最近在温习Java集合部分,花了三天时间读完了ArrayList与LinkedList以及Vector部分的源码。之前都是停留在简单使用ArrayList的API,读完源码看完不少文章后总算是对原理方面有了较清楚的认知。这部分文章整理基本都是这么一个套路:简单概括,分析源码增删改查,总结成文。
Java容器源码(精品):
https://blog.csdn.net/panweiwei1994/article/details/76555359#commentBox
https://juejin.im/post/5afbff9451882542877353dd
ArrayList动态扩容分析:
https://blog.csdn.net/zymx14/article/details/78324464
接下来整理了下关于List集合校招常见的面试题目:
1.ArrayList与Vector的区别
相同点:
都实现了List接口,允许元素重复和为null值。
底层都是数组,我们可以按位置索引出某个元素
不同点:
ArrayList是非同步的,在线程上不安全而Vector集合给它的每个API都套上了synchronized,所以Vector线程上是安全的。
在添加元素实现扩容的时候,ArrayList集合存储空间是增长为原来的1.5倍。而Vecto集合是存储空间增加为原来的2倍
PS:其实不考虑线程问题,他两没啥区别。
2.往ArrayList集合加入一万条数据,应该怎么提高效率?
ArrayList的构造方法有三种。当数据量比较大,这里又已经明确是一万条了,我们应该在初始化的时候就给它设置好容量。
不然使用无参构造器初始容量只有10,后面要扩容,扩容又比较伤性能,因为涉及到数组的复制,将原来的数组复制到新的存储区域中去。
PS:ArrayList动态扩容是一个重点一定要理解好,附上传送门:https://blog.csdn.net/zymx14/article/details/78324464
3.ArrayList插入删除一定很慢吗?
做过测试,ArrayList要是一直使用add方法在尾部插入的话,当数据量非常大的时候,其效率是要比LinkedList快的。删除也是。
但是要是在头部插入就要比LinkedList效率低不少。
可见测试分析报告:https://juejin.im/post/5c00987de51d451aa843b67b
四:ArrayList的遍历和LinkedList遍历性能比较如何?
Arraylist遍历性能要好,无论是全部遍历还是遍历某个元素都是这样。它底层使用数组,适合使用for循环按下标寻址。而LinkedList底层使用双向链表,虽说它在遍历的时候会采取折半查找的策略来提升速度但还是比不上ArrayList的速度。
五:ArrayList是如何扩容的ArrayList是如何实现自动增加的?
如果是使用无参构造的话,初始容量是10,当超过了10个容量时,就需要扩容,每次扩容为之前的1.5倍。调用的是Arrays.copy(elementData,newCapacity)。所以扩容涉及到数组的复制和移动,我们应该避免扩容。在初始化的时候预估容量大小。
六:什么情况下你会使用ArrayList?什么时候你会选择LinkedList?
ArrayList底层使用数组,LinkedList底层使用双向链表。结合数据结构的特点可知,数组在空间上占用一片连续的内存空间,查询快。链表在增删操作只需要修改链表指针结点就可,增删快。
所以在查询使用较多时,选择ArrayList集合,增删使用较多时,选择LinkedList集合。
七:当传递ArrayList到某个方法中,或者某个方法返回ArrayList,什么时候要考虑安全隐患?如何修复安全违规这个问题呢?
把ArrayList当作参数传递到某个方法中去,涉及到一个浅拷贝深拷贝的问题。如果直接赋值给成员变量时,当成员变量发生改变时,其对应的传递过来的ArrayList也会改变
八:如何复制某个ArrayList到另一个ArrayList中去?
一般不直接用“=”赋值,这是将引用指向了同一片地址,一个修改了里面的内容另一个也会跟着变动。
一般采用如下方式:
ArrayList A = new ArrayList();
//假设此时A集合已经有了数据。构造器法 ArrayList B = new ArrayList(A);
//clone法
ArrayList A = new ArrayList(); ArrayList B = (ArrayList) A.clone();
ArrayList A = new ArrayList(); //初始化时最好先预估容量大小 ArrayList B = new ArrayList(); B.addAll(A);
还可以调用Collections.copy()方法,参考博客:https://blog.csdn.net/tiantiandjava/article/details/51072173
九:在索引中ArrayList的增加或者删除某个对象的运行过程?效率很低吗?解释一下为什么?
查看源代码可以发现,当通过索引去增删元素的时候效率是比较低的,因为要频繁的进行数组的复制和移动,如果经常增删的话我们可以去考虑其他的集合。
通过索引增加过程:1.检查索引是否越界?2.检查容量是否足够?3调用System.arrayCopy(......)操作,效率较低
通过索引删除元素:1.检查索引是否越界?2.调用System.arrayCopy(....)操作
源代码截图如下:
以上是常见的面试题:接下来总结一下自己看源码所学到的
ArrayList:
1.ArrayList继承了AbstractList类,实现了List接口,RadomAccess,Clonable,Serialize接口。结合List接口特点可知它是有序的,可以存储重复值且可以为null。实现了RadomAccess接口在加上它底层采用数组实现,所以遍历速度快且遍历方式推荐使用for循环遍历下标而不用for-each或者iterator迭代器遍历。

2.使用默认无参构造时,初始容量分配为10.当进行增操作时,容量不够会进行扩容操作。
理清ArrayList增删改查操作:
add(E e):数组末尾进行增。
1.判断容量是否足够
2.size++
由此可见在末尾进行增操作时,是偶尔需要进行一次扩容操作,扩容时候会调用Arrays.copyOf(elementData, newCapacity);也与上文所说的在末尾插入效率并不比LinkedList低
public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }
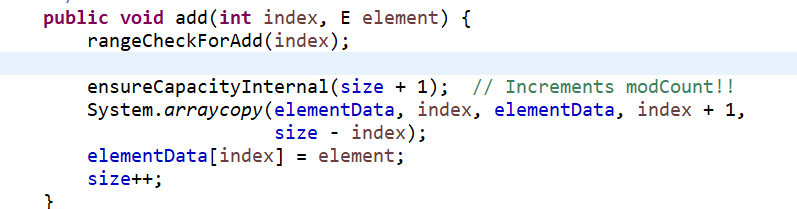
public void add(int index, E element):按索引增。可知按索引增每次都要进行数组复制,所以效率低
1.判断索引是否越界 2.判断容量是否足够 3.size++
public void add(int index, E element) { rangeCheckForAdd(index); ensureCapacityInternal(size + 1); // Increments modCount!! System.arraycopy(elementData, index, elementData, index + 1, size - index); elementData[index] = element; size++; }
public boolean addAll(Collection<? extends E> c):增加一个集合。
1.先将所要增加的集合转为数组 2.判断容量 3:size++
public boolean addAll(Collection<? extends E> c) { Object[] a = c.toArray(); int numNew = a.length; ensureCapacityInternal(size + numNew); // Increments modCount System.arraycopy(a, 0, elementData, size, numNew); size += numNew; return numNew != 0; }
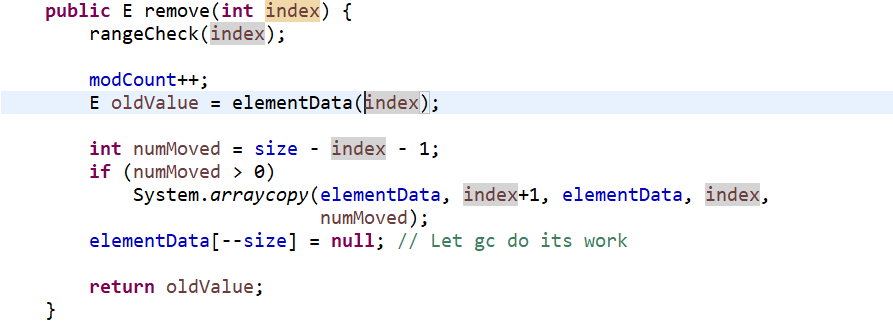
public E remove(int index):按索引值删除。可知每次都要进行数组复制,效率一样不高
public E remove(int index) { rangeCheck(index); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // Let gc do its work return oldValue; }
public boolean remove(Object o):按值删除 调用了fastRemove(index)方法,其内部也是要进行数组的复制,效率依然不高。
public boolean remove(Object o) { if (o == null) { for (int index = 0; index < size; index++) if (elementData[index] == null) { fastRemove(index); return true; } } else { for (int index = 0; index < size; index++) if (o.equals(elementData[index])) { fastRemove(index); return true; } } return false; }
LinkedList:
1.继承了AbstractSequentialList类,但AbstractSequentialList 只支持按次序访问,而不像 AbstractList 那样支持随机访问。这是LinkedList随机访问效率低的原因之一。
2.实现了List接口,说明有序,可以存储重复值,允许元素为null。实现了Deque接口,说明可以像操作栈和队列一样操作它。另外它还是可以被克隆和序列化的。

3.LinkedList底层是双向链表,链表在空间上是离散的,尽管Linked遍历时采用了折半查找,但效率依然较低。它的优势在于增删操作,尤其是在头结点。