或者 Supervisor进程挂掉
Zookeeper管理着Nimbus和Supervisor后台进程的状态,Niubus和Supervisor的后台进程会在监控工具的监控下运行,如果挂掉,会静默的自动启动。 与Hadoop不同,JobTracker的故障会导致所有正在运行的job是失败,Nimbus或者supervisor不会影响任何的工作进程。
Nimbus单点故障
Nimbus节点故障会导致worker进程不会在必要的时候重新分配到不同的机器中,看上去好像丢失了一个worker,这就是唯一的影响,此外,集群中的worker仍然会继续运行,supervisor也会监控并且启动正在运行的机器。
storm在zookeeper中的结构(资料来源:http://segmentfault.com/a/1190000000653595)
/-{storm-zk-root} -- storm在zookeeper上的根目录(默认为/storm)
|
|-/assignments -- topology的任务分配信息
| |
| |-/{topology-id} -- 这个目录保存的是每个topology的assignments信息包括:对应的nimbus上
| -- 的代码目录,所有task的启动时间,每个task与机器、端口的映射。操作为
| -- (assignments)来获取所有assignments的值;以及(assignment-info storm-id)
| -- 来得到给定的storm-id对应的AssignmentInfo信息
| -- 在AssignmentInfo中存储的内容有:
| -- :executor->node+port :executor->start-time-secs :node->host
| -- 具体定义在common.clj中的
| -- (defrecord Assignment[master-code-dir node->host executor->node+port executor->start-time-secs])
|
|-/storms -- 这个目录保存所有正在运行的topology的id
| |
| |
| |-/{topology-id} -- 这个文件保存这个topology的一些信息,包括topology的名字,topology开始运行
| -- 的时间以及这个topology的状态。操作(active-storms),获得当前路径活跃的下
| -- topology数据。保存的内容参考类StormBase;(storm-base storm-id)得到给定的
| -- storm-id下的StormBase数据,具体定义在common.clj中的
| -- (defrecord StormBase [storm-name launch-time-secs status num-workers component->executors])
|
|-/supervisors -- 这个目录保存所有的supervisor的心跳信息
| |
| |
| |-/{supervisor-id} -- 这个文件保存supervisor的心跳信息包括:心跳时间,主机名,这个supervisor上
| -- worker的端口号,运行时间(具体看SupervisorInfo类)。操作(supervisors)得到
| -- 所有的supervisors节点;(supervisor-info supervisor-id)得到给定的
| -- supervisor-id对应的SupervisorInfo信息;具体定义在common.clj中的
|
| -- (defrecord SupervisorInfo [time-secs hostname assignment-id used-ports meta scheduler-meta uptime-secs])
|
|-/workerbeats -- 所有worker的心跳
| |
| |-/{topology-id} -- 这个目录保存这个topology的所有的worker的心跳信息
| |
| |-/{supervisorId-port} -- worker的心跳信息,包括心跳的时间,worker运行时间以及一些统计信息
|
| -- 操作(heartbeat-storms)得到所有有心跳数据的topology,
| -- (get-worker-heartbeat storm-id node port)得到具体一个topology下
| -- 的某个worker(node:port)的心跳状况,
| -- (executor-beats storm-id executor->node+port)得到一个executor的心跳状况
|
|-/errors -- 所有产生的error信息
|
|-/{topology-id} -- 这个目录保存这个topology下面的错误信息。操作(error-topologies)得到出错
| -- 的topology;(errors storm-id component-id)得到
| -- 给定的storm-id component-id下的出错信息
|-/{component-id}