说明
好消息,牛客网博客上线了,对于像这种干净整洁没有广告的博客(csdn你看看人家),我们当然要在第一时间欢迎了,作者大一投入csdn的怀抱,后来又自己买服务器建个人博客,最后的最后终于牛客网也上线了自己的博客,当然要支持了(听说前一百名还有杯子送哦)。但是由于项目刚上线,自然会有很多bug,最重要的一个居然是不断刷新文章,阅读量会蹭蹭蹭的往上涨,这可不得了了,于是写了个简单的爬虫玩了玩,代码也就几十行。这里用到的编程语言是java,使用了jsoup这个库。
也许随着bug的修复,本篇文章的内容已经无效。
分析
首先导入jsoup的maven坐标
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
然后分析,大致分为两步,第一步获取所有的文章的URL,第二步骤,创建线程不断地请求url,ok,开始写代码。
-
获取文章url
通过观察牛客网博客首页发现,博客文章居然没有分页,那么就可以直接拿到所有文章的url了。看看url在哪里呢。
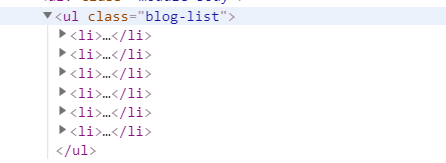
可以发现是在一个class为blog-list的ul标签中。每一个li标签代表一篇文章。
li标签内容如下:

链接地址就在li标签下的href属性中。
现在开始写代码
List<String> getAllArticleURLList(String blogUrl) throws IOException {
Document doc = Jsoup.connect(blogUrl)
.userAgent("Mozilla")
.get();
Element element=doc.select("ul.blog-list").first();
Elements li=element.getElementsByTag("li");
List<String> articleList=new LinkedList<String>();
for (Element e:li){
Elements elements=e.getElementsByTag("a");
articleList.add(elements.first().attr("href"));
}
return articleList;
}
这样我们就可以获取到所有的文章链接了,运行结果如下:
-
创建线程处理
拿到了所有的文章链接,下面是通过get方法不断对链接进行请求,但是由于网络请求是一件很耗资源的事情,所以我们需要通过多个线程来处理文章,这里最大线程为20个来进行处理。
先写一个类来处理刷阅读量的任务
class DealThread implements Runnable{ int num; DealThread(int num){ this.num=num; } @Override public void run() { while (true){ //获取目前可以处理的url int index=getNowDealIndex(); //如果处理完了就退出 if (index>=list.size()){ return; } String url=list.get(index); //每个url刷num次 for (int i=0;i<num;i++){ try { Jsoup.connect(url).userAgent("Mozilla").get(); } catch (IOException e) { e.printStackTrace(); } } } } }最后一步就是使用多线程线程来处理这些请求了,为了方便,本文就没有用到线程池了。
代码
package main;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.util.LinkedList;
import java.util.List;
import java.util.Scanner;
/**
* @author zeng
* @Classname NewCodeReader
* @Description TODO
* @Date 2019/7/28 15:35
*/
public class NewCodeReader {
private static final int THREAD_NUM=20;
private static int nowDealIndex=-1;
private static List<String> list;
synchronized static int getNowDealIndex(){
nowDealIndex+=1;
return nowDealIndex;
}
private static List<String> getAllArticleURLList(String blogUrl) throws IOException {
Document doc = Jsoup.connect(blogUrl)
.userAgent("Mozilla")
.get();
Element element=doc.select("ul.blog-list").first();
Elements li=element.getElementsByTag("li");
List<String> articleList=new LinkedList<String>();
for (Element e:li){
Elements elements=e.getElementsByTag("a");
articleList.add("https://blog.nowcoder.net"+elements.first().attr("href"));
}
return articleList;
}
public static void main(String[] args) throws IOException, InterruptedException {
System.out.println("请输入刷取的数量:");
Scanner scanner=new Scanner(System.in);
int num=scanner.nextInt();
System.out.println("开始获取博客列表...");
String blogUrl="https://blog.nowcoder.net/zengxianhui";
list=getAllArticleURLList(blogUrl);
System.out.println("共发现"+list.size()+"篇博客");
System.out.println("开始刷点击量...");
Thread[] threads=new Thread[THREAD_NUM];
for (int i=0;i<THREAD_NUM;i++){
Thread thread=new Thread(new DealThread(num));
thread.start();
threads[i]=thread;
}
for (Thread t:threads) {
t.join();
}
System.out.println("任务完成...");
}
static class DealThread implements Runnable{
int num;
DealThread(int num){
this.num=num;
}
@Override
public void run() {
while (true){
int index=getNowDealIndex();
if (index>=list.size()){
return;
}
String url=list.get(index);
for (int i=0;i<num;i++){
try {
Jsoup.connect(url).userAgent("Mozilla").get();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
}
最后
爬虫好玩,但是还不不道德的事情,看完本文大家可以尝试,但是也不要对牛客网后台服务器造成太大的压力。相信牛客官方很快就可以解决这个问题。