python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息
PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器。
用pyspider的demo页面创建了一个爬虫,写一个正则表达式抓取多牛网站上特定的URL,很容易就得到想要的结果了,可以非常方便分析抓取页面里面的内容
binux/pyspider · GitHub
https://github.com/binux/pyspider
http://docs.pyspider.org/en/latest/
Dashboard - pyspider
http://demo.pyspider.org/
ztest - Debugger - pyspider
http://demo.pyspider.org/debug/ztest
那个demo网站还可以直接在线保存自己创建编辑过的代码的
看了pyspider的源码web端是用tornado框架做的,使用 PhantomJS 渲染带 JS 的页面
首页 - Binuxの杂货铺
http://blog.binux.me/
这个是作者的中文博客,有中文的教程文章
=================================
先上直观的效果图:
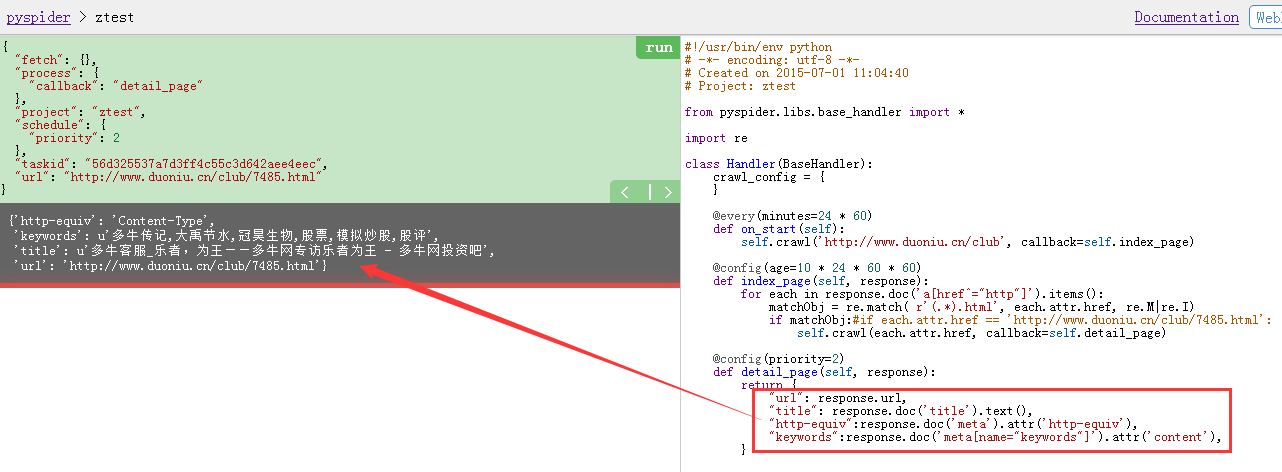

下面是相关代码:
#!/usr/bin/env python # -*- encoding: utf-8 -*- # Created on 2015-07-01 11:04:40 # Project: ztest from pyspider.libs.base_handler import * import re class Handler(BaseHandler): crawl_config = { } @every(minutes=24 * 60) def on_start(self): self.crawl('http://www.duoniu.cn/club', callback=self.index_page) @config(age=10 * 24 * 60 * 60) def index_page(self, response): for each in response.doc('a[href^="http"]').items(): matchObj = re.match( r'(.*).html', each.attr.href, re.M|re.I) if matchObj: self.crawl(each.attr.href, callback=self.detail_page) @config(priority=2) def detail_page(self, response): return { "url": response.url, "title": response.doc('title').text(), "http-equiv":response.doc('meta').attr('http-equiv'), "keywords":response.doc('meta[name="keywords"]').attr('content'), } =========================================== { "fetch": {}, "process": { "callback": "index_page" }, "project": "ztest", "schedule": { "age": 864000 }, "taskid": "0a7f73fcbef54f29761aeeff6cc2ab68", "url": "http://www.duoniu.cn/club/" } ============================================= { "fetch": {}, "process": { "callback": "detail_page" }, "project": "ztest", "schedule": { "priority": 2 }, "taskid": "56d325537a7d3ff4c55c3d642aee4eec", "url": "http://www.duoniu.cn/club/7485.html" } ================================================ {'http-equiv': 'Content-Type', 'keywords': u'多牛传记,大禹节水,冠昊生物,股票,模拟炒股,股评', 'title': u'多牛客服_乐者,为王——多牛网专访乐者为王 - 多牛网投资吧', 'url': 'http://www.duoniu.cn/club/7485.html'}
新增一个抓取政府新闻的代码:
1 #!/usr/bin/env python 2 # -*- encoding: utf-8 -*- 3 # Created on 2015-10-09 13:51:35 4 # Project: xinwen 5 #http://demo.pyspider.org/debug/xinwen 6 7 from pyspider.libs.base_handler import * 8 9 import re 10 11 class Handler(BaseHandler): 12 crawl_config = { 13 } 14 15 @every(minutes=24 * 60) 16 def on_start(self): 17 self.crawl('http://www.gov.cn/xinwen/', callback=self.index_page) 18 19 @config(age=10 * 24 * 60 * 60) 20 def index_page(self, response): 21 for each in response.doc('a[href^="http"]').items(): 22 matchObj = re.match( r'(.*).htm', each.attr.href, re.M|re.I) 23 if matchObj: 24 self.crawl(each.attr.href, callback=self.detail_page) 25 26 @config(priority=2) 27 def detail_page(self, response): 28 return { 29 "url": response.url, 30 "title": response.doc('title').text(), 31 "http-equiv":response.doc('meta').attr('http-equiv'), 32 "keywords":response.doc('meta[name="keywords"]').attr('content'), 33 }